






 BTC/HKD+0.01%
BTC/HKD+0.01% ETH/HKD-0.55%
ETH/HKD-0.55% LTC/HKD-0.39%
LTC/HKD-0.39% DOT/HKD-0.49%
DOT/HKD-0.49% ADA/HKD-0.78%
ADA/HKD-0.78% SOL/HKD-0.02%
SOL/HKD-0.02% XRP/HKD-0.83%
XRP/HKD-0.83% DOGE/US-0.1%
DOGE/US-0.1%3月22日,玩家和AI從業者們又愛又恨的老黃,帶著他的新“核彈”來了。遺憾的是,這次的新“核彈”與玩家沒有太大關系,主要是針對企業和工業市場,與玩家有關的RTX 40系估計最快也要等到9月份才會有消息。

好了,廢話不多說,讓我們看看老黃這次又拿了怎樣的“大寶貝”出來。首先是A100顯卡的接任者,新一代計算卡皇H100閃亮登場,H100采用全新的Hopper架構和臺積電最新的4nm工藝,各方面的參數對比上一代的A100都有明顯的提升。
英偉達的超級服務器芯片Grace也再度曝光,對比上一次給出的數據,此次曝光的Grace芯片性能有了驚人的提升,根據發布會的描述來看,英偉達似乎也走上與蘋果相同的道路,用更多的芯片拼裝成一顆處理器。
除了硬件方面的產品曝光和發布,英偉達在軟件領域同樣帶來了不少新東西,比如主打云端協作的Omniverse Cloud,讓多名用戶可以在云端直接參與同一個媒體文件的編輯和渲染等工作。
OpenAI、微軟、谷歌、蘋果、英偉達等將開會討論AI開發使用標準:4月11日消息,本周三,OpenAI、微軟、谷歌、蘋果、英偉達、Stability AI、Hugging Face、Anthropic等公司,將開會討論制定AI技術開發使用標準,討論如何以最負責任的態度繼續開發AI。(福克斯商業新聞)[2023/4/11 13:56:17]
此外英偉達還展示了不少基于虛擬現實環境的工業、交通模擬案例,還有一套由AI驅動的虛擬角色系統,該系統可以通過深度學習進行動作訓練,訓練結束后不需要額外的骨骼動作設計等操作就能夠依照指令做出對應動作,這下不僅是AI從業者狂喜,電影及游戲從業者也要狂喜。
不得不說,老黃這次帶來的東西并不少,每一樣都能對AI等行業的發展帶來明顯的改變,下面我們就來詳細的看看英偉達到底都發布了什么吧。
H100與Grace
實際上,從H100的核心規格來看,也不難理解為什么英偉達最終選了4nm,高達800億的晶體管集成度,比上一代A100多了整整260億個,內核數量則是提高到了16896個,這是目前世界上內核數量最高的芯片核心,同時也是上一代100的2.5倍。
英偉達對Arm的收購獲全球三大芯片巨頭支持:6月28日消息,據報道,英偉達400億美元收購Arm的提議獲得了推動,最近全球三大芯片制造商對這筆有爭議的交易表示了支持。Arm公司總部位于英國劍橋,英偉達對Arm發起的收購引發了人們對國家安全的關注。報道稱,博通、聯發科和Marvell成為了首批支持這比交易的Arm客戶。[2021/6/28 0:11:09]

