






 BTC/HKD+1.01%
BTC/HKD+1.01% ETH/HKD+0.77%
ETH/HKD+0.77% LTC/HKD-0.17%
LTC/HKD-0.17% DOT/HKD-1.05%
DOT/HKD-1.05% ADA/HKD-0.16%
ADA/HKD-0.16% SOL/HKD+1.58%
SOL/HKD+1.58% XRP/HKD+0.12%
XRP/HKD+0.12% DOGE/US+1%
DOGE/US+1% 
分享嘉賓:竇英通伊利諾伊大學芝加哥分校
編輯整理:郭艷中山大學
出品平臺:DataFunTalk
導讀:本文是一篇來自學術界的分享,不會講太多的具體實操案例,而是根據我對于欺詐檢測領域的了解以及學術界的論文,介紹這些論文的發展脈絡和論文中一些代表性的工作,以及從論文中總結出如何更好地把圖神經網絡應用到欺詐檢測問題中的方法論。最后,還會給出一些相關資源以及我們實驗室做的一些開源項目供大家參考。文中提到的論文和資源,大家如果感興趣可以進一步研究和學習。
本文主要包含以下幾大方面:
背景介紹
研究歷程
應用方法
相關資源
01
背景介紹
1.什么是欺詐
根據美國法典,欺詐有四個方面:
對事實的錯誤表達
從一個人到另外一個人or從一個企業到另外一個企業
欺詐者知道事情的虛假性
欺詐者通過欺詐引誘別人產生其他行為
下面我們通過比較不同概念來更好地定義欺詐者:
欺詐者vs.黑客首先比較一下欺詐者和黑客的定義。大多數的欺詐者不是黑客,常見的欺詐者主要利用一些規則的漏洞,但是并沒有破壞安全系統;但是也有一些黑客通過破壞系統來達到欺詐的目的。欺詐vs.異常
再來說說欺詐和異常的區別。首先很多欺詐,并不屬于異常,從后臺數據來看,很多欺詐者的表現和正常用戶并無明顯區別,但是可能對于某個業務來說,其行為又確實屬于欺詐。同時,很多異常也不屬于欺詐,很多異常可能是別的原因導致的,所以它的目的不一定是欺詐。
上圖右下,是百度上某一個APP的搜索趨勢圖,可以看到,該APP在某一天在百度上的搜索量很大。為什么當時我們會搜索APP,是因為我們在應用市場的后臺中檢測發現它在某一天的下載量暴增。從應用市場的角度來說,這是一個異常行為。為了弄清楚這個異常行為是否是欺詐,我們反過來去搜APP。故而在應用市場該APP下載量暴增的一天,其在百度的搜索量也暴增。這說明它的下載量暴增并不一定是通過一些刷量行為到達的,而可能是該APP進行了一些推廣活動。如果它在各個平臺上的流量都增加的話,那么這就不是一個欺詐行為,而只是一個異常行為。
2.欺詐的種類
欺詐有很多不同的類別。首先一大類是社交網絡上的欺詐,例如社交網絡上的機器人、虛假信息、虛假賬戶、虛假鏈接等等。
另一大類是金融領域的欺詐,比較典型的例如對用戶貸款違約概率的評估、對保險的信用度評估,還有對洗錢的檢測,虛假交易檢測、信用卡套現檢測,還包括最近在比特幣、區塊鏈上的欺詐檢測等等。
除以上兩大類之外,還有很多其他類型的欺詐行為,例如廣告流量欺詐、CTR造假、手機APP的虛假留存、電商的羊毛黨、眾包攻擊、游戲外掛等等。從宏觀上來說,這些行為都屬于欺詐的范疇。
