






 BTC/HKD+3.08%
BTC/HKD+3.08% ETH/HKD+2.67%
ETH/HKD+2.67% LTC/HKD+3.8%
LTC/HKD+3.8% DOT/HKD+3.96%
DOT/HKD+3.96% ADA/HKD+5.12%
ADA/HKD+5.12% SOL/HKD+4.32%
SOL/HKD+4.32% XRP/HKD+4.6%
XRP/HKD+4.6% DOGE/US+5.6%
DOGE/US+5.6%來源:新智元
開源先鋒StabilityAI一天扔了兩枚重磅炸彈:發布史上首個開源RLHF大語言模型,以及像素級圖像模型DeepFloydIF。開源社區狂喜!
最近,大名鼎鼎的StableDiffusion背后的公司,一連整了兩個大活。
首先,StabilityAI重磅發布了世上首個基于RLHF的開源LLM聊天機器人——StableVicuna。

StableVicuna基于Vicuna-13B模型實現,是第一個使用人類反饋訓練的大規模開源聊天機器人。
有網友經過實測后表示,StableVicuna就是目前當之無愧的13BLLM之王!
對此,1xexited創始人表示,這可以看作是自ChatGPT推出以來的第二個里程碑。

另外,StabilityAI發布了開源模型DeepFloydIF,這個文本到圖像的級聯像素擴散模型功能超強,可以巧妙地把文本集成到圖像中。

這個模型的革命性意義在于,它一連解決了文生圖領域的兩大難題:正確生成文字,正確理解空間關系!
秉持著開源的一貫傳統,DeepFloydIF在以后會完全開源。
StailibityAI,果然是開源界當之無愧的扛把子。

StableVicuna
世上首個開源RLHFLLM聊天機器人StableVicuna,由StabilityAI震撼發布!

TRON Stake 2.0即將開啟:據官方消息,波場網絡迎來重大升級,TRON Stake 2.0即將開啟。相對于Stake 1.0,Stake 2.0更加靈活、高效和智能,Stake 2.0顯著提高了波場網絡資源和投票管理的靈活性,降低了用戶操作的復雜程度。
目前,Stake 2.0已在Nile測試網上開啟,Nile測試網的TRONSCAN瀏覽器也已開啟對Stake 2.0的支持,用戶可前往試用和測試Stake 2.0的質押和資源代理相關功能。Stake 2.0正式開啟后,現有Stake 1.0質押獲得的資源和投票繼續有效,已經質押的TRX也能正常贖回。屆時,用戶僅能通過Stake2.0方式質押新的TRX。[2023/3/30 13:35:39]
一位Youtube主播對StableVicuna進行了實測,StableVicuna在每一次測試中,都擊敗了前任王者Vicuna。

所以這位Youtuber激動地喊出:StableVicuna就是目前最強大的13BLLM模型,是當之無愧的LLM模型之王!


StableVicuna基于小羊駝Vicuna-13B模型實現,是Vicuna-13B的進一步指令微調和RLHF訓練的版本。
而Vicuna-13B是LLaMA-13B的一個指令微調模型。

