






 BTC/HKD+1.03%
BTC/HKD+1.03% ETH/HKD+0.65%
ETH/HKD+0.65% LTC/HKD+1.76%
LTC/HKD+1.76% DOT/HKD+1.5%
DOT/HKD+1.5% ADA/HKD+3.35%
ADA/HKD+3.35% SOL/HKD+1.36%
SOL/HKD+1.36% XRP/HKD+2.43%
XRP/HKD+2.43% DOGE/US+2.15%
DOGE/US+2.15%關于ZKML:ZKML(Zero Knowledge Machine Learning)是一種機器學習技術,它結合了零知識證明(Zero-Knowledge Proofs)和機器學習算法,旨在解決機器學習中的隱私保護問題。
關于分布式算力:分布式算力是指將一個計算任務分解成多個小任務,并將這些小任務分配給多個計算機或處理器進行處理,以實現高效的計算。
AI與Web3的現狀:失控的蜂群與熵增
在《失控:機器、社會與經濟的新生物學》里,凱文·凱利曾提出過一個現象:蜂群會按照分布式管理,以群舞的方式進行選舉決策,整個蜂群跟隨在本次群舞中最大規模的蜂群成為一次事件的主宰。這也是墨利斯·梅特林克提到的所謂“蜂群的靈魂”——每一只蜜蜂都可以做出自己決定,引導其他蜜蜂進行證實,最后形成的決定真正意義上都是群體的選擇。

熵增無序的規律本身就遵循熱力學定律,物理學上的理論具象化是把一定數量的分子放入空箱,測算最后的分布概況。具體到人,由算法生成的群氓雖有個體的思維差異也能展現出群體規律,往往是因時代等因素被限制在一個空箱中,最后會做出共識性的決策。
zkSync Era的TVL突破5億美元,一周內增長12%:金色財經報道,根據數據源L2Beat的數據,周一早些時候,zkSync Era上鎖定的總價值(TVL)升至5億美元以上,一周內增長了12%。Matter Labs的zkSync Era是一個旨在擴展以太坊的零知識(ZK)匯總。[2023/6/19 21:47:25]
當然,群體規律未必是正確的,但是可以代表共識,能夠以一己之力拉起共識的意見領袖是絕對的超級個體。但大多數情況下共識也并不追求所有人人完全無條件的同意,只需要群體具有普遍的認同性。
我們在此并不討論AI是否會將人類帶入歧途,實際上這類討論已然很多,不論是人工智能應用生成的大量垃圾已經污染了網絡數據的真實性,還是因為群體決策的失誤會導致一些事件走向更加危險的境地。
AI目前的狀況帶有著天然的壟斷,比如大模型的訓練和部署需要大量的計算資源和數據,而只有一小部分企業和機構具備這些條件。這些數以億萬計的數據被每個壟斷所有者視若珍寶,不要提開源共享,就連互相的接入也是不可能的。
這就帶來了極大的數據浪費,每一個大體量AI項目都要進行用戶數據的重復收集,最后以贏家通吃——不論是并購還是賣出,做大個別巨形項目,還是傳統互聯網圈地跑馬的邏輯。
很多人說,AI和Web3是兩回事,沒有任何聯系——前半句是對的,這是兩個不同的賽道,但后半句是有問題的,利用分布式技術限制人工智能的壟斷終局,以及利用人工智能技術促進去中心化共識機制的形成,簡直是天然的事情。
當前zkSyncEra TVL達到9392萬美元,超過zkSync Lite:金色財經報道,據L2BEAT數據顯示,zkSync Era在推出一周后網絡總鎖倉量(TVL)目前達到9392萬美元,超過zkSync Lite(8622萬美元)。[2023/4/1 13:39:27]
底層推演:讓AI形成真正的分布式群體共識機制
人工智能的核心還是在于人本身,機器和模型不過是對人思維的揣測和模仿。所謂群體,實際上很難把群體抽象出來,因為每日所見的還是真實的個體。但模型就是利用海量的數據進行學習和調整,最后模擬出的群體形態。不去評價這種模型會造成什么樣的結果,因為群體作惡的事件也并非一次兩次發生。但模型確切代表了這種共識機制的產生。
舉個例子,對于一個特定的DAO來說,如若把治理做到機制,必然會對效率產生影響,原因是群體共識的形成本就是一件麻煩的事情,更何況還要投票、統計等進行一系列操作。如果把DAO的治理以AI模型形式體現,所有的數據收集本就來自于DAO內所有人的發言數據,那么輸出的決策實際上會更接近于群體共識。
單個模型的群體共識可以按照如上的方案進行訓練模型,但對于這些個體來說終究還是孤島。若是有集體智能系統形成群體AI,在這個系統中每個AI模型之間會相互協同工作,用來解決復雜問題,其實就對共識層面的賦能有了極大的作用。