加密ATM公司CoinFlip正在美國伊利諾伊州擴張:8月26日消息,加密ATM公司CoinFlip正在美國伊利諾伊州擴張。該公司從該州獲得資金,以做出長期留在伊利諾伊州的承諾,并進行1700萬美元的資本投資,以換取近170萬美元的經濟稅收抵免。(Washington Examiner)[2021/8/26 22:37:56]
隨著深度學習在欺詐檢測問題的應用越來越多,欺詐檢測領域逐漸變成了數據科學、安全和機器學習三個大領域的交叉領域,需要三個領域的知識去完成欺詐檢測或者完成風控系統的設計。
3.基于GNN的欺詐檢測
接下來,我們介紹圖神經網絡在欺詐檢測中的應用,主要分三步:
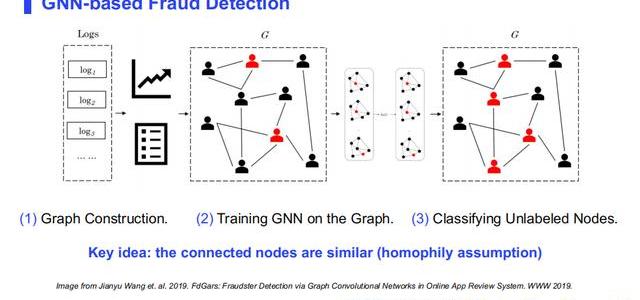
(1)構建圖
主要通過后臺的各種日志,比如說用戶的日志,提取日志中用戶的信息,組成圖中的節點,通過用戶之間的關系,組成圖中的邊,從而完成圖的構建。
(2)訓練圖神經網絡學習圖中信息
學習到的信息可以是節點的Embedding、邊的Embedding或者圖的Embedding。
(3)基于Embedding訓練分類器
基于第二步得到的Embedding和已知的一些標簽信息,例如上圖,已知紅色節點為欺詐者,黑色節點標簽未知,根據已知的標簽訓練分類器來得到對未知標簽節點的預測。
以上三步就是圖神經網絡應用的經典的三個步驟。其核心思想為同質性假設,即圖中相連節點是相似的。比如在欺詐檢測問題中,同質性假設認為,正常用戶更多地和正常用戶互動,而異常用戶更多地和異常用戶互動。這是圖神經網絡應用到欺詐檢測的一個最基本的假設。
02
研究歷程
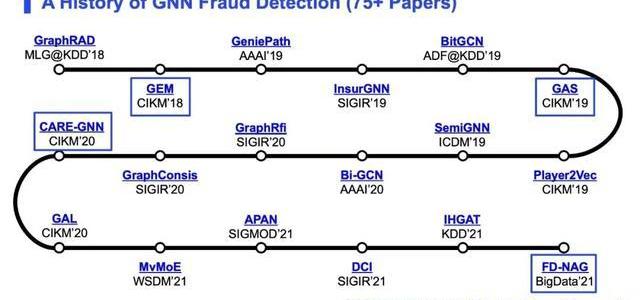
上圖從論文的角度介紹了圖神經網絡在欺詐檢測領域的研究情況,我們先來看一下整個歷程,后面還會詳細介紹4篇比較具有代表性的論文。
首先就是2018年的GraphRAD(MLG@KDD’18),它是第一篇將圖神經網絡應用到欺詐檢測問題中的文章,來自亞馬遜。
之后18年螞蟻金服發表的GEM(CIKM’18)是第一次將異質信息網絡應用到欺詐問題中,這篇文章在后文會詳細介紹。
后續在19年阿里發表的兩篇文章GeniePath(AAAI’19),InsurGNN(SIGIR’19)也是將一些最基礎的圖神經網絡模型應用到不同領域的欺詐檢測任務上,比如SIGIR’19這一篇就是檢測保險領域的欺詐問題。
同時,19年的BitGCN(ADF@KDD’19)首次將圖卷積網絡應用到比特幣中,并且它還公開了其數據集,這個數據集后續被很多人應用,因為它是一個非常好的動態數據集去研究虛假交易在比特幣網絡中的演變情況。
19年底的GAS(CIKM’19)來自于阿里巴巴集團的咸魚APP團隊,它是用來檢測咸魚平臺上的虛假評論,這篇文章在后續會詳細介紹。
政策 | 美國伊利諾伊州定義區塊鏈合法地位的法案重回參議院:據ethnews早先報道,美國伊利諾伊州此前正制定旨在澄清區塊鏈技術合法地位的眾議院法案5553,該法案6月初錯過了委員會的最后提交期限。然而,據ethnews今日的報道,法案5553已被送回參議院委員會,該委員會現在可以選擇將該法案重新提交給另一個委員會進一步審議。該法案將提供區塊鏈和智能合約的法律定義,規定哪些可以或不可以放在區塊鏈上,并且會禁止地方政府對其征稅。[2018/7/4]