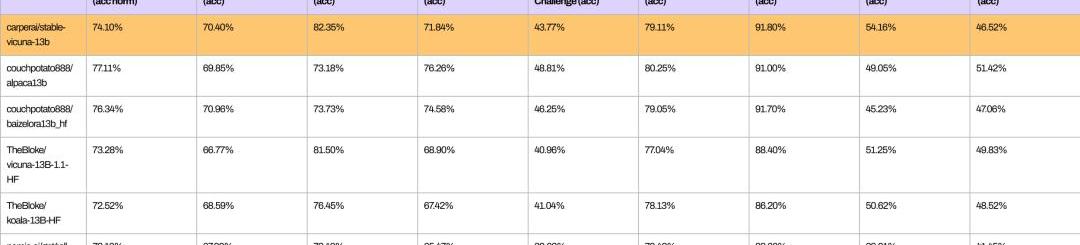
從以下基準測試可以看出,StableVicuna與類似規模的開源聊天機器人在整體性能上的比較。
BSC鏈上項目StableMagnet跑路資產發生異動:PeckShield“派盾”資產追蹤顯示,BSC鏈上項目StableMagnet.Finance跑路錢包發生異動,834,073 DAI 轉至未知錢包,PeckShield“派盾”將持續監控資產動向。[2021/9/16 23:29:21]
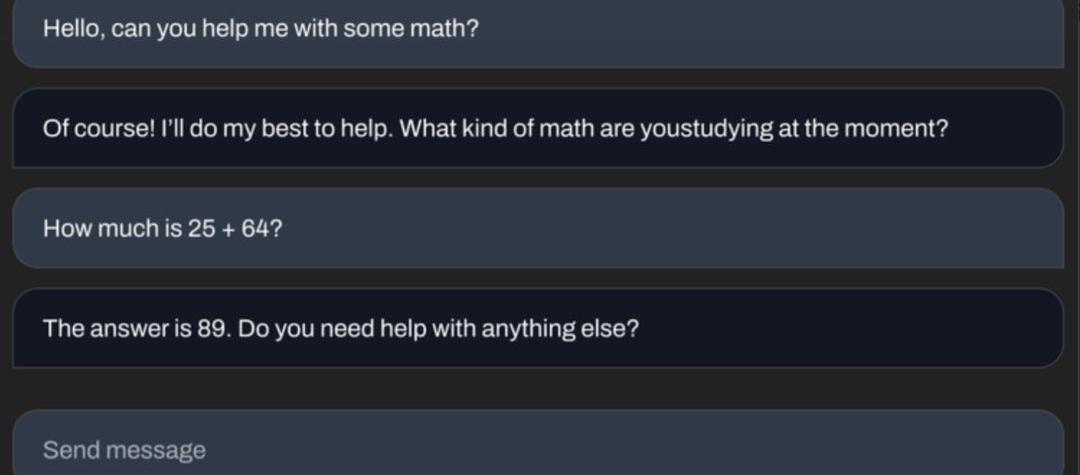
StableVicuna可以做基礎數學題。
