






 BTC/HKD-0.07%
BTC/HKD-0.07% ETH/HKD+0.11%
ETH/HKD+0.11% LTC/HKD+0.33%
LTC/HKD+0.33% DOT/HKD+1.89%
DOT/HKD+1.89% ADA/HKD+1.52%
ADA/HKD+1.52% SOL/HKD+1%
SOL/HKD+1% XRP/HKD+2.35%
XRP/HKD+2.35% DOGE/US+0.25%
DOGE/US+0.25%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
Binance將于6月12日15時對BNB Beacon Chain進行預計一小時的錢包維護:6月8日消息,據官方公告顯示,Binance 將于北京時間 6 月 12 日 15 時對 BNB Beacon Chain(BEP2)進行錢包維護,預計需要 1 小時時間。錢包維護期間,BNB Beacon Chain(BEP2)的數字資產/Token 交易將不受影響,Binance 將于 2023 年 06 月 12 日 14:55 暫停 BNB Beacon Chain(BEP2)的充值和提現業務。[2023/6/8 21:23:24]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
華為版ChatGPT將于7月初發布,名為“盤古Chat”:金色財經報道,近日從華為內部獲悉,華為公司將發布一款直接對標ChatGPT的多模態千億級大模型產品,名為“盤古Chat”。預計華為盤古Chat將于今年7月7日舉行的華為云開發者大會(HDC.Cloud 2023)上對外發布以及內測,產品主要面向To B/G政企端客戶。這意味著,在國產大模型軍備競賽中,繼阿里、百度之后,又一重要科技巨頭入局。基于華為的技術能力,盤古Chat有望成為國內技術能力最強的ChatGPT產品,同時華為生態產業鏈企業也將因此受益。(鈦媒體)[2023/6/4 21:14:55]
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
KyberSwap宣布集成預言機Chainlink以增強喂價機制:去中心化交易平臺KyberSwap宣布集成預言機Chainlink以增強喂價機制。(Cointelegraph)[2020/6/14]
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
韓國coinnest將與OceanChain等企業召開研討會:4月30日韓國加密貨幣交易所進行每月一次的研討會。本次研討會參加的企業有OceanChain,FreyrChain, TEK&LAW, UnitedBitcoin, BitcoinGold 等。[2018/4/18]
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
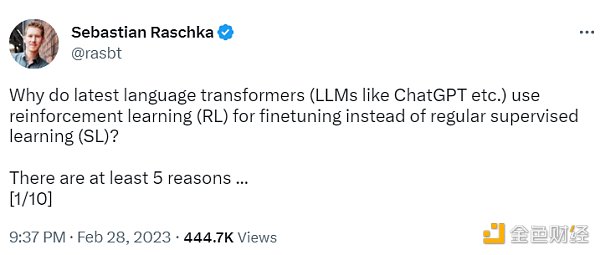
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
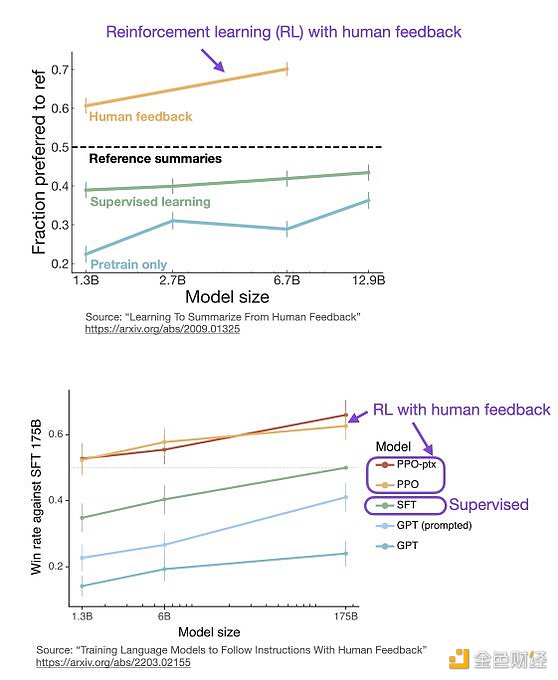
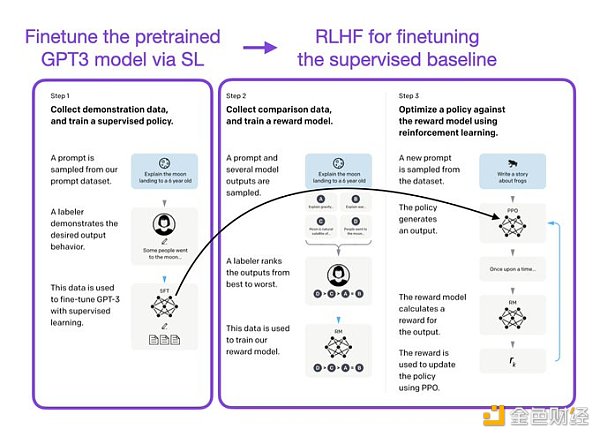
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
當地時間3月7日上午,美央行主席鮑威爾在參議院發表半年度貨幣政策證詞。鮑威爾表示,由于通脹持續存在,美聯儲可能會繼續收緊貨幣政策,而且可能會比之前預期的更快,這是繼上個月加息步伐放緩后出乎意料的.
1900/1/1 0:00:00原文:《 Radiant:全鏈貨幣市場》 作者:藍狐筆記 Radiant(RDNT)于 2022 年 7 月份推出,是 Arbitrum 上的原生借貸市場項目。從貨幣市場角度,它們類似.
1900/1/1 0:00:00作者:Frogs Anon 編譯:DeFi 之道 毫無疑問,自 Compound 在 2020 年啟動 DeFi 夏季以來,DeFi 已經取得了長足的進步.
1900/1/1 0:00:00加密銀行 Silvergate Bank 的財務危機嚇壞了市場。周五亞洲時段開市后,比特幣跌至盤中低點 22,020 美元,以太坊跌至1,550美元附近,跌幅超過5%,加密總市值在一個小時內蒸發.
1900/1/1 0:00:003月7日,針對美國證券交易委員會(SEC)拒絕灰度將GBTC轉化為現貨比特幣ETF的申請一事,雙方已在哥倫比亞特區上訴法院展開法庭辯論.
1900/1/1 0:00:00前言:2022 年,FTX暴雷之后,日本、韓國、美國、新加坡等多個地區對加密行業監管政策收緊.
1900/1/1 0:00:00