Player2Vec(CIKM’19)是第一篇把異質圖神經網絡應用到安全領域的文章,它是檢測地下論壇里一些黑灰產的一些交易者的情況。
SemiGNN(ICDM’19)來自于螞蟻金服,其解決的是螞蟻金服上用戶的信用評估問題。
Bi-GCN(AAAI’20)這篇文章與其他文章不同的是,它研究的是社交網絡中的謠言問題,它也是這幾年在謠言檢測領域影響力非常大的一篇文章,提出了從謠言源頭和謠言最末端雙向設計圖的一個模型,這篇文章在設計圖的結構上會比較有意思。
GraphRfi(SIGIR’20)是第一篇把欺詐檢測和其他任務結合起來的文章,它是把欺詐檢測和推薦系統作為一個互相補充的任務一起學習。
GraphConsis(SIGIR’20),CARE-GNN(CIKM’20)這兩篇來自于我們實驗室,CARE-GNN(CIKM’20)也將在后文詳細介紹。
GAL(CIKM’20)這篇文章將圖神經網絡和無監督的模型結合在一起,因為圖神經網絡的訓練比較依賴于標簽,尤其對于欺詐檢測問題來說,如果沒有標簽的信息,訓練一個很好的分類器會很難。而這篇文章解決了一個標簽稀少的問題。
今年年初來自于阿里巴巴的文章MvMoE(WSDM’21)提出了一個多任務的框架,即將圖神經網絡應用到用戶信用評估和違約預測兩個任務上面,在底層兩者共享一個圖神經網絡的基礎模型,但是在模型的上端,有一個多任務的分支。
APAN(SIGMOD’21)來自于螞蟻金服,解決的是流式學習的問題,即當數據是在動態變化的時候,如何更好地利用歷史信息訓練模型。這篇文章還講到了如何在online-inference時候提高模型的效率的問題,所以這篇文章是一個偏系統設計的文章,值得一看。
DCI(SIGIR’21)來自于中國人民大學的研究小組,他們第一次在欺詐檢測的數據集上應用到了自監督學習/對比學習的概念。而對比學習這個概念非常火,這篇文章也是驗證了自監督學習對于欺詐檢測或者異常檢測問題的有效性。
IHGAT(KDD’21)這篇文章也是來自于阿里巴巴,它引入了用戶動機,在欺詐檢測的圖神經網絡建模中,他們通過對用戶動機的建模,使其能通過圖神經網絡,不僅檢測出欺詐者,還能給出很好的解釋性。
最后一篇文章FD-NAG(BigData’21)是我與我們實驗室成員和東南亞最大的打車平臺Grab合作的一篇欺詐檢測的文章。這篇文章在后文也會有詳細的介紹。
接下來主要介紹四篇代表性文章。
1.GEM

伊利諾伊州定義區塊鏈技術的眾議院法案錯過了提交期限:據ethnews消息,此前美國伊利諾伊州正在制定旨在澄清區塊鏈技術合法地位的眾議院法案5553,然而該法案錯過了委員會的最后提交期限。該法案本應提供區塊鏈和智能合約的法律定義,將規定哪些可以或不可以放在區塊鏈上,并且會禁止地方政府對其征稅。[2018/6/5]
首先第一篇文章來自于螞蟻金服,其研究的問題是支付寶上面的欺詐賬戶檢測。這篇文章構建的圖是異質圖,如上圖,藍色節點代表正常賬戶,黃色節點代表有害賬戶,其他節點如綠色、紅色的節點,代表不同的設備。文章假設不同賬戶,可能在不同的設備上登入,而對于一些欺詐者來說,他可能用很多設備,或者說重復用一個設備,或者說一個設備登入好幾個賬號。基于此假設,通過圖連接,就能很明顯的發現這些異常的行為。