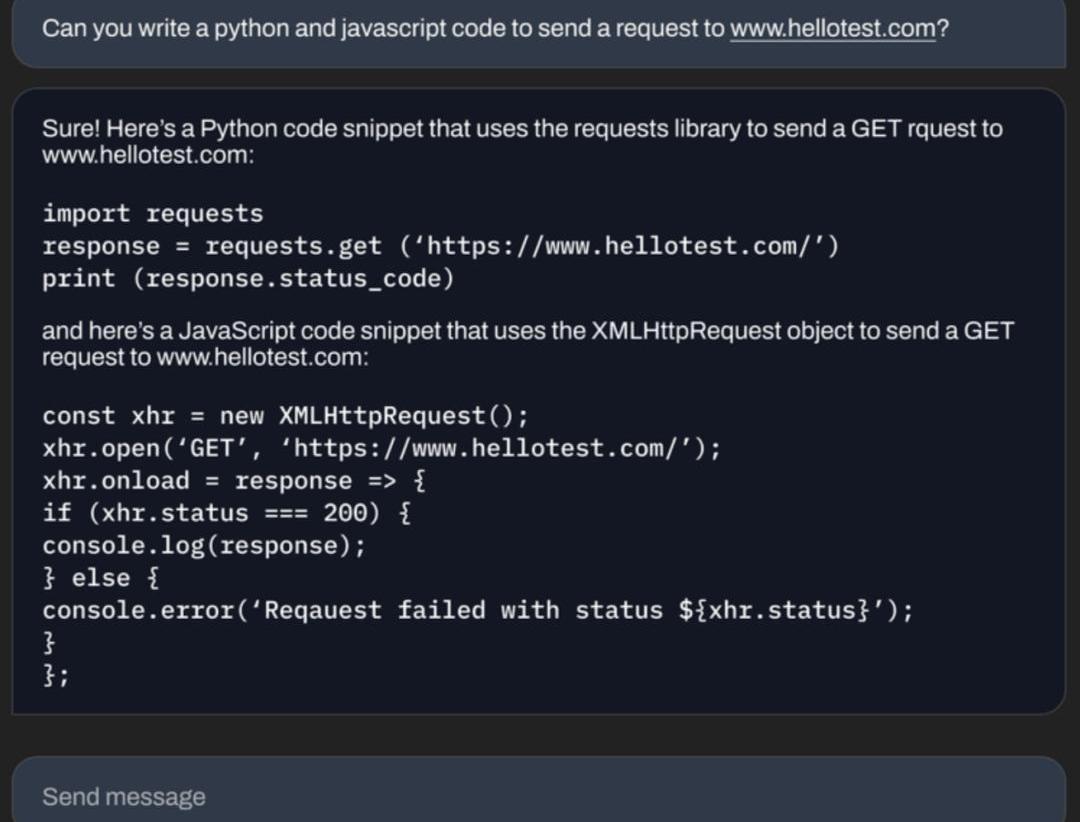
可以寫代碼。
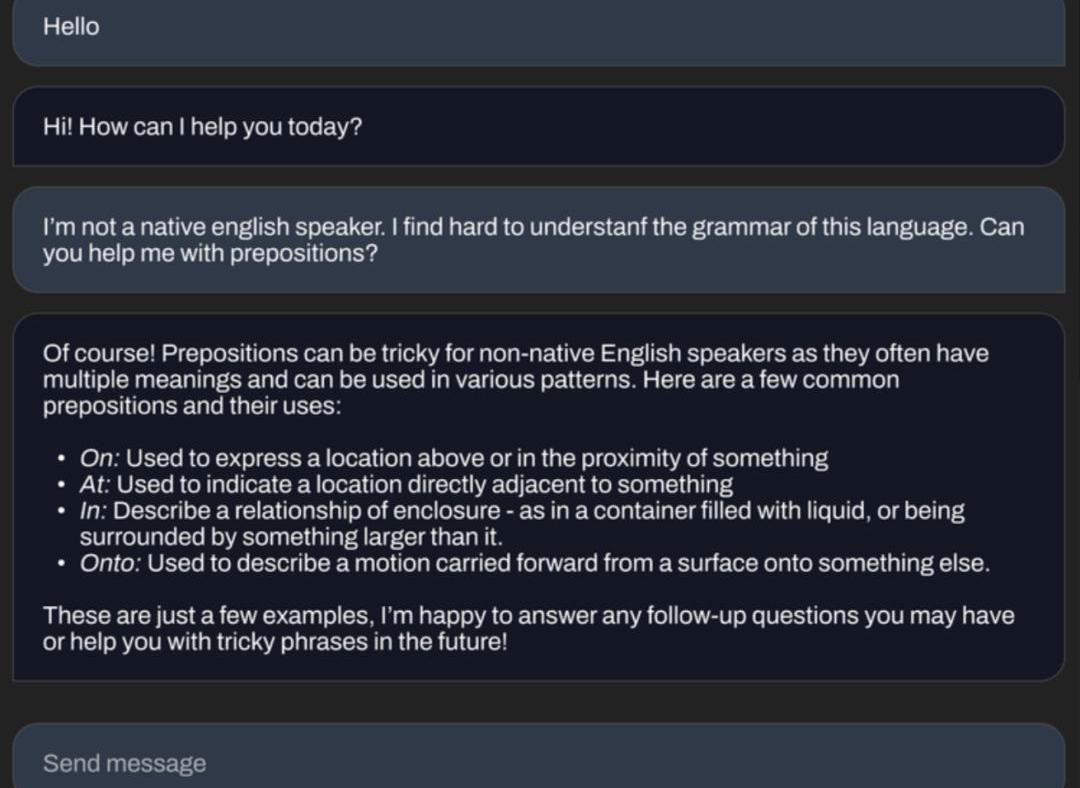
還能為你講解語法知識。
開源聊天機器人平替狂潮
StabilityAI想做這樣一個開源的聊天機器人,當然也是受了此前LLaMa權重泄露引爆的ChatGPT平替狂潮的影響。
從去年春天Character.ai的聊天機器人,到后來的ChatGPT和Bard,都引發了大家對開源平替的強烈興趣。
這些聊天模型的成功,基本都歸功于這兩種訓練范式:指令微調和人類反饋強化學習(RLHF)。