夸張的內核參數提升帶來的性能提升也極為夸張,根據英偉達官方給出的數據,H100的浮點計算和張量核心運算能力將比上一代提升至少3倍,FP32高達60萬億次/秒,而上一代的A100為19.5萬億次/秒。
H100還將是首款支持PCIe 5.0和HBM3,讓內存帶寬達到驚人的3TB/s,老黃表示只需要20張H100就可以處理目前全球的網絡流量,雖然聽起來很夸張,但是確實體現出了H100夸張的性能參數。
英偉達:GeForce顯卡的價格可能會因新加密芯片而降低:英偉達表示:GeForce顯卡的價格可能會因新加密芯片而降低。[2021/6/2 23:04:04]
強大性能也伴隨著夸張的功耗,英偉達給出的H100功耗高達700W(真正意義上的“核彈”顯卡),作為對比上一代A100的功耗僅400W,不過用2倍的功耗換來3倍的性能提升,整體來說也不虧。
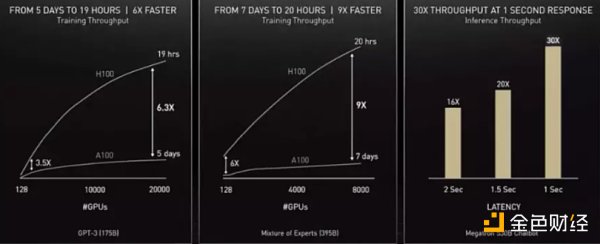
H100還針對AI訓練等所要用到的模型進行針對性優化,為Transformer搭載了優化引擎,讓大模型的訓練速度可以提升至原來的6倍,極大的降低了大型AI模型等訓練所需要的時間,這個特性也與下面將會談到的AI虛擬角色系統相呼應。
在英偉達給出的測試數據中,訓練一個擁有1750億參數的GPT-3模型,時間將由原來的一周降低到僅需19小時,而一個擁有3950億參數的Transforme模型也僅需21小時就可以完成訓練,效率提升近9倍。
礦工找到繞過“英偉達顯卡限制以太坊挖礦”的方法:3月10日消息,礦工找到一種使用自定義mod繞過“GeForce RTX 30系列顯卡限制以太坊挖礦”的方法。NVIDIA GeForce RTX 3060的傳輸速度約為40-45 MH / s,但是一旦在顯卡上開始挖掘,速度就會降至20-25 MH / s。該Mod有助于礦工釋放GeForce RTX 3060顯卡的全部散列潛力,最高可達50 MH / s。(WCCFtech)
此前消息,芯片巨頭英偉達(Nvidia)的高端顯卡RTX 3080 Ti和RTX 3070 Ti將配有以太坊挖礦限制功能,即顯卡算力不能全部用于挖礦。同時,英偉達未來生產的所有30系列高端顯卡,都將配置以太坊挖礦限制功能。[2021/3/10 18:32:57]
而且,H100還引入了英偉達最新的NVIDIA NVLink第四代互連技術,該技術能夠進一步提升多GPU串聯的效率,在英偉達給出的數據中,串聯后的I/O帶寬能夠擴展至900GB/s,比上一代提升了50%。
其中,Grace Hopper由一個Grace CPU和一個Hopper架構的GPU的GPU組成,兩者將會形成一個完整的運算系統,只需要一顆芯片就可以搭建出一個強大的運算服務器,同時也可以將多個芯片串聯起來組成更龐大的運算陣列。
聲音 | 英偉達股價下跌或與數字資產市場無關:據CCN分析,過去一周的一些報告表明,由于對加密挖礦的需求下降,英偉達(Nvidia)的股價也已經下跌。然而,正如許多分析師所暗示的那樣,英偉達的股價和收入下降可能與加密或數字資產市場的表現無關。今年8月,英偉達首席財務官Colette Kress曾告訴其投資者,預計加密部門不會對第三季度財報有任何貢獻。與此同時,美國股票市場處于快速上漲期,而英偉達的股價卻下跌超過5%。此外,包括Jim Cramer在內的分析師表示,英偉達的股價可能受到游戲芯片領域競爭加劇的影響。英偉達的加密貨幣挖礦GPU從未被認為是該公司業務的核心支柱之一,不太可能對公司的中期業績產生重大影響。[2018/12/29]

而Grace CPU超級芯片則是由兩顆Grace CPU組成,兩顆芯片通過NVIDIA NVLink-C2C技術互連,組成一個內置了144個Arm核心并且擁有1TB/s內存帶寬的巨無霸級芯片(Grace CPU Ultra?)。

說實話,英偉達的這顆Grace CPU超級芯片很難不讓人聯想到蘋果在春季發布會上發布的M1 Ultra,同樣是基于Arm架構,同樣是由兩顆芯片組合而成,同樣也有著夸張的內存帶寬和性能表現。
顯然,芯片互聯拼裝技術已經成為行業的趨勢之一,AMD方面也曝光有采用類似技術的CPU正在研發中,最早將在2023年與大家見面。只能說如今單顆芯片的性能發展已經接近極限,接下來想要擁有更大的提升,或許將不得不借助類似的互聯技術進行芯片堆疊了。
不過,Grace CPU超級芯片的功耗并不低,英偉達官方給出的數據是500W,已經遠遠超過了傳統的x86架構CPU,當然,考慮到Grace CPU超級芯片的夸張性能:SPECrate跑分740分,較第二名提升60%,這個功耗也不是不能接受。
顯然,在Arm服務器領域,英偉達的野心是非常大的。
英偉達的虛擬世界
除了一堆高性能的硬件,英偉達此次也展出了不少的軟件示范案例,其中就包括使用H100等硬件來模擬一個虛擬現實環境,用以進行各種測試和模擬。在英偉達的示范中,未來的企業可以通過強大的英偉達硬件構建一個擬真的虛擬測試環境,并在其中測試自動駕駛、智能工廠的運作等。
通過虛擬測試環境的使用,研究者可以更輕松的測試自動駕駛面對各種突發狀況時的反饋,并且在測試中直接定位問題,降低整體的測試成本。此外,還可以構建一個1:1的“數字化工廠”提前模擬運行,尋找提高效率和找到可能出現的問題,降低工廠正式運行后出現問題的概率。