這篇文章是圖神經網絡比較早的應用,將異質信息網絡和圖神經網絡用到檢測問題中,也是影響力比較高的一篇文章。
2.GAS
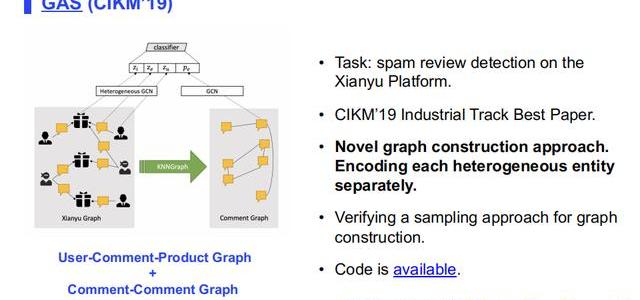
第二篇文章來自于咸魚平臺,獲得了CIKM’19的最佳工業界論文獎,研究咸魚平臺中的虛假評論問題。這篇文章它比較有新意的地方在于,它并不是像很多傳統的異質信息網絡建模的方法——對用戶、商品建模一起評價,相反地,它提出了一個全新的異質信息網絡的節點聚合方法,它針對用戶節點、評論節點以及商品節點,提出了各自的聚合器,聚合他們各自鄰居的信息,學三個不同的表達,然后它還通過評論之間的相似性,構建了一個同質的評論圖。它還包含了很多工業界的分析,比如說驗證了建圖時的一個采樣方法——根據時間區間采樣,因為采樣方法在工業界是比較重要的,圖非常大時不一定需要所有的節點信息。
3.CARE-GNN
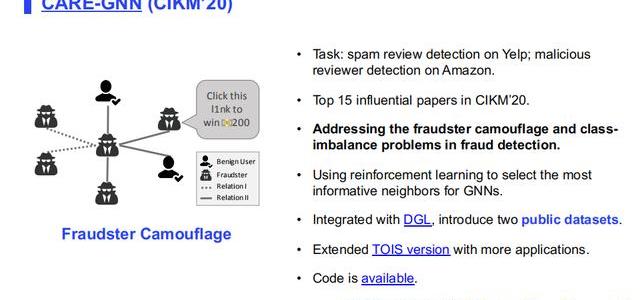
第三篇文章是來自于我們實驗室CIKM的文章,這篇文章最近剛被選為CIKM’20影響力最高的15篇文章之一。我們基于Yelp和Amazon做了兩個開源的數據集,并在這兩個數據集上針對用戶或者說欺詐者的偽裝問題給出了相應的解決方案。欺詐檢測和其他節點分類問題比較大的區別在于,欺詐者是會偽裝的,或者說就是說從某些維度上去看,它正常用戶和異常用戶其實沒什么區別,所以這個時候我們就提出了基于強化學習的方法對鄰居進行選擇,幫助圖神經網絡能夠更好地對這些偽裝的欺詐者進行一個過濾。
這篇文章比較大的貢獻,除了模型之外,還有兩個公開數集,目前已經有很多paper基于這兩個數據集做進一步探索,感興趣的讀者也可以關注一下這兩個數據集,目前已經集合到亞馬遜的DGL庫中,大家可以去調用。同時今年10月份的TOIS的期刊文章中,我們把這個模型擴充到更多的任務上面,在其它的一些數據集上面進行驗證。
4.FD-NAG
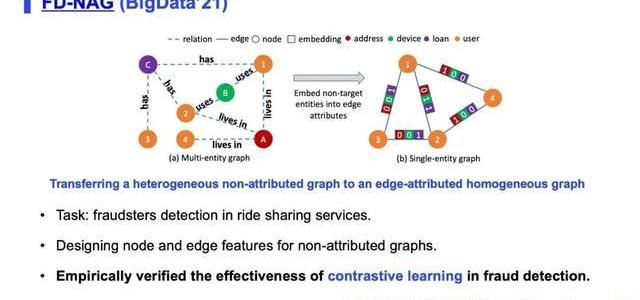
最后一篇是我們今年和東南亞最大打車公司Grab合作的一個項目。我們的任務是檢測打車過程中的存在欺詐的一些用戶。這篇文章我們主要講兩個問題,首先是怎樣在沒有特征的圖上面去建圖,因為對于很多公司來說,它可能剛開始沒有太多的特征工程去給每個節點都設計各種各樣的特征,或者說在欺詐檢測問題中,很多的節點沒辦法設計特征,比如說IP、手機號、地址或者設備這些信息,但這些信息在構建圖的過程中又是非常重要的,因為它們可以連接很多相似的用戶,故而我們設計了一個把這些關鍵節點轉化為邊特征的轉換圖的方法。其次,這篇文章還首次驗證了圖自監督學習和對比學習在欺詐檢測中,尤其是在工業界數據上的有效性。
美國伊利諾伊立法者考慮接受加密貨幣繳納稅款:美國伊利諾伊州的立法者正在權衡一項允許該州居民使用加密貨幣繳納稅款的建議。這一趨勢一月份開始于塔利桑那州,目前美國已經有越來越多的州政府正在考慮采取這種措施。據報道,2月15日提交的伊利諾斯州眾議院條例草案5335指出,“除法律規定的其他其它付款方式外,眾議院應接受加密貨幣支付任何由眾議院執行,國家征收的稅款。公開記錄顯示,該法案已于3月5日提交給伊利諾伊州眾議院稅收和財政委員會審議。[2018/3/7]
