






 BTC/HKD-0.19%
BTC/HKD-0.19% ETH/HKD-2.01%
ETH/HKD-2.01% LTC/HKD-3.37%
LTC/HKD-3.37% DOT/HKD-3.24%
DOT/HKD-3.24% ADA/HKD-1.76%
ADA/HKD-1.76% SOL/HKD-2.46%
SOL/HKD-2.46% XRP/HKD-1.57%
XRP/HKD-1.57% DOGE/US-1.65%
DOGE/US-1.65%以下文章來源于VLSI架構綜合技術研究室,作者VASTLab
7引言:叢京生院士為作者之一的論文“AutoDSE:EnablingsoftwareprogrammerstodesignefficientFPGAaccelerators”獲得了2023ACMTODAES最佳論文獎。為了介紹這項工作以及叢院士在民主化集成電路設計和可定制計算上所構建的生態系統,我們在此翻譯了他在ICCAD‘2022開幕日所做的主題演講以饗讀者。

很高興在ICCAD’2022現場見到這么多同仁!我本人也非常榮幸能夠在這次的ICCAD開幕日做主題演講。
ICCAD對我來說有著非常特別和重要的意義。35年前我的第一篇論文是在ICCAD上發表的。在這張幻燈片左邊你可以看見這篇文章的截圖。因為年代久遠我并沒有在ICCADProceedings上找到這篇文章的電子版,但是我在IEEETransactionsonCAD上還是找到了這篇文章的期刊版本。幻燈片右邊你能看見當年UIUC四位年輕的研究生。站在我旁邊的男士是黃定發教授,他現在是香港中文大學工程學院院長。站在我旁邊的年輕女士現在是IBMEDA部門的資深員工。站在照片最左邊的男士是KCChen。你們中的有些人可能知道他是前世界級芯片驗證公司Veriplex的共同創辦人。Veriplex后來被Cadence收購。當我找到這張照片的時候心中涌起了許多回憶。最重要的一點我想說這次的主題演講也是為我的導師劉炯朗先生所做。他也是這篇文章的作者之一。他的一言一行帶領我走進了EDA的世界并引導我了解如何真正做好科研。我非常希望劉炯朗先生今天也能在現場,然而他在兩年前不幸過世。相信我們所有人都會記住他在這個領域深耕幾十年的巨大貢獻。我在這篇文章里講的是一種三層芯片設計通道布線(three-layerchannelrouting)的方法。這在當時是個新問題,是我在1987年根據當年的技術水平寫的文章。在那個時候芯片還只有兩層的設計所以我們猜測工業界會向三層或者多層發展。那么這個情況下的布局布線問題就是個很好的研究課題。實際上我們在兩年后的確看見Intel在486處理器上使用了三層的設計。順帶一提486芯片同時實現了片內集成超一百萬晶體管的這個令人激動的里程碑。

所以當回看這35年間我的實驗室的科研路線,前20年我的關注點一直在服務于硬件工程師的電子設計自動化。我們希望他們可以設計出更好的奔騰處理器或者更好的硬件加速器。但是過去的10年或15年我們逐漸地改變了重心:變成可以讓更多的軟件工程師來設計他們自己所需要的定制化集成電路和加速器,特別是其在FPGA上的實現。當被問到為什么我們要轉換跑道我想說我們想使得可定制計算成為可能。我們可以用下面這幅圖來解釋一下15年前為什么我們決定開始轉變賽道。各位可能都見過這幅Intel繪制的能耗圖線。我們可以看到頻率的增加是和熱量的產生成正比的。今天大多數的芯片都運行在2-4GHz之間。想做一個太赫茲級的芯片其實是沒有問題的,只是做完運行后你大概率會發現芯片被自己燒了。所以工業界在2000年中后期沿著圖線向右折了一下,從單純提高頻率轉向并行設計。基本意思就是我們盡量保持現有的頻率,然后增加更多的核來設計出更強大的芯片。當時也有對功率和散熱進行專門的分析。在那個時候我們實際上已經提出了一個更大膽的想法,那就是我們應該再往下走一步讓芯片架構服務于具體應用,而不是先固定架構再進行開發。所以我們向美國國家科學基金會提交了一個相關的項目申請。很幸運這個項目獲得了NSF的5年1000萬美元的資助并同時獲得了ExpeditioninComputing的獎項。這在當時應該是NSF最大的獎項和資助之一。在申請中我們寫了出現在幻燈片里的一句話“不止著眼于并行設計,同時關注特定領域可定制設計從而顯著提高功耗-性能的效率”。我們不僅寫下了這句話我們也是沿著這個方向努力去做的。實際上也有很多同仁做出了成功的例子。其中最著名的例子是谷歌的TPU。TPU就是專門為一種應用而設計的,那就是深度學習。如果你仔細去看TPU的設計架構,他主要就是由一個個矩陣-向量乘法塊或者矩陣-矩陣乘法塊構成。TPU的論文報告了相比于最先進CPU快200倍,GPU快70倍的性能提升。當然現在CPU和GPU的性能也在提升,所以這是個大概的數字。谷歌的TPU是個非常大的成就。但是設計類似TPU這樣的特定芯片有一些顯著的限制。首當其沖的問題就是必須非常有錢。根據麥肯錫做的調查報告設計制造7nm的芯片需要花費至少15億人民幣。你有沒有15億人民幣這是第一個問題。第二個問題是你必須要很有耐心。我實驗室的學生不是很喜歡去設計芯片以及流片,原因之一就是從你有想法到流片成功至少需要兩年的時間。萬一你的設計流片回來發現有問題你又要重新流片,這就很難及時發出文章。一般畢業你可能需要有三篇文章發表,那你什么時候才能畢業呢?不僅如此各類算法和設計都在快速推陳出新,可能現在的想法很快就過時了。所以冗長的設計周期也是一項限制。盡管可定制計算芯片有諸多限制,你還是可以在可編程邏輯器件FPGA上實現很多的可定制計算,也能達到很高的計算效率。我在這里想舉一個我們在ISCA’2020上發表的工作。這項工作其實是在講一個很經典的問題——排序。不過不是對10000個數字排序,而是對超大規模,比如10T規模的數字進行排序。我們的做法從宏觀上看是一個簡單的歸并排序,這樣的排序先對許多小塊數據進行排序,然后合并小塊排序合成更大的塊。你可以知道計算層面的算法復雜度是NlogN,數據的移動也是最優化的。