這期間,開發者一直在努力構建開源框架幫助訓練這些模型,比如trlX、trl、DeepSpeedChat和ColossalAI等,然而,卻并沒有一個開源模型,能夠同時應用指令微調和RLHF。
大多數模型都是在沒有RLHF的情況下進行指令微調的,因為這個過程十分復雜。
最近,OpenAssistant、Anthropic和Stanford都開始向公眾提供RLHF數據集。
StabilityAI把這些數據集與trlX提供的RLHF相結合,就得到了史上第一個大規模指令微調和RLHF模型——StableVicuna。
DeFi初創公司InstaDApp籌集1000萬美元新資金:金色財經報道,DeFi初創公司InstaDApp籌集了1000萬美元的新資金,由Standard Crypto領投。投資者還包括DeFi聯盟、Longhash Ventures以及開發者和Yearn創始人Andre Cronje。[2021/6/12 23:32:13]
訓練過程
為了實現StableVicuna的強大性能,研究者利用Vicuna作為基礎模型,并遵循了一種典型的三級RLHF管線。
Vicuna在130億參數LLaMA模型的基礎上,使用Alpaca進行調整后得到的。

他們混合了三個數據集,訓練出具有監督微調(SFT)的Vicuna基礎模型:
OpenAssistantConversationsDataset(OASST1),一個人工生成的、人工注釋的助理式對話語料庫,包含161,443條消息,分布在66,497個對話樹中,使用35種不同的語言;
GPT4AllPromptGenerations,由GPT-3.5Turbo生成的437,605個提示和響應的數據集;
Alpaca,這是由OpenAI的text-davinci-003引擎生成,包含52,000條指令和演示的數據集。
研究者使用trlx,訓練了一個獎勵模型。在以下這些RLHF偏好數據集上,研究者得到了SFT模型,這是獎勵模型的基礎。
OpenAssistantConversationsDataset(OASST1),包含7213個偏好樣本;
AnthropicHH-RLHF,一個關于AI助手有用性和無害性的偏好數據集,包含160,800個人類標簽;
斯坦福人類偏好(SHP),這是一個數據集,包含348,718個人類對各種不同回答的集體偏好,包括18個從烹飪到哲學的不同學科領域。
最后,研究者使用了trlX,進行近端策略優化(ProximalPolicyOptimization,PPO)強化學習,對SFT模型進行了RLHF訓練,然后,StableVicuna就誕生了!
Gate Startup 項目NOA 最高漲幅達1301.12%:據Gate.io芝麻開門行情顯示,截至今日10:40,NOA 24H最高漲幅1301.12%,最高價格0.175美元,為首發認購價格0.035美元的4倍,當前價格為0.03247美元,24H現貨交易量達407.67萬美元。據
悉, Startup項目NOA PLAY (NOA)已于5月21日18:00上線。近期行情波動較大,請注意控制風險。[2021/5/22 22:32:05]