03
應用方法
下面根據現有的研究論文,介紹如何更好的去應用圖神經網絡。
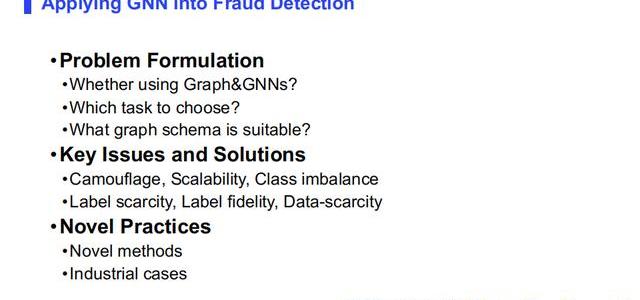
1.如何應用圖神經網絡
這一部分我們會通過五個問題去判斷,去一步一步地建模,如何應用圖神經網絡。
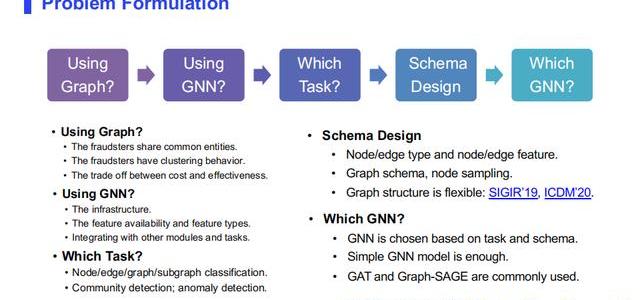
(1)是否要用圖
在我們要應用圖形網絡之前,最開始要問的問題是到底要不要用圖。
我們為什么要在欺詐檢測問題中用圖,有以下幾個原因。首先,欺詐者一定共享某些信息,例如共享IP、共享設備。其次,欺詐者有聚集行為,即在構建圖之后,欺詐者在圖上表現比較聚集,而正常用戶會比較分散。最后,也是要用圖算法最關鍵的問題——成本和效率的問題,因為用圖就意味著要設計一套關于圖的算法,但如果你目前的基礎設施里沒有針對圖的現有的一些計算框架,那么你就要考慮,如果我進行技術迭代,我更新用了一套圖的新算法,投入的成本是否能夠小于它帶來的收益。如果收益高,那肯定建議用圖算法去解決。
(2)是否需要用圖神經網絡
當我們現在確定用圖了,第二個問題就是要不要用圖神經網絡。除了圖神經網絡之外,還有很多傳統的圖算法,基于貝葉斯的一些概率圖模型、基于譜圖算法的矩陣分解模型,這些模型在之前十年得到了很好的研究,而且有很多模型效果都不錯。
首先,圖神經網絡相對于這些模型,最大的優點是它是一個端到端的,不需要你去設計feature。比如你的問題里面有各種各樣的原始feature,甚至你有圖片、聲音、時序信息,那么你其實可以把這些數據直接送到圖神經網絡里面,讓深度學習自己去學習。但如果你用傳統圖模型的話,可能你就需要做一些特征工程的工作。
第二點,如果你的基礎設施里面有現有的深度學習的框架,使得你可以很快地把深度學習或者說把圖神經網絡集成進去,那么建議用圖神經網絡。
(3)什么任務
第三個問題就是我們確定用圖神經網絡之后,選擇什么任務。在圖挖掘領域里面有各種各樣的任務,而幾乎所有的圖相關的任務都跟欺詐檢測相關。
首先是分類任務,分類任務主要有節點分類、邊分類、圖分類以及子圖分類等,除此之外,還有一些聚類問題和異常檢測問題。這些問題基本上都可以跟欺詐檢測問題相關聯。此時,就需要通過對業務的深刻理解,來選擇相應的任務。
如前文所述,欺詐檢測有時候不一定是一個異常問題。例如水軍,或者一些虛假賬戶的檢測里,欺詐者可能在很多數據維度上跟正常用戶都沒什么區別,但是可能有某些行為和欺詐的關聯度很高,這樣就可以把它定義成一個分類問題,再通過圖神經網絡學mapping,從feature到label的mapping。例如是檢測用戶,則可能是一個節點分類問題,如果檢測一個交易,可能就是一個邊的分類問題。
伊利諾伊州計劃將區塊鏈技術用于政府運營:根據美國伊利諾伊州區塊鏈專責小組1月31日提交的報告,州政府正著眼于區塊鏈技術的使用,如管理州居民的身份信息以及公共部門的資產標記,以提高效率并減少欺詐。[2018/2/2]