美國民主黨要求能源和環境保護局強制加密礦業公司報告其排放量和能源消耗:2月7日消息,美國民主黨人向能源和環境保護局施壓,要求其規定加密挖礦公司披露能源和排放的時間表。根據聯邦機構與民主黨立法者之間的信件,聯邦機構有權強制加密礦業公司披露他們使用了多少能源和產生的溫室氣體排放量。
隨著民主黨立法者向聯邦機構施壓,要求其加快計劃,要求加密礦業公司報告其排放量和能源消耗,這種情況可能很快就會改變。這種透明度是控制加密礦污染的早期關鍵步驟。(TheVerge)[2023/2/7 11:52:52]
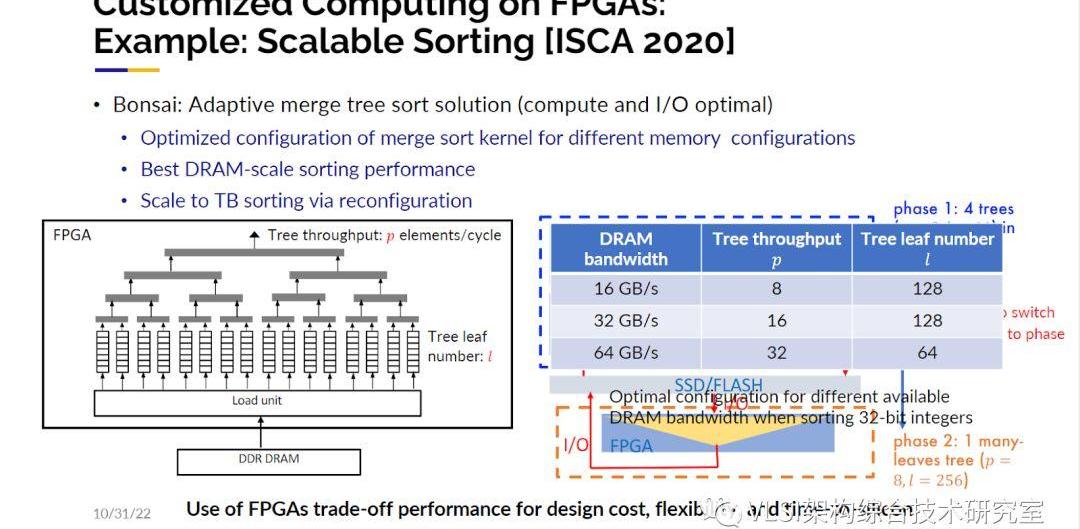
那么在硬件設計層面如何對這個排序算法做特定設計?設計的自由度在于有多少數字需要被處理,以及IO的帶寬有多少。那么映射到這個歸并排序的合并樹就是你有多少的葉子結點以及每個節點的吞吐量有多大。做ASIC對這兩項進行專門設計就比較有難度,我們可以做到的是如果你告訴我需要排序1T字節的數據、100字節記錄實現原地歸并排序我們就可以給你定制一個最優化的歸并樹。定制化的歸并樹設計好之后當你實際去跑這個排序時你會發現1T字節的數據可能裝不進內存里,那又該怎么做呢?最好的解決方案是在以內存的容量為塊的大小在內存里排序,比如說你有256G的內存那么你就排序256G大小的數。那么歸并就會發生在硬盤比如SSD里。SSD和內存比帶寬小了很多,所以從DRAM的排序到SSD的歸并的數據轉移我們可以在線重構FPGA來重新產生一個電路專門解決這個問題,這也是ASIC做不到的。這樣的定制化重構電路僅需要花費1秒鐘,整體的1T字節排序總共花費200秒。相比于現有的CPU,GPU或者其他替代方案我們的方案可以得到最優的性能和最高的吞吐量。這項工作傳達的一個信息就是FPGA可以在設計的開銷、性能和吞吐量之間給出一個較好的權衡考量。我很欣賞斯坦福大學BillDally教授寫的一篇文章《Domain-SpecificHardwareAcclerators》。這篇文章總結了可定制計算的優勢,并且闡述了一些得到高效的可定制設計的關鍵。第一點在于使用特殊的數據類型。比如說AI的推斷通常使用8比特數據類型。我們曾經實現了基因測序的加速。在這個應用中一般會有四種含氮堿基ATCG。我們用2比特的數據類型就可以表達這四種堿基。這可能會帶來10-1000倍的效率提升。第二點在于使用大規模并行計算。比如說在計算矩陣乘法時利用脈動陣列(SystolicArray)架構,其每一個處理單元都可以處理數據。這種處理不是簡單的16路并行而是幾千路并行。這可以帶來極大的性能提升。第三點是優化存儲。不需要使用標準的L1/L2/L3緩存架構。數據就放在優化好的內存里,需要時取出就好了。這為高吞吐量低能耗的可定制計算提供了可能。第四點降低或者平攤額外的處理器開銷。在一般的芯片上做一個加法需要先獲取指令,解碼,然后獲取操作數,再根據其他指令的執行情況安排執行這條加法指令。實際上定制化計算做加法你只要拿到這兩個操作數用加法器加起來就可以了。其他的操作都是額外的處理器開銷。這種簡化的指令執行可以帶來10000倍的效率提升。第五點是定制化計算不使用標準的處理器,既可以根據算法來設計芯片架構,也可以根據架構來考慮各類算法。這兩者是在定制環節中是可以一起考慮的。這幾點加起來就可以提供和傳統標準處理器相比幾個數量級的性能和效率的提升。當然ASIC也有和以上相同的優勢。不過我們之前提過ASIC的設計是一個昂貴又漫長的過程。使用FPGA雖然沒有ASIC的性能提升那么高,但是和一般處理器比性能的提升也是相當顯著的。同時FPGA的設計周期極短,在需要時可以快速重構,成本和ASIC比大大減小的優勢使我們覺得FPGA是讓大多數人可以體驗到可定制計算優勢的首選方案。現在我希望已經讓大家相信:讓軟件工程師為自己的應用設計一款定制化加速器是一件重要而有趣的事情。那現階段軟件工程師可以很容易地設計出專屬的定制化加速器嗎?可能這個問題太寬泛了。很多軟件工程師的工作范圍可能觸及不到對性能的考量,只要設計出的軟件正常工作就可以。但實際上還有很多“認真的”軟件工程師對程序的運行性能有著很高的要求。他們在寫代碼的時候可能會關注處理的數據能不能放進緩存里,是不是要改寫一下循環做循環分塊使得程序跑的更快。這些都是固定于現有架構基于軟件層面的優化。我希望這一類的軟件工程師更進一步不需要很多硬件知識能夠很容易地設計出定制化加速器從來更好地提升性能提高效率。這是我們的目標。只要你懂如何在普通CPU的情況下優化軟件代碼,我可以讓你很容易地設計出你想要的加速電路。我們可以把問題精確到現階段這些“認真的”軟件工程師身上,他們可以很容易地設計出專屬的定制化加速器嗎?我想說答案既是也不是。當我一提到電路設計自動化,你可能會立刻想到高層次綜合(High-levelSynthesis)。這是我們20年前的工作。高層次綜合可以將C/C++轉變成LLVM中間代碼。通過做各種代碼變換、調度安排和片上資源分配就可以得到RTL電路。我們這項工作從一個普通的學術項目xPilot為起點,然后基于它我們創立了AutoESL公司,不斷迭代xPilot變成AutoPilot。之后Xilinx收購了AutoESL,AutoPilot也變成了如今的VivadoHLS/VitisHLS。
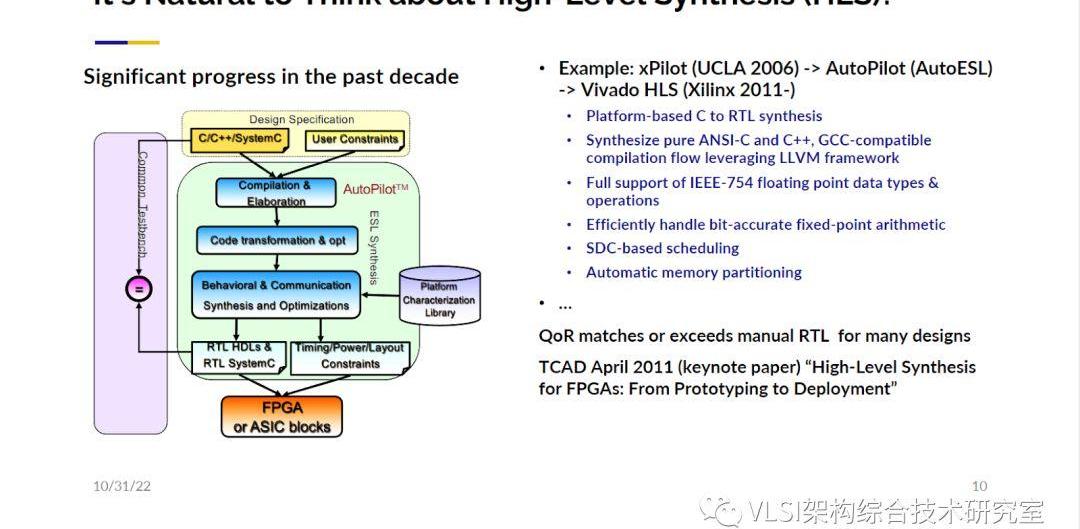
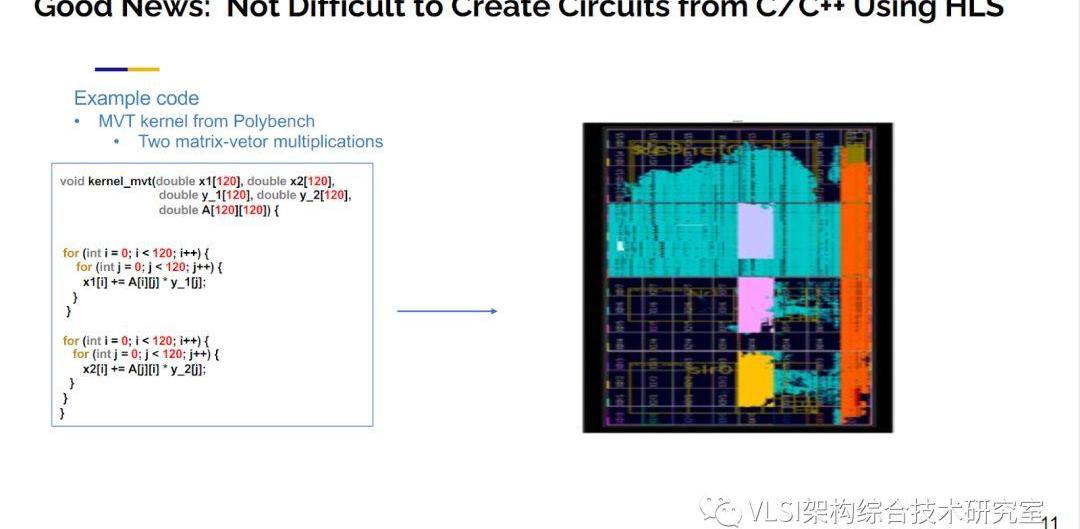
在收購之前Xilinx需要做完善的技術盡職調查。他們不僅自己在內部進行了測試,也雇傭了BerkerlyDesignAutomation來進行第三方測試。測試的結果表明高層次綜合的結果(QoR)可以和手工設計的電路相媲美。IEEETCAD將我們的最初驗證結果作為主旨論文發表在其2011年4月刊上。你可以在這篇文章里看見參照設計和高層次綜合生成設計的對比結果。高層次綜合確實是個好消息。利用高層次綜合可以很輕松的將C/C++程序轉換成電路。比如說下面這個Polybench的例子。這個例子中有兩個做矩陣乘法的循環。使用高層次綜合,你按一下按鈕就可以得到一個FPGA的設計,這條路已經完全自動化了。