據StabilityAI稱,會進一步開發StableVicuna,并且會很快在Discord上推出。
另外,StabilityAI還計劃給StableVicuna一個聊天界面,目前正在開發中。
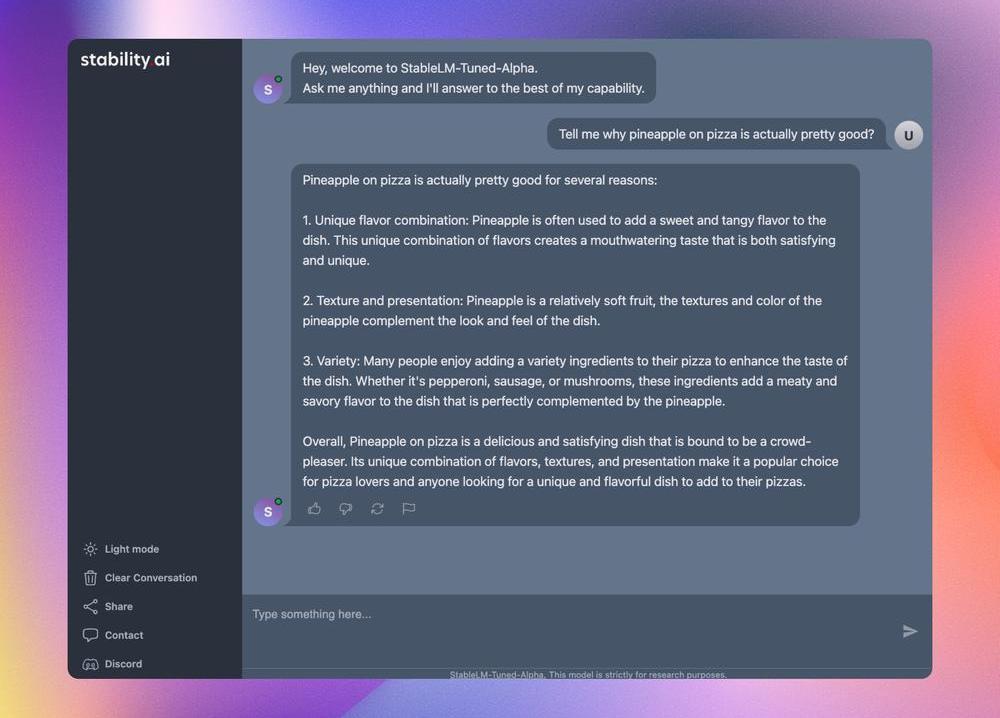
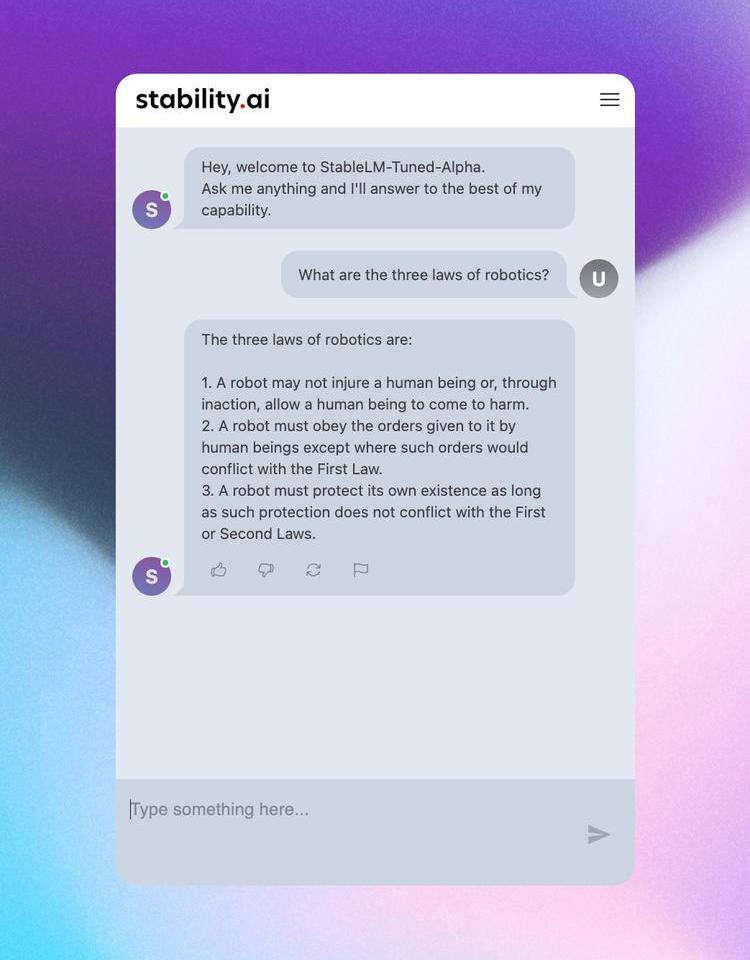
相關演示已經可以在HuggingFace上查看了,開發者也可以在HuggingFace上下載模型的權重,作為原始LLaMA模型的增量。
但如果想使用StableVicuna,還需要獲得原始LLaMA模型的訪問權限。
獲得權重增量和LLaMA權重后,使用GitHub存儲庫中提供的腳本將它們組合起來,就能得到StableVicuna-13B了。不過,也是不允許商用的。
DeepFloydIF
在同一時間,StabilityAI還放出了一個大動作。
你敢信,AI一直無法正確生成文字這個老大難問題,竟然被解決了?
沒錯,下面這張「完美」的招牌,就是由StabilityAI全新推出的開源圖像生成模型——DeepFloydIF制作的。

動態 | StakerDAO 上線 Tezos 主網 正在完成第一個治理周期:鏈上自治 StakerDAO 成功上線 Tezos 主網,目前正在完成第一個治理周期。據悉,StakerDAO 首先是一個決策平臺,STKR 通證持有人可以通過該平臺協作來啟動和管理金融資產。同時,STKR 的持有者有責任每年選舉一個管理委員會,并相當于持有 StakerDAO 在開曼群島經營實體 Staker Services Ltd 的股份。
StakerDAO 在官方博客透露,或在今年 2 月準備啟動 PoS 通證(Tezos-XTZ/Cosmos-ATOM)跟蹤器的提案,并著手研究 Tezos 網絡的算法穩定幣。[2020/1/28]
除此之外,DeepFloydIF還能夠生成正確的空間關系。

模型剛一發布,網友們已經玩瘋了:

prompt:Robotholdinganeonsignthatsays"Icanspell".