除此之外,現在很多欺詐的問題還會選擇成團伙檢測問題。因為團伙檢測能夠很快的抓出很多虛假用戶,效率會相對高一點。對于團伙檢測問題,就是一個聚類問題。
當我們業務上明確任務后,就可以根據對業務的理解來選擇合適的圖神經網絡任務。
(4)圖的結構
確定任務之后,下一步就是要設計圖的結構,即需要哪些節點,節點有哪些種類,需要哪些邊、邊有哪些種類,以及節點要不要進行采樣。圖的構建是欺詐檢測與圖神經網絡在其他領域應用,比如生物、自然語言處理等領域,最大的區別。因為欺詐檢測是在一個非常廣的數據上去應用的,很多時候它的數據本來是沒有圖結構的,所以在圖設計這一塊,靈活性是非常大的。
而這一部分的重要性大于后期GNN模型的選擇,一個好的圖結構,是解決欺詐檢測最關鍵的前提。因此在這部分,推薦兩篇文章,它們有比較新的一些建圖方法,可供大家參考。
(5)圖模型選擇
當你的任務確定了,圖確定了,最后一步就是去選擇GNN。這部分很簡單,你可以根據你的任務,例如針對圖分類的,針對異常檢測的,選擇相應最經典的模型即可,不需要特別復雜的模型,只需要選擇最成熟的模型就可以。
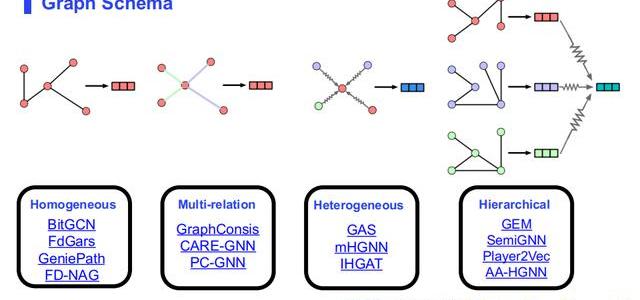
在五個步驟里,最關鍵的一步是圖結構設計。針對圖結構設計,我們再展開講,有這四種設計方法,有同質的、有多關系的、異質的、層級的,大家感興趣可以看一下相應paper中建圖的方法。
2.關鍵的挑戰以及解決方法
下面介紹目前圖神經網絡在欺詐檢測應用中的一些主要問題和解決方案。
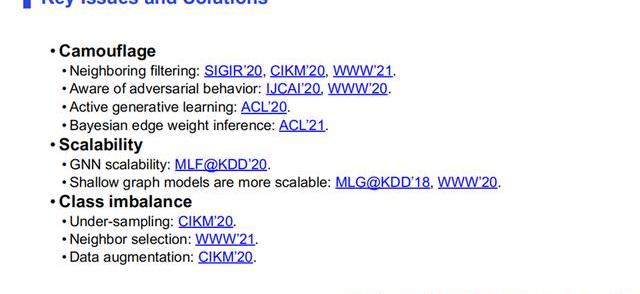
(1)偽裝問題
第一個問題是偽裝問題。前文中,我們的論文也講了偽裝問題,我們解決偽裝問題的方法,就是對這些圖里面的節點進行一些過濾,把一些跟中心節點相似的節點留下來,不相似節點過濾掉。
第二種解決偽裝問題的方法,即在已知對抗行為的存在性下,利用對抗學習的方法增加模型的魯棒性。
第三種就是主動生成,比如生成一些類似于對抗生成網絡,生成一些對抗樣本,來提高模型的魯棒性。
最后一個方法利用貝葉斯的一些方法,對邊進行一些操作。比如說在聚合鄰居的時候,根據節點的一些先驗知識,來判斷這個鄰居是不是偽裝的、是不是真實的,再根據推斷結果調整聚合時的邊權重。
(2)可擴展性問題
第二個問題就是可擴展性問題,可以說是目前圖神經網絡在所有工業界應用的最大的瓶頸。針對這個問題,從論文的角度來說,在欺詐檢測領域,我目前只看到有一篇文章去解決這個問題。
當然如果拋開GNN來說,傳統非深度學習的圖模型,有很多篇研究可擴展性的問題。相對于深度學習模型來說,這種非深度學習的圖模型,其可擴展性會更高一點。關于可擴展性,大家也去可以看一下這些general的可擴展性的研究。
(3)類別不平衡問題
第三個問題,欺詐檢測和其他節點分類問題最大的區別在于欺詐檢測的類別不平衡問題。我們一般將欺詐檢測問題定義成二分類問題,而在工業界數據中,欺詐者的比例是非常低的,100萬用戶中欺詐者可能就只有幾千或幾百個,因此在欺詐檢測中,有極端的類別不平衡問題。對于極端類別不平衡的數據,不管是圖神經網絡還是傳統的機器學習模型來說,如果不做一些調整,模型是不可能學好的。