俄羅斯國家杜馬官員:加密禁令實為確保公民主動申報加密交易以受法律保護:據此前報道,俄羅斯國家杜馬正在考慮發布一項完全禁止加密交易的修正案。俄羅斯國家杜馬金融市場委員會主席Anatoly Aksakov對此表示,俄羅斯央行確實仍然反對將加密貨幣合法化,但修正案實際上是為了確保公民申報他們的加密交易,如果不申報加密貨幣財產,就意味著這些資產不受俄羅斯法律保護;不申報不會自動導致指控。
Aksakov還暗示,申報持有加密貨幣將授予所有者財產權,且根據新提案加密貨幣是可以被繼承的。在加密貨幣被盜的情況下,合法的所有者將有權上訴法庭。(Cryptonews)[2020/5/29]
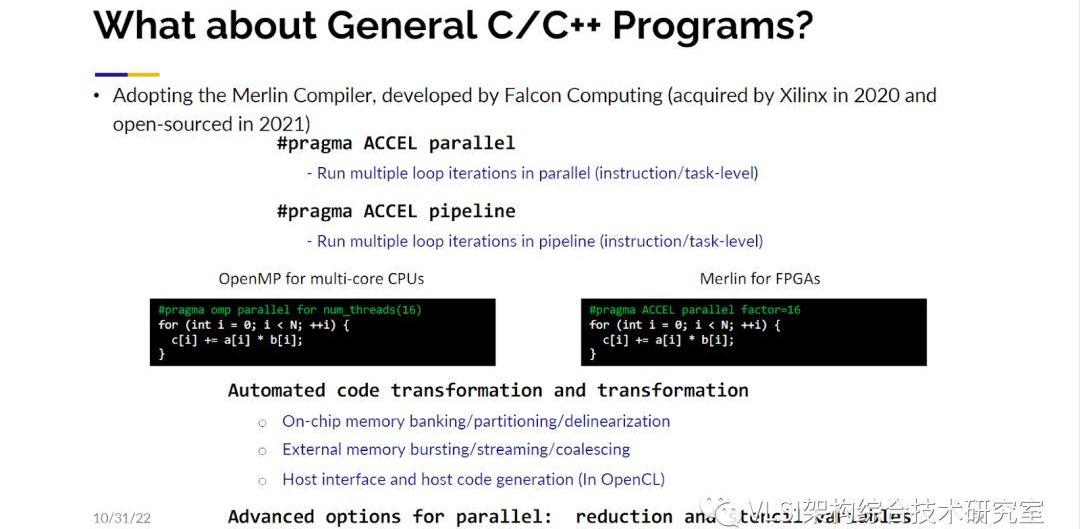
然而這并不是故事的終點,不然我今天的主題報告到這里就結束了。實際上你會還會遇到以下幾個挑戰。第一個挑戰在于,當你原原本本地將軟件代碼放進高層次綜合工具,點完成按鈕測試了一下性能,發現這個電路比單線程CPU慢了13倍。那設計這樣一個比CPU還要慢的加速器又有什么意義呢?順帶一提CPU一般的運行頻率是2-4GHz,而FPGA的頻率是300-500MHz。這樣的性能差別其實很常見。在座的各位如果寫過并行程序如OpenMP的話,會發現你寫的第一個程序在16核CPU上并不會提高16倍的效率,甚至你可能幾乎看不見有任何性能提升。你要做的事情是去做運行時間分析(profiling)。然后你會發現你需要給程序添加一些prgama來指明哪段代碼可以并行執行,哪些需要做規約(reduction)等等。高層次綜合工具也提供了類似的pragma寫法。在下圖的例子里我們就對兩個循環添加了pipeline,parallel和parallelwithreduction三種pragma。我們回過頭來再看加了pragma的代碼產生的RTL發現性能提高了120倍。順帶一提這些pragma和Vitis_HLS的pragma略有不同。我們使用了Merlin編譯器來產生這些電路。Merlin是我們另外一家公司峰科計算(FalconComputing)的產品。Xlinx在兩年前收購了峰科之后也將Merlin編譯器開源供各位試用(https://github.com/Xilinx/merlin-compiler)。Merlin編譯器的好處在于它自動實現了一般高層次綜合手寫才能做的很多代碼優化,需要額外添加的pragma數量和一般高層次綜合相比大大減少。你們可以看見這個例子只用3個pragma就可以了。Merlin的pragma只有簡單的pipeline,parallel和tiling三種。總的來說我們想告訴大家的是軟件代碼需要添加合適的pragma來產生高性能的RTL電路。

現在你說,好,如果我添加三個pragma就可以產生120倍性能提升的電路,那么我怎么知道在哪里添加什么pragma呢?這就涉及到我想說的第二個挑戰。以Merlin編譯器為例子,我們已經知道Merlin只有pipeline,parallel和tiling三種pragma,你可能需要在每個循環上把這三種pragma以及對應不同的參數都試一遍。就算你的程序很簡單只有四五個循環,這樣的求解空間都是指數級。對于我們圖示的簡單例子可能就有超過三百萬種設置,一個個手工窮舉并不是一件合理的事情。那我們怎么來解決這個挑戰呢?

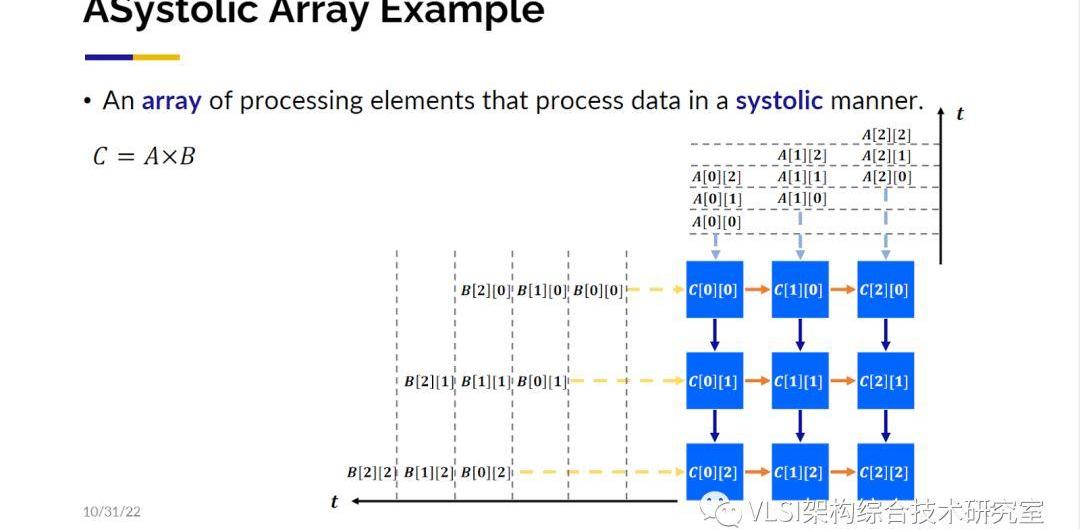
下面我想介紹一下為了解決這個挑戰我們做的幾方面工作。為了民主化可定制計算:即讓大家都可以用!我們希望不僅是C/C++語言能用來設計電路,更上層的語言或工具比如TensorFlow,Halide,Spark等都可以用來描述和設計電路。然后對這些更高層次的語言有一些通用的中間表示層如HeteroCL/MLIR。我們之后會詳細描述這些工作。我會從三個不同的角度來描述我們的工作。第一個角度我稱之為架構導向優化(ArchitectureGuidedOptimization)。如果我知道某些特定的架構模板對特定的應用有很大優勢那么我就使用這些特定模板。這樣的例子包括脈動陣列(SystolicArray,DAC‘17)和模板計算(Stencil,ICCAD’18)。還有一類新的架構我們稱之為可組合可并行可流水架構(CPP,DAC’18)。第二個角度,我們的初步研究相信利用機器學習或者深度學習來進行優化設計是有可能的,我們之后會提到相關的工作。第三點基于上述兩個角度,我們希望可以把各種加速器快速地組合在一起,我們也有一些相應的工作。我們的目標是使得軟件工程師可以在他們熟悉的高層次語言描述上可以一路到底暢通無阻的生成他們需要的高性能加速器。首先來談談第一個角度,架構導向優化。我們的工作的其中一個例子是AutoSA。這項工作主要是深度學習的高層次代碼核(Kernel)映射到脈動陣列上。脈動陣列在上世紀70年代由H.T.Kung教授和CharlesLeiserson教授提出并給出了形式化的定義。大概的意思是數值的計算是可以像心跳一樣舒張收縮脈動化的,比如在3x3矩陣相乘時,行列向量之間錯拍輸入處理單元(PE),結果可以按節拍輸出(譯者記:行列輸入分別在1,2,3拍進入,按列為單位輸出分別在第3,4,5拍,第4,5,6拍,第5,6,7拍產生)。
央行鄒平座:區塊鏈推動實現經濟制度的民主化:近日,中國人民銀行金融研究所首席研究員鄒平座在接受采訪時表示,區塊鏈賦予每個人分布式賬戶,用以管理和核算人的價值,從而實現經濟制度的民主化。股票是一種以股權為分配紅利的憑證,但是數字經濟背景下,每個人的數據具有價值,參與分配,就出現了以人的價值憑證-通證(token),它是人的價值憑證,用區塊鏈核算。這個轉變改變了人類的分配制度,使得每個人都有參與分配的權利。每個人的大數據是科學計量的,本質上反映一個人創造價值的能力。通證經濟將使人類社會的文明前進一大步,充分發現人的價值,更好管理人的價值,更多創造人的價值。在這種制度下每個人都有一基于個人價值的自由權利,不再有剝削和不平等。(證券時報)[2020/3/22]