跨鏈DEX zkLink宣布在Solana上成功實現Groth16zk-SNARK證明系統:3月25日消息,跨鏈DEX zkLink宣布在Solana上成功實現了Groth16zk-SNARK證明系統。zkLink是一個基于ZK-Rollup技術的跨鏈交易平臺,旨在鏈接多鏈,聚合不同生態的流動性。現訂單簿模式的DEX Demo已上線測試網進行測試。[2022/3/25 14:17:51]
對于小型集合既可以自主的去搭建生態,也可以和其他集合形成配合集,更加高效低成本的滿足超大型的算力或者數據交易。但問題又來了,各個模型數據庫之間的現狀是完全不信任、防備著其他人的——這正是區塊鏈的天然屬性所在:通過去信任化,實現真正分布式的AI機器間安全高效互動。
一個全球性的智能大腦可以使得原本相互獨立且功能單一的AI算法模型相互配合,在內部執行復雜的智能算法流程,就可以不斷增長的形成分布式群體共識網絡。這也是AI對Web3賦能的最大意義所在。
隱私與數據壟斷?ZK與機器學習的結合
人類不論是對于AI作惡還是基于對隱私的保護、對數據壟斷的畏懼,都要針對性的進行防范。而最核心的問題在于我們并不知道結論是如何得出,同樣的,模型的運營者也并不打算對這個問題解惑答疑。而針對于上文中我們提到的全球性智能大腦的結合就更需要解決這個問題,不然沒有數據方愿意拿出自己的核心去和別人共享。
zkTube將于7月19日0時(UTC)進行測試網強制更新:據zkTube Labs最新消息:自7月13日發布測試網更新公告以來,我們檢測到仍有部分節點用戶在上一版本運行測試網絡,并未進行版本更新,不但浪費了用戶機器的耗能,還對目前更新后版本網絡運行造成一定影響。zkTube Labs經討論后決定,將于7月19日00:00時(UTC時間),不再接受并將強制阻斷舊版本網絡程序請求,避免造成用戶網絡帶寬浪費和機器無端耗能,所有參與節點用戶必須在19日發布最新版本后進行更新才可連接網絡程序請求。[2021/7/18 1:00:48]
ZKML(Zero Knowledge Machine Learning) 是將零知識證明用于機器學習的技術。零知識證明 (Zero-Knowledge Proofs,ZKP),即證明者(prover)有可能在不透露具體數據的情況下讓驗證者(verifier)相信數據的真實性。
以理論案例為引。有一個9×9的標準數獨,完成條件是需要在九個九宮格里,填入1到9的數字,讓每個數字在每個行、列及九宮格里都只能出現一次。那么布置這道謎題的人如何在不泄露謎底的情況下向挑戰者證明該數獨有解呢?
Celer與StarkWare合作開發Layer2.finance的ZKRollup版本:據官方博客文章消息,以太坊二層擴容項目Celer Network宣布與零知識證明研究機構StarkWare達成合作,雙方將為擴容方案Layer2.finance開發基于零知識證明的ZKRollup版本。Layer2.finance的v0.1版本最近在以太坊主網啟動,借助了Celer基于Optimistic Rollup的解決方案。[2021/4/28 21:05:02]
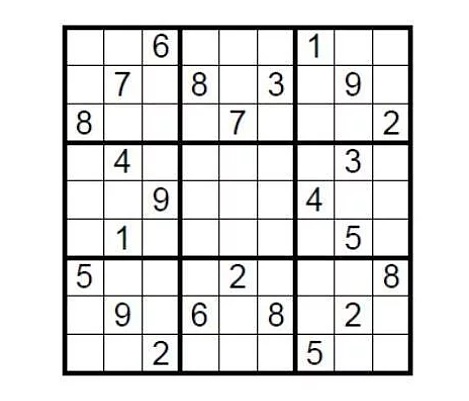
只需要在填充處用答案蓋住,然后隨機讓挑戰者抽取幾行或者幾列,把所有的數字打亂順序然后驗證是否都是一到九即可。這就是一個簡單的零知識證明體現。
零知識證明技術具有完備性,正確性和零知識性三個特點,即證明了結論又不需要透露任何細節。其技術來源更是可以體現簡約性,在同態加密的背景下,驗證難度要遠遠低于生成證明難度。
機器學習(Machine Learning)則是使用算法和模型來讓計算機系統從數據中學習和改進。通過自動化的方式從經驗中學習,可以使系統根據數據和模型自動進行預測、分類、聚類和優化等任務。
機器學習的核心在于構建模型,這些模型可以從數據中學習并自動進行預測和決策。而這些模型的搭建構造通常需要三個關鍵要素:數據集、算法和模型評估。數據集是機器學習的基礎,包含了用于訓練和測試機器學習模型的數據樣本。算法是機器學習模型的核心,定義了模型如何從數據中學習和預測。模型評估是機器學習的重要環節,用于評估模型的性能和準確性,并決定是否需要對模型進行優化和改進。

在傳統的機器學習中,數據集通常需要被收集到一個中心化的地方進行訓練,這意味著數據所有者必須將數據共享給第三方,這可能會導致數據泄露或隱私泄露的風險。而使用ZKML,數據所有者可以在不泄露數據的情況下,將數據集共享給其他人,這是通過使用零知識證明來實現的。