英偉達將這一套應用稱為“數字孿生”,能夠大幅度降低自動化工廠和自動駕駛等方面的研究及測試投入。
Omniverse Cloud是英偉達新推出的一款云端創作服務,用戶通過Omniverse Cloud可以在任意地點訪問和編輯大型3D場景,并且無須等待大量數據的傳輸,并且還可以讓用戶能夠直接在線協作共同搭建3D模型。
在過去,3D模型和3D場景的協同構建都需要在一個服務器上進行,而在Omniverse Cloud推出后,相關創作者就可以通過任意支持Omniverse Cloud的終端,直接用網絡訪問協作空間并參與其中,極大的提升了創作者的響應速度和工作自由。
另外,英偉達還為創作者們準備了第二個驚喜,一套由AI驅動的虛擬角色系統,該系統可以讓AI在短時間內完成訓練,學會各種指令所對應的動作。比如一個簡單的劈砍動作,在正常的制作流程中首先需要動作架構師通過對動作骨架的一步步調整(俗稱K幀),然后再放到場景中進行測試,整個流程需要耗費大量的時間,而且每個不同的動作都需要重新進行調試。

而在這套AI虛擬角色系統的幫助下,當你想要虛擬模型做出劈砍的動作,只需要一條指令,AI就會從已學習的動作中找出關聯動作并自動運行,直接節省了大量的時間和人力,對于游戲開發者和特效制作者而言,這個系統將讓他們能夠將更多的精力放在其它地方。
英偉達的此次發布會,雖然并沒有太多的提到元宇宙,但是從硬件到軟件都是未來構建元宇宙的基礎。目前元宇宙無法成為現實的原因主要是兩點,一個是硬件性能無法滿足我們的需要,另一個就是軟件領域尚不成熟,無法提供實時的擬真環境模擬,而這兩者是點亮元宇宙科技的基礎。
在此之前,我們首先需要的就是更強大的計算硬件及更智能的AI系統。英偉達的H100,虛擬現實環境及AI虛擬角色系統的出現,將讓我們朝著真正的元宇宙再邁進一大步。
Tags:ACERACRACECPUSpaceBudzraca幣最新行情K線trace幣怎么樣門羅幣cpu算力表amd.e2.3200
大規模超金融化、反監管和人為稀缺的 web3 時代真的是馬克思主義的嗎?“ 我們現在都是凱恩斯主義者.
1900/1/1 0:00:003月22日,“國家工業設計研究院唯一藝術分院”揭牌儀式在唯一藝術杭州總部舉行。國家工業設計研究院院長應放天教授、浙江大學國際設計合作學院執行院長姚琤教授、國家工業設計研究院副院長萬然教授、唯一藝.
1900/1/1 0:00:00摘要:元宇宙是以數據和算力為依托,融合顯示技術、區塊鏈技術和人工智能技術于一體的,擁有獨立社交環境、全真體感和獨立經濟體系的相對獨立于現實世界的虛擬世界.
1900/1/1 0:00:00據 Jet Protocol 官方博客披露,他們近期修復了一個賞金漏洞,這個漏洞會導致惡意用戶可以提取任意用戶的存款資金,慢霧安全團隊對此漏洞進行了簡要分析,并將分析結果分享如下.
1900/1/1 0:00:00伴隨著全球用戶數及代幣價格的持續暴漲,主打“Move to Earn”(M2E)模式的STEPN成為GameFi賽道中的一匹黑馬,并成為圈內外玩家的“網紅打卡地”.
1900/1/1 0:00:00gas費之爭已經上演了很多年了,如今以太坊即將轉為pos鏈,那最大的期待,就是gas費可以降到很低,為什么呢?因為pos的處理效率遠大于pow,并且網絡資源成本也足夠低.
1900/1/1 0:00:00