為什么我們對脈動陣列這么感興趣呢。因為這里面包含了很多大型矩陣和大量的并行處理,這帶來了性能提升。谷歌的TPU就是基于脈動陣列的架構進行設計的。脈動矩陣的另一個關注點在于局部臨近計算,這優化了能耗。對傳統芯片設計主要的性能影響指標并不是門的速度而是導線的速度。脈動陣列的布線只連接了相鄰的處理單元。所以現在幾乎所有的,包括谷歌、特斯拉和亞馬遜的深度學習加速器都在基于脈動陣列來設計。雖然脈動陣列的原理很簡單,然而要設計出一塊好的脈動陣列加速器并不是一件容易的事情。下面這幅研發周期分析圖來自英特爾,他們展示了從包括C,OpenCL,Verilog,SystemVerilog等語言開始到生成硬件電路的研發周期。其中紅色高亮的三個設計使用到了脈動陣列。我們可以看到研發這樣的電路少則4個月,多則18個月。設計出的可能只是一個性能還可以的電路,不是最終完全調優的電路。我們希望自動化這一步驟。實現自動化的挑戰在哪里呢?挑戰在于不僅僅可以設計出一個脈動陣列的電路,而且是根據不同參數自動設計出最優的或者接近于最優的電路。所以我們提出了設計空間的概念。比如說你有輸入數組的參數以及所有可能的脈動陣列參數等等,這些參數的笛卡爾積就構成了一個待求解的設計空間。我們的工作已經可以在這個求解空間內自動尋找最優解或者接近于最優的設計。接下來的工作我們又分成兩大步驟,一個是計算管理,另一個是通信管理。對于計算管理我們這里用一個三循環的矩陣乘法來展示一下工作原理。這里第一個需要考慮的問題就是時間-空間映射。對這三個循環,你需要決定哪幾個循環可以映射到二維的空間域上同時計算,哪幾個循環映射到一維時間維度上在處理器上進行常規的時間循環。解決這個問題我們使用了多面體模型(PolyhedralModel)來分析數據依賴,然后做一定程度上的窮舉來縮小求解空間從而劃出存在著最優解的子集。
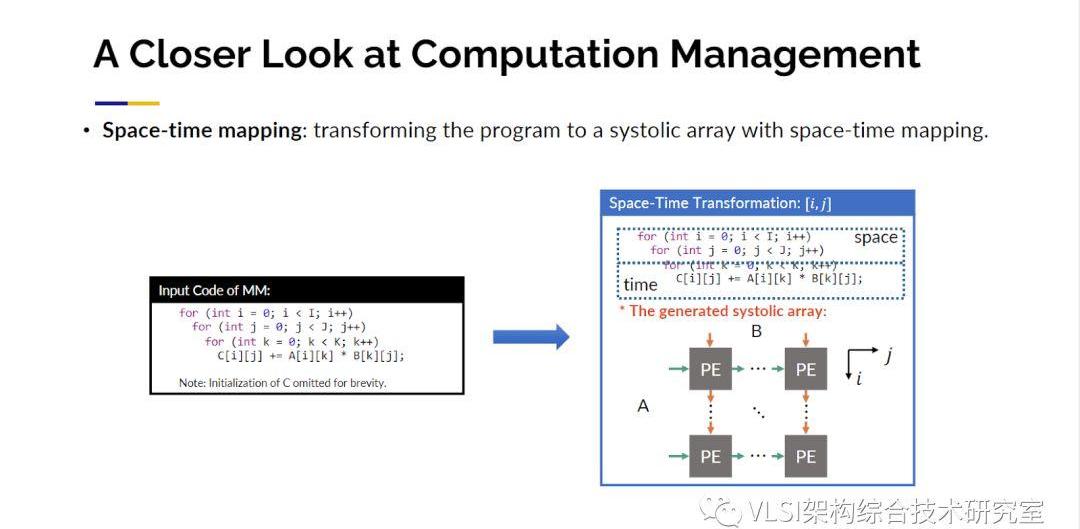
第二個需要考慮的問題是數據量。你的數據量可能特別大,比如說你需要處理10x24x24字節的數據,因為數據量大可能沒有辦法做到計算單元和每一個數據的對應。你可能需要創建多個小一點的數組作為替代,我們稱之為數組分塊(ArrayPartition)。見圖中的實例你可以把循環劃分出一個個小塊并在每一個小塊上產生一個新的循環。這里我們會對產生多大的小塊這一參數進行優化。這還沒有完,第三個需要考慮的問題就是時序。真正的電路并沒有像當前時刻做計算然后傳到右邊的鄰接節點然后在下一個時刻做新的計算這么簡單。很多的運算比如說浮點數加乘需要花費好幾個時鐘周期。如果不做任何優化,相鄰的處理單元可能需要等上5-10時鐘周期才能得到數據。一個更好的方式是我先開始計算一部分數據,比如說要花8個時鐘周期。接著我立刻在下一時鐘周期對一塊沒有數據依賴的獨立區域進行計算,這樣每個時鐘周期我都能給相鄰的處理單元一些數據。這就意味著你可能需要額外再分離出一些循環來實現上述操作,我們稱之為延時隱藏(LatencyHiding)。最后你的脈動陣列處理單元不一定只能做一次加乘操作,這其中可以進行SIMD處理。你可以有一個向量來同時處理16個運算。這也會產生額外的循環我們稱之為SIMD循環。以上就是我們在計算管理上幾個角度的考量。這些考量合在一起就形成了一個大的自動化求解空間。你也可以看見因為空間很大,我們也需要花一些時間來找到最優或接近最優的脈動陣列電路設計。

到現在為止對數據計算管理就有這么多的選項,對數據傳輸通信呢?其實傳輸通信才是關鍵,因為你要保證數據只在相鄰的處理單元之間傳遞而不是廣播數據。我們通過做依賴分析來解決這個問題。你可以在這個矩陣乘法的例子中發現A和B矩陣各自都有讀后讀依賴(Read-after-Readdependency)。一般來說在CPU中我們對讀后讀依賴不是很看重,但在脈動陣列設計中這非常重要。接著我們發現操作中還有寫后讀的依賴(Read-after-Writedependency)因為C矩陣是在循環之間累加的。最后不同的數值會寫在C矩陣不同的位置上。接著你就能得到下圖中的這張表來發現哪一個I/O組有著怎樣的數據依賴關系。
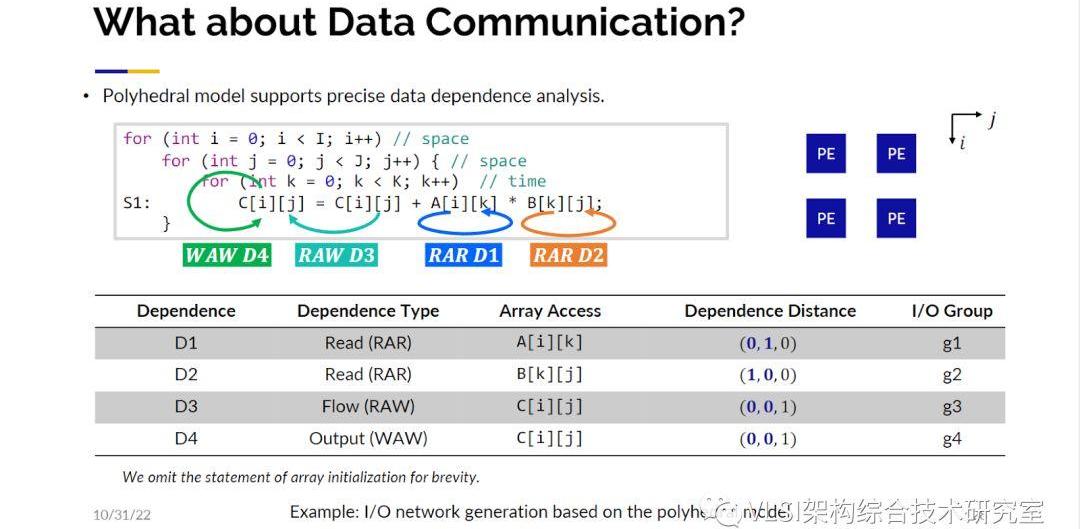
有了這張表你就可以知道如何構建網絡架構。比如說根據你的依賴向量你發現依賴是沿著j軸的那你就可以沿著j軸傳輸數據流。同理如果依賴沿著i軸那么就沿i軸傳輸數據流。這些分析都是通過多面體分析得來的,基于這個分析得出的傳輸網絡我可以保證是依賴正確,同時只有相鄰處理單元有數據傳輸。當然所有計算完成之后數據會被讀回去。我在這里不會詳細展開這個分析但是我很樂于分享相應的論文給大家參考。以上的步驟中有些參數是我們需要去調整的。其中很重要的是循環分塊(looptiling)的參數。你需要決定執行循環的數組的維度是多少。為了找到這個參數我們采取了一種混合方法。首先我們用一個數學優化求解器,然后我們做進化搜索,因為找到的參數可能存在無法整除的情況。我想強調的是之所以我稱之為基于微架構的優化是因為一旦你定義好了微架構的模板我就可以根據這個架構來快速準確的估計設計電路的性能。這使得使用數學求解器成為了可能。我們目前已經將AutoSA開源(https://github.com/UCLA-VAST/AutoSA)。歡迎大家來試用這個工具,并給這個工具添加新的功能。我也可以告訴大家當你擁有了這樣的基于具體架構的空間求解器你可以得到一些令人驚訝的結果。其中一個新洞察是物理數組的大小應該是多少,這個大小一定需要是總體數據大小的因數嗎?比如說總大小是1024,是不是只能去嘗試2、4、8、16這樣的因數作為物理數組的大小呢?實際上有不少文章是基于這樣的假設來做設計空間求解的。這些文章也發表在了頂級的期刊或會議上。但是我們證明了這條假設不是一定正確的。原因很簡單,如下圖所示如果一個4x32的設計是可以裝進FPGA的,8x32則裝不下,在這個設計里如果你用一些非因數參數(13x16)反而有更好的效果。這個矩陣乘法的例子我們可以很明確地告訴大家根據純因數參數最好的設計參數為32x4x8(行,列,SIMD),但如果你選一些奇怪的數字比如說16x13x8我們甚至可以獲得50%的性能提升,這是令人意想不到的。