零知識證明運用于機器學習的賦能,效果應該是可以預見的,這就解決了困擾已久的隱私黑箱和數據壟斷問題:項目方是否可以在不泄露用戶數據輸入或模型具體細節的情況下完成證明和驗證,是否可以讓每一個集合都能夠共享自己的數據或者模型進行作用而不會泄露隱私數據?當然,目前的技術還早,實踐肯定會有很多的問題存在,這并不妨礙我們暢想,并且已經有許多團隊在進行開發。
這種狀況會不會帶來小型數據庫對大型數據庫的白嫖呢?當你考慮到治理問題的時候,就又回到我們Web3的思維中了,Crypto的精髓在于治理。不論是通過大量的運用或者是共享都應該獲得應有的激勵。不論是通過原有的Pow、PoS機制還是最新出現的各種PoR(聲譽證明機制),都是在為激勵效果提供保證。
分布式算力:謊言與現實交織的創新敘事
去中心化算力網絡一直是加密圈熱門提到的一個場景,畢竟AI大模型需要的算力驚人,而中心化的算力網絡不單會造成資源浪費還會形成實質上的壟斷——如果比到最后拼的就是GPU的數量,那未免太沒有意思了。
去中心化算力網絡,實質是將分散在不同地點、不同設備上的計算資源整合起來。大家常提的主要優勢都有:提供分布式計算能力、解決隱私問題、增強人工智能模型的可信度和可靠性、支持各種應用場景下的快速部署和運行,以及提供去中心化的數據存儲和管理方案。沒錯,通過去中心化算力,任何人都可以運行AI模型,并在來自全球用戶的真實鏈上數據集上進行測試,這樣就可以享受到更加靈活、高效、低成本的計算服務。
同時,去中心化算力可以通過創建一個強大的框架來解決隱私問題,保護用戶數據的安全和隱私。并且提供透明、可驗證的計算過程,增強人工智能模型的可信度和可靠性,為各種應用場景下的快速部署和運行提供靈活、可擴展的計算資源。
我們從一套完整的中心化算力流程來看模型訓練,步驟通常會分為:數據準備、數據分割、設備間數據傳輸、并行訓練、梯度聚合、參數更新、同步,再到重復訓練。在這個過程當中,即便是中心化機房使用高性能的計算設備集群,通過高速網絡連接共享計算任務,高昂的通信成本也成為了去中心化算力網絡的最大限制之一。
因此,盡管去中心化算力網絡具有很多優勢和潛力,但依照目前的通信成本和實際運行難度來看發展道路仍然曲折。在實踐中,實現去中心化算力網絡需要克服很多實際的技術問題,不論是如何確保節點的可靠性和安全性、如何有效地管理和調度分散的計算資源,還是如何實現高效的數據傳輸和通信等等,恐怕都是實際面臨的大問題。
尾:留給理想主義者的期待
回歸當商業現實之中,AI與Web3深度結合的敘事看上去如此美好,但資本與用戶卻更多地用實際行動告訴我們這注定是場異常艱難的創新之旅,除非項目方能像OpenAI一樣,在自身強大的同時抱住一個強有力的金主,否則深不見底的研發費用與尚不清晰的商業模式將把我們徹底擊碎。
金色早8點
Odaily星球日報
金色財經
Block unicorn
DAOrayaki
曼昆區塊鏈法律
Tags:KSYSYNCZKSzkSynczksync幣空投比例Brain Synczksync幣發行量zksync幣圖標
來源:bitcoinist;編譯:區塊鏈騎士隨著法律網絡的持續收緊,美國檢察官要求對已倒閉的Crypto交易所FTX的創始人Sam Bankman-Fried進行一場單獨的審判.
1900/1/1 0:00:00作者:DeFi^2(@DefiSquared);編譯:Babywhale,Foresight News 該 Twitter Thread 的作者為 DeFi^2,據其推特簡介顯示.
1900/1/1 0:00:00在基本面水平相當的情況下,代幣供應和需求對代幣價格走勢有較大影響。本文將對比三個主要衍生品DEX協議GMX、DYDX、SNX的代幣供應及需求,更深入地了解協議的代幣經濟模型,輔助投資決策.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:411.46億美元 DeFi總市值及前十代幣 數據來源:coingecko2、過去24小時去中心化交易所的交易量32.
1900/1/1 0:00:00作者:Bankless;編譯:比推BitpushNews Mary Liu在上周的監管沖擊之后,思考加密貨幣是否面臨生存威脅不是件易事.
1900/1/1 0:00:00L1 之戰對于加密投資者來說不再是一個新概念。盡管如此,由于舊的 L1s 不斷被完善,新的 L1s 層出不窮,不跟上敘事的投資者可能會被甩出發展浪潮.
1900/1/1 0:00:00