針對這個問題,最經典的解決方案就是下采樣,在訓練的時候,對大多數的真實用戶做一些采樣,讓它保持和欺詐用戶數量是一致的。
還有一個解決方法,通過對鄰居進行一些選擇,在GNN聚合的時候,保持標簽的平衡性。
最后一種解決方案,即通過數據增強的方法。先學習一些欺詐者的特點,來生成更多欺詐者的訓練數據,從另外一個角度消解標簽不平衡帶來的影響。

(4)標簽稀缺性問題
下一個問題是標簽的稀缺,這個也是欺詐檢測中非常典型的問題。由于打標簽的成本很高,必須得通過一些業務方面的專家、一些規則以及人工的檢查,才能確定對象是不是欺詐。
針對于標簽稀缺的問題,有解決方案是主動學習,根據現有的標簽,對一些unlabeled的data打標簽。還有一種方法集成學習,把一些無監督的學習方法跟有監督的GNN結合到一起。無監督的方法,對一些標簽做一些推斷,然后把這些推斷信息作為監督的信息,再去輔助GNN的學習。
還有一些解決方案是元學習,大家感興趣可以去看一下。
(5)標簽的真實性
另外一個問題是標簽的真實性,或者說標簽的質量。因為在真人打標簽的過程中,不可避免地會出現標簽質量有問題。所以我們如何去教校正這個標簽質量,主動學習是一個方法,它會對標簽的質量進行一個判斷。還有一個叫human-in-the-loop,在機器學習的過程中把打標簽者參與進來。AAAI’20是騰訊微信假新聞檢測的文章,利用強化學習和打標簽者進行互動,也就是說它會根據比如大家對文章的舉報信息,還有真人打標簽的一些反饋信息,把這些信號傳輸到機器學習的pipeline里面去,不斷的去優化學習的過程。
(6)數據的稀缺性
最后一個問題,數據的稀缺性,和label的稀缺性類似,欺詐者的數據,一方面label少,另一方面數據本身也比較少。解決方案是通過數據增強的方法,學習到欺詐者的一些特點,然后去增強它。
3.新的實踐
接下來我會介紹目前學術界一些比較新的研究方向。
第一個就是圖預訓練,這兩年特別火,目前很多文章都是基于對比學習來進行預訓練,而預訓練有一個原則,即欺詐者必須在圖結構方面和正常用戶有明顯的區別,如果只是在feature方面有區別的話,圖預訓練帶來的增益并不是特別高。
第二個比較火的方向是動態圖。為什么要動態信息?因為歷史的信息對于識別欺詐用戶是有用的,所以我們要用動態圖,或者說采用流式的學習方法。但是動態圖,又增加了學習的成本,因為它的訓練會非常慢,推斷時間也比較久。大家就可以參考slides中列出的文章,尤其是螞蟻金服今年APAN(SIGMOD’21)的這篇文章,它是解決流式學習的效率問題。還有最后一篇ROLAND.的文章,作者跟摩根大通銀行合作的一個關于虛假交易檢測的項目,他們也是把動態圖應用到可擴展的一個場景中。
接下來還有一個新的方法,就是多任務學習。還有一個新的方向是可解釋性,上文中也說到今年阿里巴巴IHGAT(KDD’21)就是對用戶動機建模,來解釋虛假的交易。
4.工業界應用
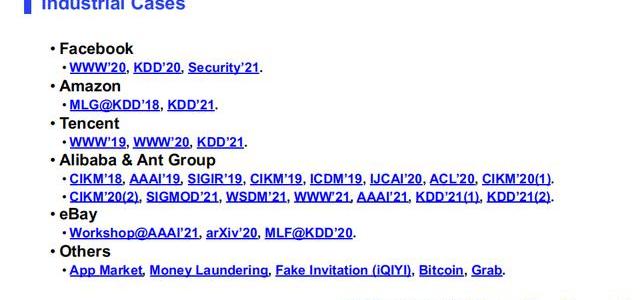