分析師:比特幣或因民主黨“撒錢”的提議而受益:美國民主黨女眾議員Maxine Waters提議,每月向美國每個成年人提供2000美元,向每個兒童提供1000美元,以幫助他們度過COVID-19金融危機。加密貨幣分析師Mati Greenspan表示,這似乎是一種偽裝后的普遍基本收入,會導致巨大的通貨膨脹,從長遠來看,比特幣肯定會受益。基本上,任何能夠在貨幣貶值的情況下保持其價值的東西——特別是由于政府和銀行的糟糕判斷,肯定會加強對比特幣的支持。(CoinTelegraph)[2020/3/19]

另外一個驚人的洞察是很多人知道片外的存儲轉移是很重要的。不對此進行優化很難得到最優化的設計。很多人說只要最小化存儲轉移的量我應該就可以得到最優化的設計。當然也有一些文章是基于這樣的假設。再一次地,我們證明了這不一定永遠正確。我們還是使用剛才的例子,如果你計算一下數據移動你會發現第二個設計有著更高的移動。這是一個高計算密度的應用所以計算量是很重要的,增加的數據移動保證了所有的計算單元都被有效利用了。以上例子顯示了有些工作如果你如果沒有用到空間求解你可能就無法真正研究到這種設計細節。順帶一提,我們的工作不僅實現了對脈動陣列的優化,而且優化了一些模板計算(StencilComputation)。這些模板計算也在數據管理和通信管理上做到了最優化。希望現在你可以相信脈動陣列我們可以做得很好。但是對于沒有經典架構可以映射的一般程序是否也可以做好呢?在這個問題上我們使用峰科計算開發的Merlin編譯器來解決這個問題。我們將Merlin編譯器設計成和OpenMP類似的使用方式。OpenMP是很多軟件工程師開發多核CPU程序的應用程序接口。我們認為這樣的設計可能是最貼近于軟件工程師使用習慣的。在OpenMP里怎么讓程序并行執行呢?和高層次綜合類似,你用pragma來做這件事情。OpenMP的pragma以”ompparallelfor”為前綴,你可以把它加在需要并行執行的循環之前并指定并行執行的參數。類似地在Merlin編譯器里,我們使用”ACCEL”作為前綴,你可以對循環指定pipeline,parallel和tiling的操作并指定對應的優化參數。比如這里的例子我們就指定對循環做16路并行。Merlin編譯器會自動執行很多的代碼變換。這些變換包括將數據裝入緩沖存儲器(Buffer)、數組劃分(ArrayPartition)、上位機代碼生成等等。這些所有的步驟都是全自動的。對于軟件工程師來說這非常容易上手。
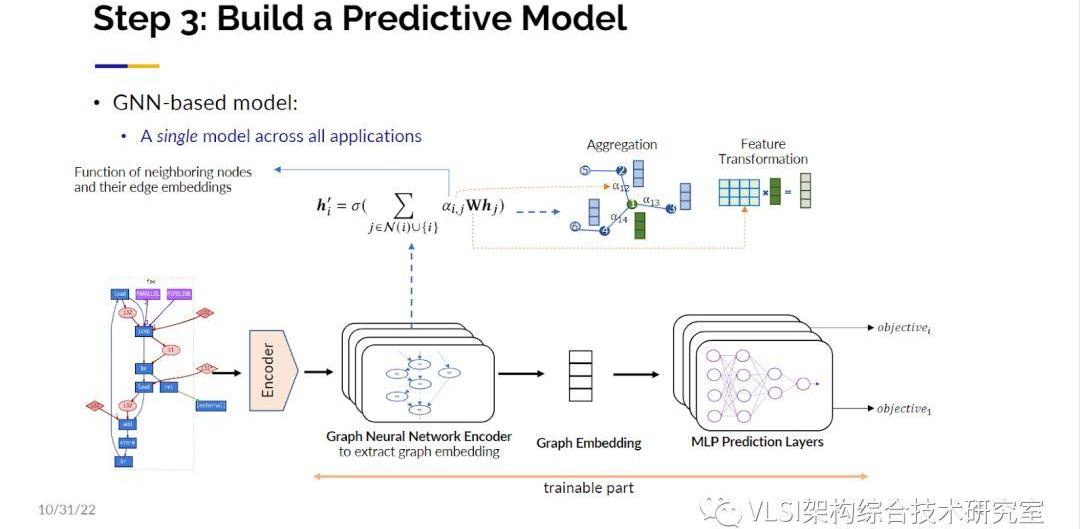
基于Merlin編譯器,我們所做的第一項工作叫自動設計空間求解(AutoDSE)。這項工作也獲得了ACMTODAES2023年度最佳論文獎。AutoDSE的工作原理類似一個專家系統。一般來說如何去設計一個加速電路呢?極大概率你會想從什么pragma也不加開始,當然有可能很幸運的,什么pragma不加就能用Merlin達到性能目標。從一個沒有pragma的程序出發,你先會去看一下Merlin的輸出報告。從報告上不僅可以看見總的時鐘周期,也可以看見詳細到每個循環的時鐘周期分布以及資源使用情況。這樣很明顯你可以發現某幾個嵌套循環占據了大量的延時。知道這一點之后你就會在相應的循環上添加pragma來提升性能。如此循環往復直到獲得滿意的設計。我稱之為基于瓶頸指向的優化設計。AutoDSE可以通過空間求解自動產生pragma及其參數,并調用Merlin編譯器實現了自動化求解。然而AutoDSE有一個限制在于對于每次迭代求解我都必須運行高層次綜合以了解性能。一次執行可能需要10分鐘,有時20分鐘,有時30分鐘,所以一天之內你很難經歷很大量多次迭代,也許最多20-40次。一個設計求解空間中可能有數百萬個點,因此我們認為這可能是深度學習可以提供幫助的地方:我們想要提出一個模型可以給我們正確的性能預測。如果機器學習可以成為最好的國際象棋棋手,也許它也可以成為即將到來的最好的電路設計師。我們實際上研究發現這比下棋要困難得多。因為圍棋雖然是相當具有挑戰性的大棋盤,但它的規則是固定的。但是加速器電路設計,例如編寫算法,都是開放式的沒有固定的規則。你只受你的創造力的限制,所以這是一個更加難的問題。我們的第一個目標是給程序和pragma準確預測性能,這樣我就可以在設計空間里快速迭代。對于AlphaGo的設計師來說最激動人心的時刻還在于,一旦你擁有了棋盤,你就擁有了黑色棋子、白色棋子和規則。一旦他們看見棋盤的局勢他們就可以產生對應的評分函數進行預測,這是他們可以進行機器學習的關鍵。我們也想做同樣的事情,當我看到程序員的程序時,我也想建立一個評分函數對其進行性能評估。另一個問題是我該如何預處理這些帶pragma的程序,你是把它當作一串字符向量、自然語言還是別的什么量化表示。事實上,我發現程序與自然語言非常不同,因為當我在這里說話時,有很多的冗余詞,你可以跳過也許五個詞你仍然可以知道我在說什么。但是對于一個程序它敏感到如果你放錯了分號,你會得到一個非常不同的結果。所以對于程序直接使用自然語言處理并不是一個很好的方式。我們在這里想解的決問題依然是希望能夠自動插入pragma。然后我們快速地搜索這個求解空間。我們要做的第一件事情是創建訓練樣本。這個時候AutoDSE就可以發揮巨大的作用,原因是AutoDSE的求解過程中會產生大量的中間設計結果,我們不僅保留了這些電路的性能指標也保存了這些對應的電路設計。這些AutoDSE生成的樣本電路可以作為我們的訓練樣本,不僅是因為我們進行了針對瓶頸的優化使得這些中間設計仍然是有意義的,盡管它不是最優的。而且我們對有些電路也做了一些擾動使得我們生成的訓練樣本包括好的和壞的設計。我們通過這樣的方式創建包含有幾千個程序的訓練樣本數據庫。我也希望您可以與我們合作,也許在更大的社區范圍內我們可以制作一個更多更大的樣本數據庫。圖神經網絡有很多令人興奮的進展。事實上,我注意到在我的主題報告之后有一個關于圖神經網絡的研討會。我認為這非常及時。我們將把圖編碼成多維向量或者多個多維向量的嵌入(Embedding)。在編碼成向量之前我們需要考慮節點的注意力機制(Attention)、知識跳躍(Jumpingknowledge)等等很多因素。有了這個圖的嵌入編碼,就可以作為高維神經網絡的輸入層,然后把對應的性能指標作為訓練標簽進行訓練了。