不過,對于prompt中沒有明確說明的文字,DeepFloydIF大概率還是會出錯。

prompt:AneonsignofanAmericanmotelatnightwiththesignjavilop

官方演示



順便一提,在硬件的需求上,如果想要實現模型所能支持的最大1,024x1,024像素輸出,建議使用24GB的顯存;如果只要256x256像素,16GB的顯存即可。
是的,RTX306016G就能跑。
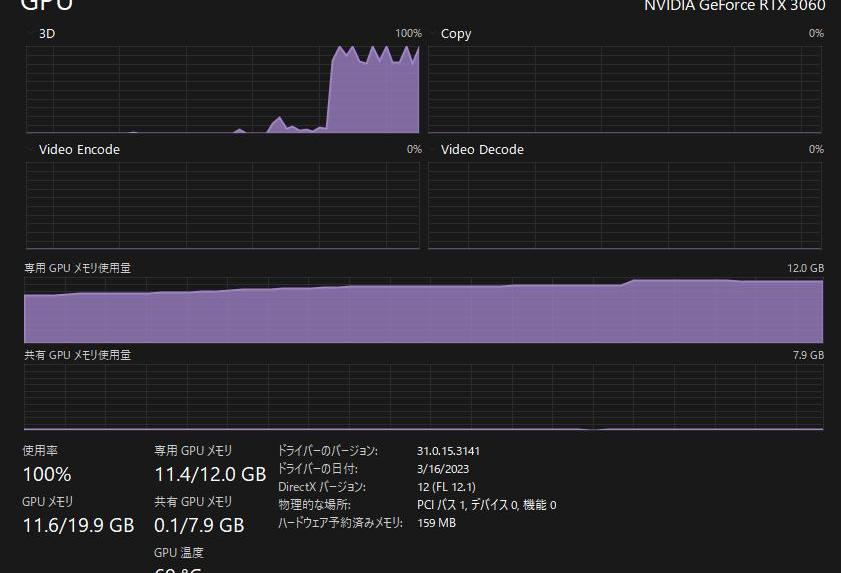
代碼實現:https://gist.github.com/Stella2211/ab17625d63aa03e38d82ddc8c1aae151
開源版谷歌Imagen
2022年5月,谷歌高調發布了自家的圖像生成模型Imagen。
根據官方演示的效果,Imagen不僅在質量上完勝OpenAI最強的DALL-E2,更重要的是——它能夠正確地生成文本。
迄今為止,沒有任何一個開源模型能夠穩定地實現這一功能。