下面我會總結一些工業界的paper,大家會看到阿里巴巴和螞蟻的文章是最多的,當然Facebook,Amazon這幾篇文章都是值得看的,尤其是Facebook有一篇今年最新的Security’21.安全頂會的文章,他們沒有用圖神經網絡,而是用的傳統圖模型,這篇文章里面有很多關于工業界的部署的一些思考,值得參考。除此之外,愛奇藝這篇文章也是比較有意思的文章,大家可以去參考。
04
相關資源
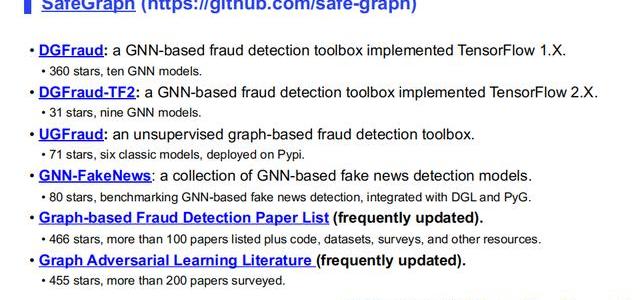
最后我會介紹一些相關資源,首先是我牽頭做的一個開源項目,叫SafeGraph,這里面包括了DGFraud,一個欺詐檢測工具包,我們實現了十個GNN模型,前面都有提到這些模型。需要注意這個包無法直接應用到工業界,因為它更適合原型建模,大家可以通過這些代碼了解這些不同的GNN在建模中的不同的方法,作為學術界和工業界的一個參考。
UGFraud是一個基于無監督圖模型的欺詐檢測的工具包,已經release到PIP上面,大家可以通過PIP安裝。
UPFD是一個基于圖神經網絡的假新聞檢測項目,公開了兩個基于假新聞分類的數據集,也實現了一些圖神經網絡的基本算法,把它集合到DGL,還有PyG中。
最后是兩個我們經常更新的圖欺詐檢測和圖對抗學習論文列表,大家可以去在上面找相關的論文、相應的代碼以及數據集,還有其他一些資源。
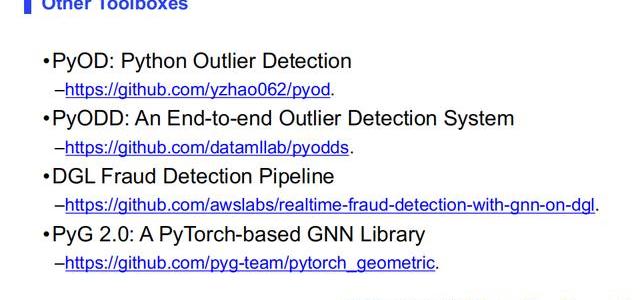
除此之外現在工業界或者說現在開源項目里面比較流行的幾個異常檢測的包有PyOD和PyODD,還有DGL團隊基于DGL和AWS做的的欺詐檢測Pipeline,也是開源在Github上的,工業界同學感興趣可以看一下。
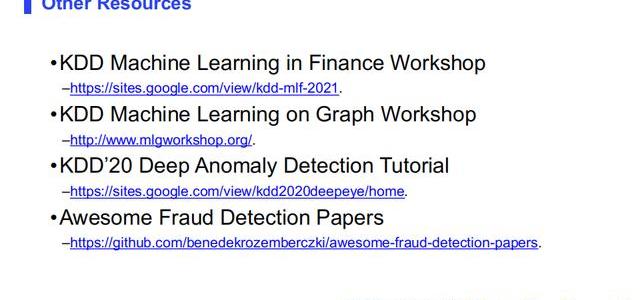
還有一些基于KDD的workshop,與金融和欺詐檢測相關,可以參考。
圖欺詐檢測是一個偏應用的問題,所以我希望通過與工業界的朋友們交流,更好的把圖神經網絡應用到不同的風控和欺詐檢測場景中。
今天的分享就到這里,謝謝大家。
意思是:沒有這樣的文件或目錄。1.“Nosuchfileordirectory”一般是沒有找到文件的位置,你應該在屬性中將它找不到的文件的路徑添加到包含目錄那一列里.
1900/1/1 0:00:00最慘貨幣來了!今年土耳其里拉累計貶值45%,上周里拉對美元匯率還連破12比1、13比1兩個整數關口,一度跌至13.49比1的歷史最低點;隨后有所回升,截至11月30日.
1900/1/1 0:00:00基金、盲盒、超前點播、網紅雪糕、直播打賞、玲娜貝兒......這些被網友戲稱為2021年十大“肉疼”的剁手項目,你都做過哪些?不過網警蜀黍發現,還有一種讓你“肉疼”的東西.
1900/1/1 0:00:00本文來源:時代周報作者:郭子碩元宇宙概念大火,區塊鏈游戲也搭上順風車。“攜手v神,馬斯克實現火星夢”.
1900/1/1 0:00:00資金提前潛伏,國內巨頭紛紛加碼,數字貨幣飛入尋常百姓家,準備迎接豐收年!數字經濟時代,數字貨幣在其中也將起到至關重要的作用,將助力我G在全球化經濟當中取得數字化經濟的制高點.
1900/1/1 0:00:00貨幣是商品經濟的產物,是充當一般等價物的特殊商品,在漫長的演進中形成豐富的貨幣文化,成為人類文明的重要體現.
1900/1/1 0:00:00