聲音 | Block.one CEO:EOS是以代幣為權重的民主:Block.one 的 CEO BB 表示:EOS能夠擴展BTC,POW是繳稅卻無代表權,EOS是以代幣為權重的民主。BB說指出,現有的技術公司不可能在不損失大量利潤的情況下,輕易地整合區塊鏈經濟。展望未來,用戶將是大多數組織的主要受益者,而不是股東;然而,今天的萬億美元級別的公司很難接受這一點。法定貨幣局限性很大,但數字化的、無限可分割、全球可轉移、高度安全、有限的點對點貨幣,例如比特幣,將繼續增加全球價值存儲的市場份額。[2019/1/5]
這樣的做法和純用AutoDSE相比就快多了。我也不必運行高層次綜合就可以做設計空間求解。我們在第一個版本中選擇最好的M個設計,然后對M個設計再進行高級綜合來作為新的訓練數據集。但這還不是故事的結束。對于和訓練集完全不一樣設計使用圖神經網絡我們還是有一些掙扎的。這些測試樣本對于訓練來說屬于域外分布。所以這就是我們想要利用遷移學習(TransferLearning)的地方(GNN-DSE-MAML)。大概的做法是如果你給我一些全新的東西,我要建立一個模型,我必須運行在一些樣本上運行幾次真正的高層次綜合,然后我更新我的模型而不是直接使用已有數據進行探索。
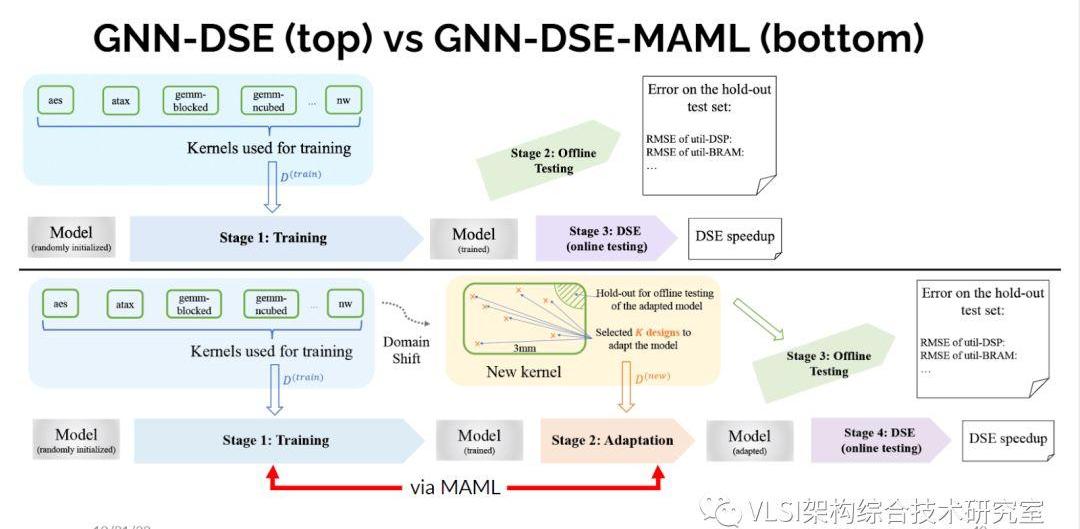
我們這個方法的靈感來源于機器學習中K樣本學習(K-shotlearning)的概念。用早期的分類工具我可以從一百萬張圖像中學會如何區分一千個類別的狗和貓或其他物件。那現在如果我給你一種新動物比如說駱駝,你從來沒有見過你能認出嗎?顯然必須教你一些東西,但也許只要有兩三個駱駝的照片你就可以知道這是駱駝,你以后可以一直分辨出來。如何來做這件事情?基本上你將會有一些動物,每一種都有一些例子。每一個新動物都稱為一項任務,你希望在所有這些任務上都做好。每個任務的樣本數很少,你也想要在這些任務之間做好區分。數學上發生的事情是你迭代所有這些任務,你進行梯度下降,每個任務都會給你一個新的梯度,然后你做某種加權平均然后你取得了訓練進展。在推理時,當你看到一個新任務,基本上是一種新動物或在我們的情況是一個新程序,然后你會先運行幾張圖,找到現有最小化誤差,所以給你另一個梯度,然后你從這個梯度出發來更新現有的模型。

這是我們做自適應的方法。利用這個方法我們得到了魯棒性更好的結果。這個結果是比直接微調更好的。我會說我們還是有優化的空間,尤其是在資源管理部分。因為在某些情況下我們得到了很好的結果,但它已經超出了我們擁有的資源,所以我們必須更精確地處理這些情況。
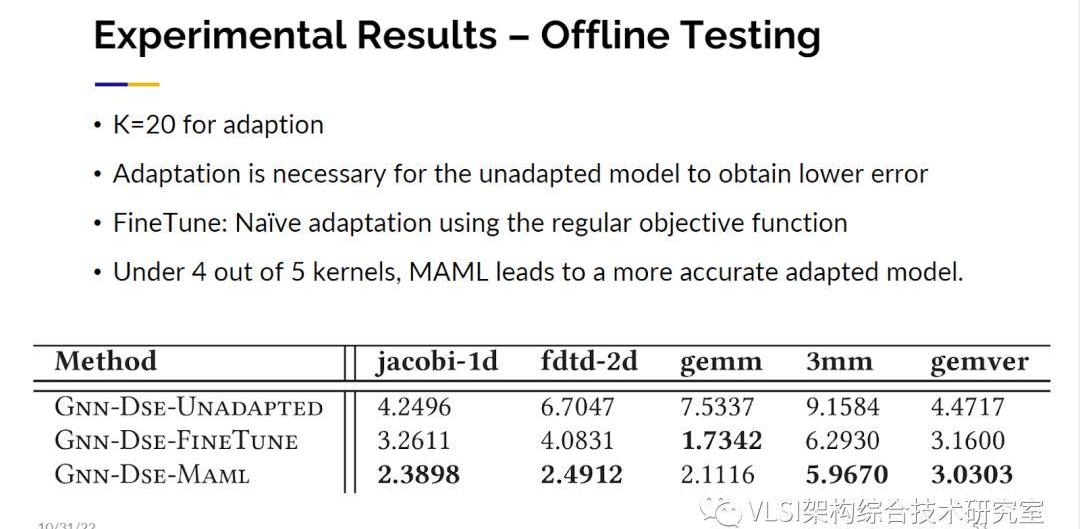
AutoDSE(https://github.com/UCLA-VAST/AutoDSE)和GNNDSE(https://github.com/UCLA-VAST/GNN-DSE)都是開源的,所以如果您有興趣在這個方向繼續研究歡迎您下載試用。
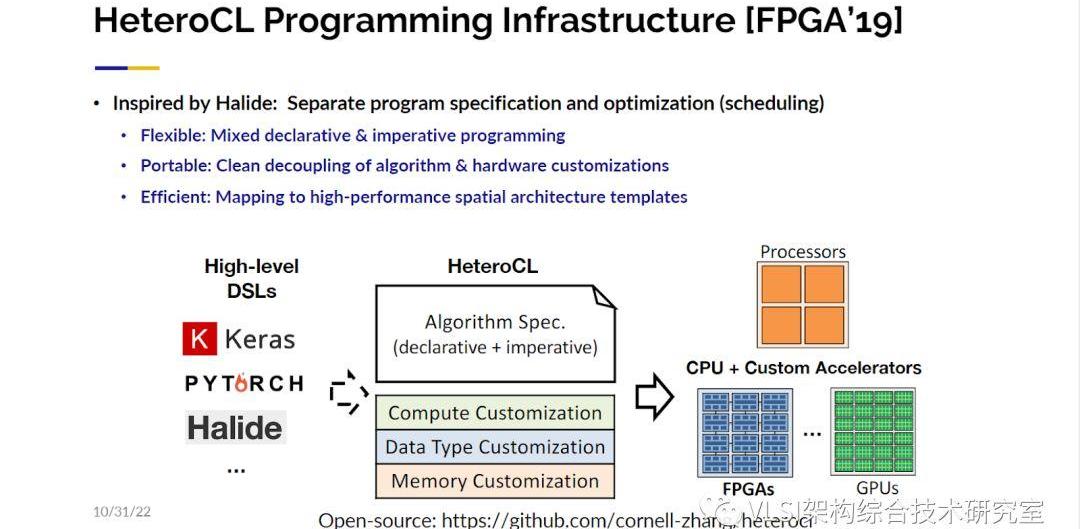
HeteroCL這項工作非常成功,我們將其硬件優化部分擴展到我們的加速器設計。在這里我們主要有三種優化方式。第一種是特定計算的定義。比如我們可以來定義一個循環的展開。第二種是自定義數據類型。你可以很容易地嘗試從2bit到16bit,看看你的輸出結果是什么樣子。我們也可以指定如何復用數據。

接下來我們很快意識到在硬件優化的定義區塊中我們可以給用戶使用微架構的設計自由。比如說其中某些計算可以使用脈動陣列,某些計算可以使用模板計算。這些都是設計模式,和真正的硬件指標比如FPGA中的BRAM或者URAM的使用毫不相關。軟件設計師可以很容易地和他們平常寫設計一樣指定這些模式。其他指定不了的步驟我們將通過自動合成、AutoDSE和機器學習等等技術幫助他們自動完成。最后,在我的主旨報告結束之前,我想再談一個問題:即如何將所有東西搭建在一起。對于一些真正從事FPGA設計的人來說,當你把所有東西放在一起時,性能可能從大約300MHz降至100MHz。而且還需要非常長的時間生成比特流。20小時并不夸張,40小時完全合理。我們最近在這個問題上取得了很大的進步。順便說一句,你不必因為設計錯了什么而感到難過,只是大型的FPGA非常復雜。你可能注意到了一個大的FPGA往往有四個大片(die)而不是一個。如果你的設計出現了跨片的情況整個電路的延時可能一下子就從幾納秒漲到幾十納秒。而且大型FPGA中還有很多IP核在那里阻礙了很多布局布線。比如說你有DDR,控制器在中間,然后你有PCIE控制器在最后與CPU通信。最新的FPGA有32個通道的HBM。那么如何連接到你需要的數據你需要創建一個大的交叉通信模塊,這也會犧牲芯片的性能。有了以上原因,你的FPGA實際表現很差并不是一件奇怪的事情。HLS對這一點的考慮也是有限的。你在編寫代碼和插入pragma時不知道在實際布局布線中你會在哪里出現跨片,在哪里會遇到哪些IP塊。我們的解決方法實際上很簡單。如果你有一根高延時長線我可以通過增加流水線級數來解決這個問題。所以問題轉變為這些長線在哪里。這就是我們要先做布局的地方,這是一個粗略等級的布局。然后利用這個粗略的布局信息作為約束條件來指導全局的優化。從高層次綜合開始實際上是理想的,因為我基于一種抽象表示做調度比較自由。如果我需要兩個額外的時鐘周期我可以將其添加到我的調度解決方案中。這個方法也是比較成功的。現在我們在超過43種設計中看到幾乎是2倍的時鐘周期提升,從150MHz到297MHz。我可以告訴你每一個我實驗室的項目都在使用Autobridge進行FPGA輔助設計,因為學生自然而然能獲得2倍的性能提升。這項工作獲得了FPGA’2021的最佳論文獎。如果你對此感興趣歡迎與你的團隊分享這項工作。
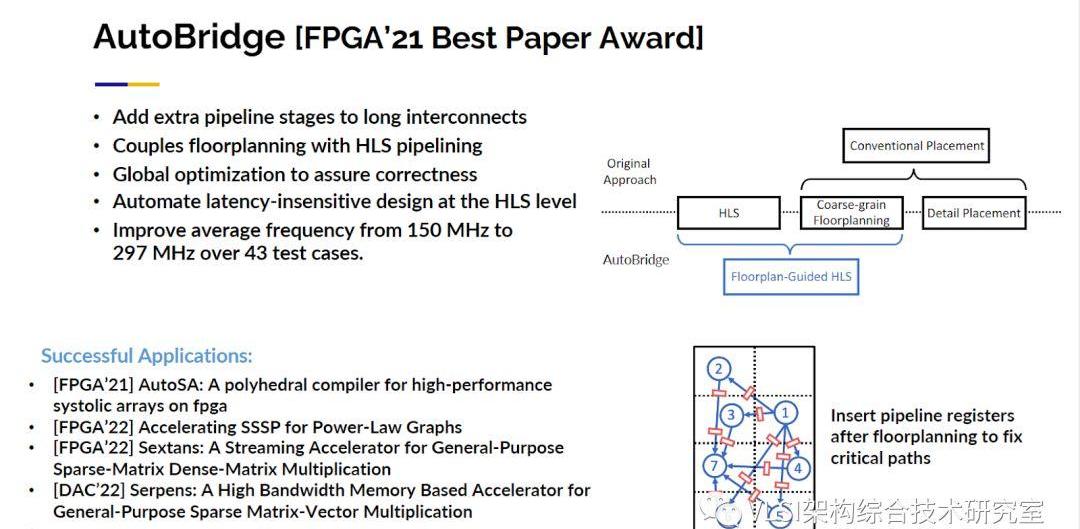
不僅如此我可以繼續向你展示關于脈動陣列的設計討論。從12x12陣列開始到24x24陣列時,在傳統情況下你會發現性能下降,頻率從300MHz開始降至150MHz或120MHz,但用AutoBridge優化后我們的運行頻率基本上保持不變。所以你可以看到圖中的布局布線圖是一個很神秘的部分,左邊的圖中布局布線工具看起來似乎做得很好,他們將所有東西都包裝在盡可能少的片中,但是他們造成大量布線擁堵(Congestion)。我們可以放心地將其分離出來,然后我們將流水線寄存器按需插入設計。
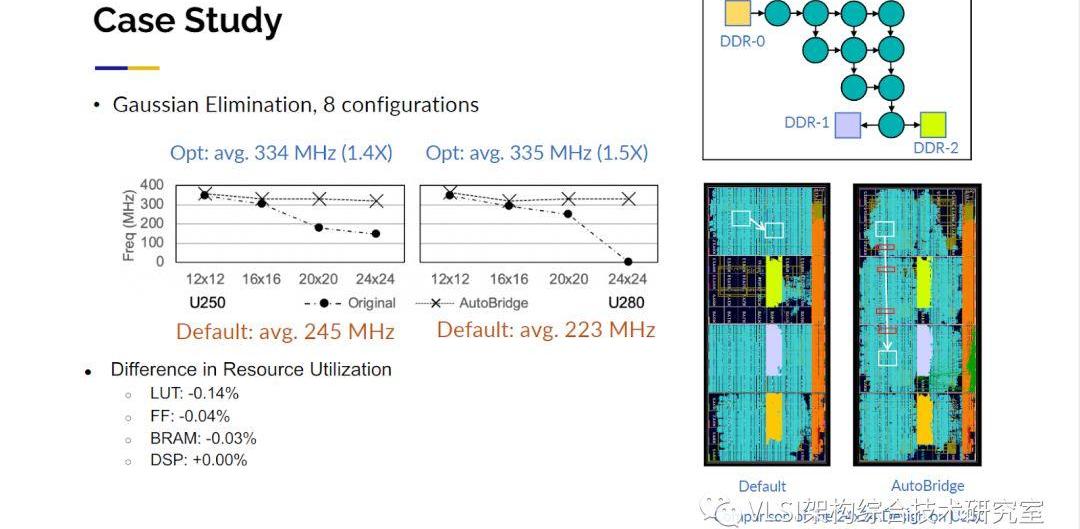
這些我稱之為延遲激勵設計技術,因為你可以容忍比較長的延遲,也可以幫助我們改善布局布線。如果你運行Xilinx工具,你發現它太慢了要40小時,你分析一下CPU使用情況發現你只使用了四個核。你說我有32個核,為什么不使用32個核?因為你無法并行優化各個電路,因為片與片之間存在全局互連。使用這種方法,我們在邊界添加觸發器,因此每個觸發器完全解耦了片間連接,以便我們可以并行運用它們。
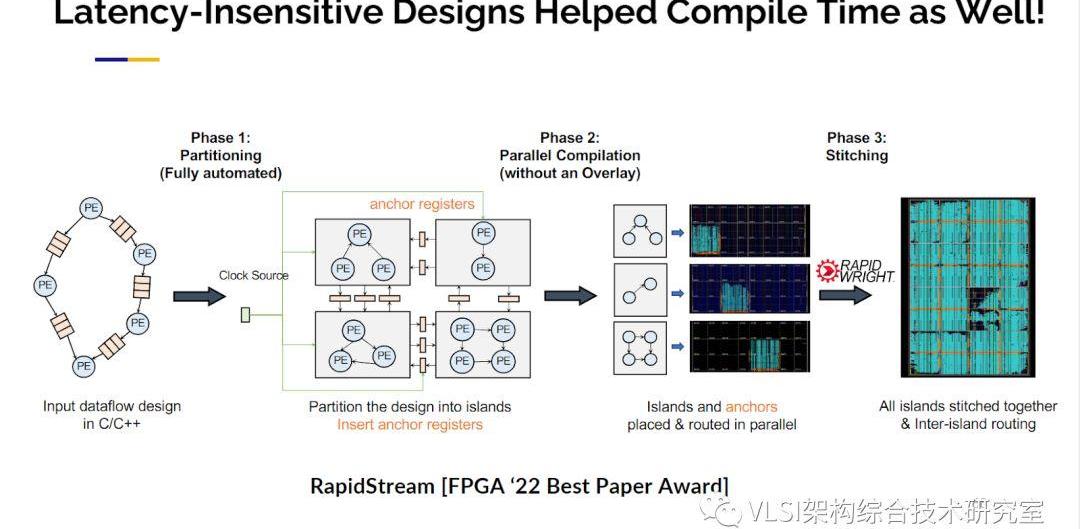
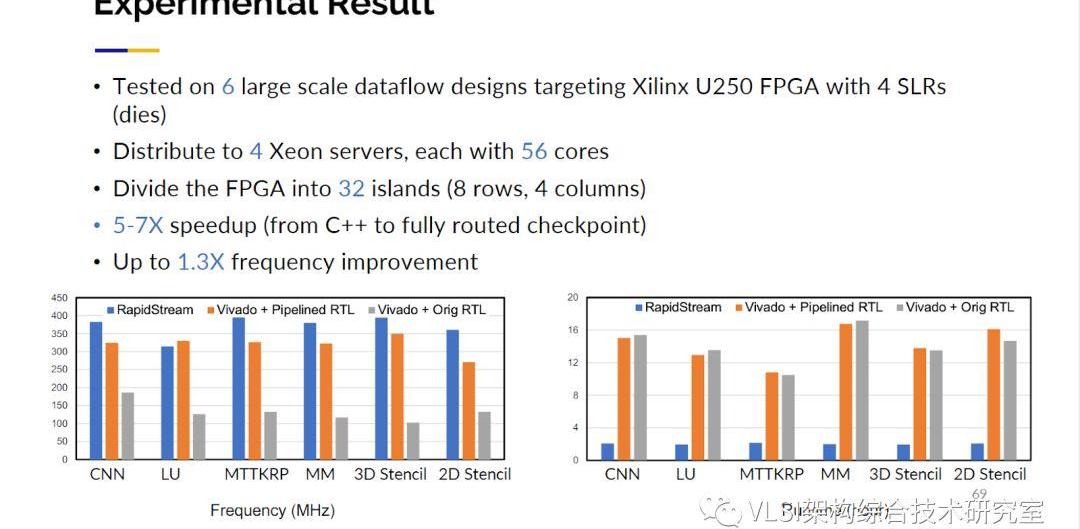
這種技術實際上也可以帶來驚人的結果。我們獲得5到10倍編譯綜合運行速度的提升,我們還獲得了30%頻率提升。
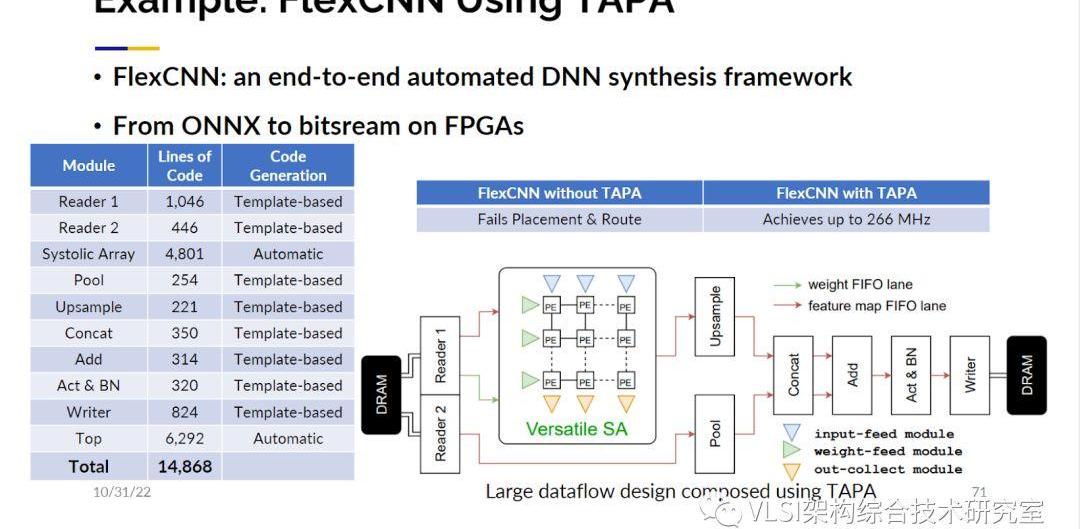
我們還有一個擴展,被稱為TAPA的HLS。基本上我們添加一些模板IO來描述這些數據。從那里進行流程設計,我們可以利用之前提到的技術自動進行延遲激勵優化。我們使用TAPA設計了一個FlexCNN。它共計有14000行代碼,這一切都使用了延遲激勵設計。
最后總結一下,我知道民主化可定制計算這個方向存在的時間很短,但對在這個方向上所取得的進展,我倍感鼓舞。也許我有些偏愛,在報告中我選擇了更多來自我的實驗室所做的研究,但實際上這個領域有著一群共同努力的優秀學者。這確實需要整個社區的共同努力,這就是為什么我們對工具開源這件事情如此強調。我希望聆聽或者是閱讀我報告的人能夠在這個領域繼續添磚加瓦。工業界也正在朝著開源這個方向發展,并且會更加開放,例如英特爾有一個可定制計算API是開源的。同時在我們的鼓勵下,AMD-Xilinx在收購峰科計算之后也開源了Merlin編譯器。我們對使用MLIR作為加速器設計的也越來越感興趣。你們很多人可能都聽過Hennessy教授和Patterson教授在他們的圖靈獎演講中的一句話:“這是一個計算機架構的黃金時代”。這絕對是真的。因為以前你只有微處理器、控制器等一些很少類型的東西可以設計。現在有了所有這些加速器的設計,實際上產生了無限的機會。開源軟件生態:AutoSA:https://github.com/UCLA-VAST/AutoSAStencil:https://github.com/UCLA-VAST/sodaMerlinCompiler:https://github.com/Xilinx/merlin-compilerAutoDSE:https://github.com/UCLA-VAST/AutoDSEGNN-DSE:https://github.com/UCLA-VAST/GNN-DSEHeteroCL:https://github.com/cornell-zhang/heteroclAutoBridge:https://github.com/UCLA-VAST/AutoBridgeTAPA:https://github.com/UCLA-VAST/tapaFlexCNNwithTAPA:https://github.com/UCLA-VAST/FlexCNN參考鏈接:主旨報告演講視頻:https://www.youtube.com/watch?v=qlqjymTcLdI主旨報告幻燈片:https://ucla.box.com/s/8yx0m0v1wtobn0io87jg4xh4sw0fculpWang,Jie,LichengGuo,andJasonCong."AutoSA:Apolyhedralcompilerforhigh-performancesystolicarraysonFPGA."The2021ACM/SIGDAInternationalSymposiumonField-ProgrammableGateArrays.2021.Chi,Yuze,andJasonCong."Exploitingcomputationreuseforstencilaccelerators."202057thACM/IEEEDesignAutomationConference(DAC).IEEE,2020.Chi,Yuze,JasonCong,PengWei,andPeipeiZhou."SODA:Stencilwithoptimizeddataflowarchitecture."In2018IEEE/ACMInternationalConferenceonComputer-AidedDesign(ICCAD),pp.1-8.IEEE,2018.Cong,Jason,MuhuanHuang,PeichenPan,YuxinWang,andPengZhang."Source-to-sourceoptimizationforHLS."FPGAsforSoftwareProgrammers(2016):137-163.Wei,Xuechao,CodyHaoYu,PengZhang,YouxiangChen,YuxinWang,HanHu,YunLiang,andJasonCong."AutomatedsystolicarrayarchitecturesynthesisforhighthroughputCNNinferenceonFPGAs."InProceedingsofthe54thAnnualDesignAutomationConference2017,pp.1-6.2017.Sohrabizadeh,Atefeh,CodyHaoYu,MinGao,andJasonCong."AutoDSE:EnablingsoftwareprogrammerstodesignefficientFPGAaccelerators."ACMTransactionsonDesignAutomationofElectronicSystems(TODAES)27,no.4(2022):1-27.(ACMTODAESbestpaperaward)Sohrabizadeh,Atefeh,YunshengBai,YizhouSun,andJasonCong."Automatedacceleratoroptimizationaidedbygraphneuralnetworks."InProceedingsofthe59thACM/IEEEDesignAutomationConference,pp.55-60.2022.Lai,Yi-Hsiang,YuzeChi,YuweiHu,JieWang,CodyHaoYu,YuanZhou,JasonCong,andZhiruZhang."HeteroCL:Amulti-paradigmprogramminginfrastructureforsoftware-definedreconfigurablecomputing."InProceedingsofthe2019ACM/SIGDAInternationalSymposiumonField-ProgrammableGateArrays,pp.242-251.2019.(Bestpaperawardcandidate)Pal,Debjit,Yi-HsiangLai,ShaojieXiang,NiansongZhang,HongzhengChen,JeremyCasas,PasqualeCocchinietal."Acceleratordesignwithdecoupledhardwarecustomizations:benefitsandchallenges."InProceedingsofthe59thACM/IEEEDesignAutomationConference,pp.1351-1354.2022.Guo,Licheng,YuzeChi,JieWang,JasonLau,WeikangQiao,EcenurUstun,ZhiruZhang,andJasonCong."AutoBridge:Couplingcoarse-grainedfloorplanningandpipeliningforhigh-frequencyHLSdesignonmulti-dieFPGAs."InThe2021ACM/SIGDAInternationalSymposiumonField-ProgrammableGateArrays,pp.81-92.2021.(Bestpaperaward)Chi,Yuze,LichengGuo,JasonLau,Young-kyuChoi,JieWang,andJasonCong."Extendinghigh-levelsynthesisfortask-parallelprograms."In2021IEEE29thAnnualInternationalSymposiumonField-ProgrammableCustomComputingMachines(FCCM),pp.204-213.IEEE,2021.Basalama,Suhail,AtefehSohrabizadeh,JieWang,LichengGuo,andJasonCong."FlexCNN:AnEnd-to-EndFrameworkforComposingCNNAcceleratorsonFPGA."ACMTransactionsonReconfigurableTechnologyandSystems16,no.2(2023):1-32.Sohrabizadeh,Atefeh,JieWang,andJasonCong."End-to-endoptimizationofdeeplearningapplications."InProceedingsofthe2020ACM/SIGDAInternationalSymposiumonField-ProgrammableGateArrays,pp.133-139.2020.
“楊平主動投案時只承認了自己的小部分受賄事實,對其他的違法行為有所保留,妄圖蒙混過關,換一個‘從寬處理’……”日前,廣西壯族自治區鳳山縣召開干部警示教育大會.
1900/1/1 0:00:00文/梁寶欣 7月14日晚,廣州富力地產股份有限公司發布公告稱,本公司于2023年7月14日收到法院裁定,基于本公司經營活動維持正常且未有證據證明本公司資不抵債.
1900/1/1 0:00:002023年7月,緊鄰北京國貿CBD的遠洋集團總部——遠洋國際中心A座,看起來一切如常。頗具時代感的外立墻,高達130米的超高樓,引得行人駐足仰望.
1900/1/1 0:00:00日本有很多老人,他們很孤單,想找個伴。但有些老人太虛榮,太貪心,做了一些壞事。比如,有個62歲的大媽,她整了容,說自己才38歲,還交了120個男朋友,最后被警察抓了.
1900/1/1 0:00:00作者l劉培林 再議日本“失去的20年”由哥倫比亞大學伊藤隆敏和東京大學星岳雄兩位經濟學家共同撰寫、南開大學郭金興教授主持翻譯的《繁榮與停滯:日本經濟發展和轉型》一書,近期由中信出版集團出版.
1900/1/1 0:00:00上周兩市股指震蕩上移,結束磨底完成由弱轉強。周五三大股指漲跌互現,全天維持弱震蕩。盤面上兩市成交9225億元,板塊個股跌多漲少。電信、通信及軟件行業漲幅居前,礦物制品、電氣設備及旅游行業領跌.
1900/1/1 0:00:00