與其他生成式AI模型一樣,Imagen也依賴于一個凍結的文本編碼器:先將文本提示轉換為嵌入,然后由擴散模型解碼成圖像。但不同的是,Imagen并沒有使用多模態訓練的CLIP,而是使用了大型T5-XXL語言模型。
這次,StabilityAI推出的DeepFloydIF復刻的正是這一架構。
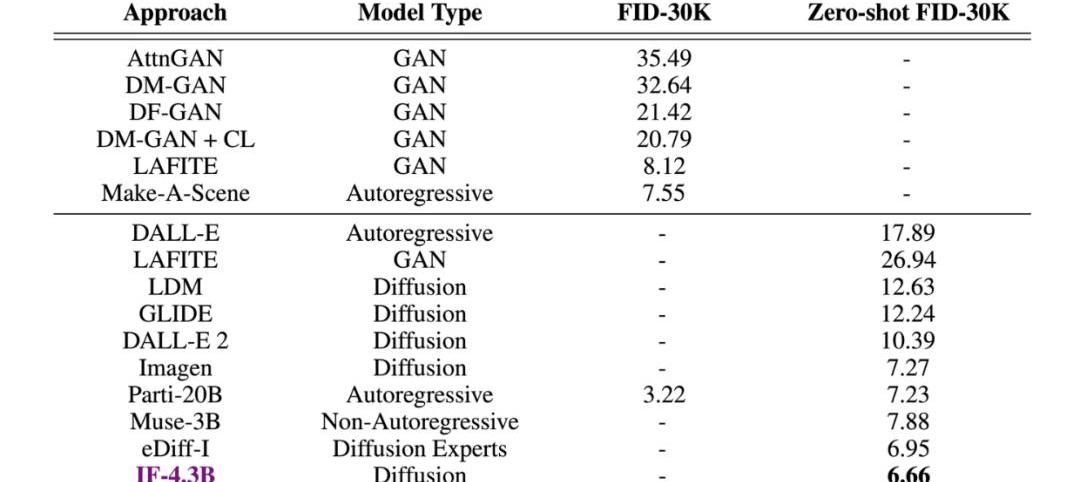
甚至在測試中,DeepFloydIF憑借著COCO數據集上6.66的zero-shotFID分數,直接超越了谷歌的Imagen,以及一眾競品。
下一代圖像生成AI模型
具體來說,DeepFloydIF是一個模塊化、級聯的像素擴散模型。
模塊化:
DeepFloydIF由幾個神經模塊組成,它們在一個架構中相互協同工作。
級聯:
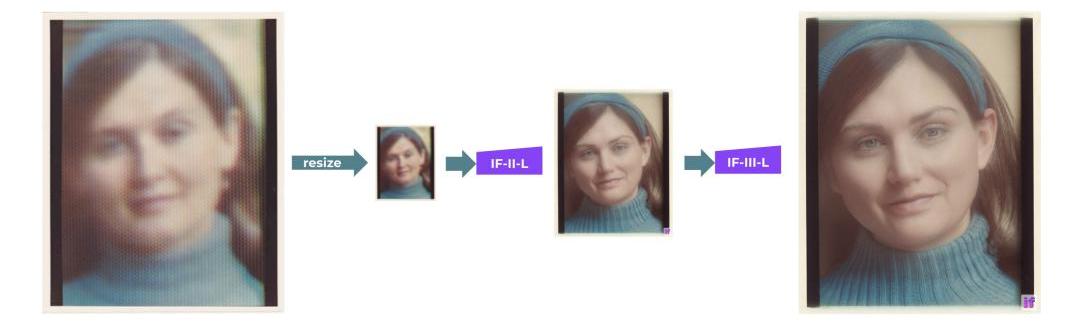
DeepFloydIF以多個模型級聯的方式實現高分辨率輸出:首先生成一個低分辨率的樣本,然后通過連續的超分辨率模型進行上采樣,最終得到高分辨率圖像。
擴散:
DeepFloydIF的基本模型和超分辨率模型都是擴散模型,其中使用馬爾可夫鏈的步驟將隨機噪聲注入到數據中,然后反轉該過程從噪聲中生成新的數據樣本。
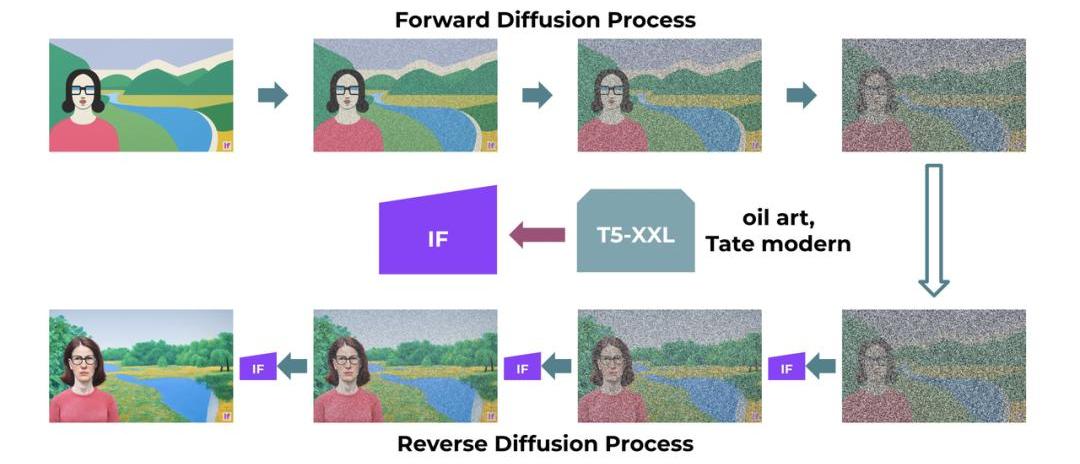
像素:
DeepFloydIF在像素空間工作。與潛在擴散模型不同,擴散是在像素級別實現的,其中使用潛在表征。
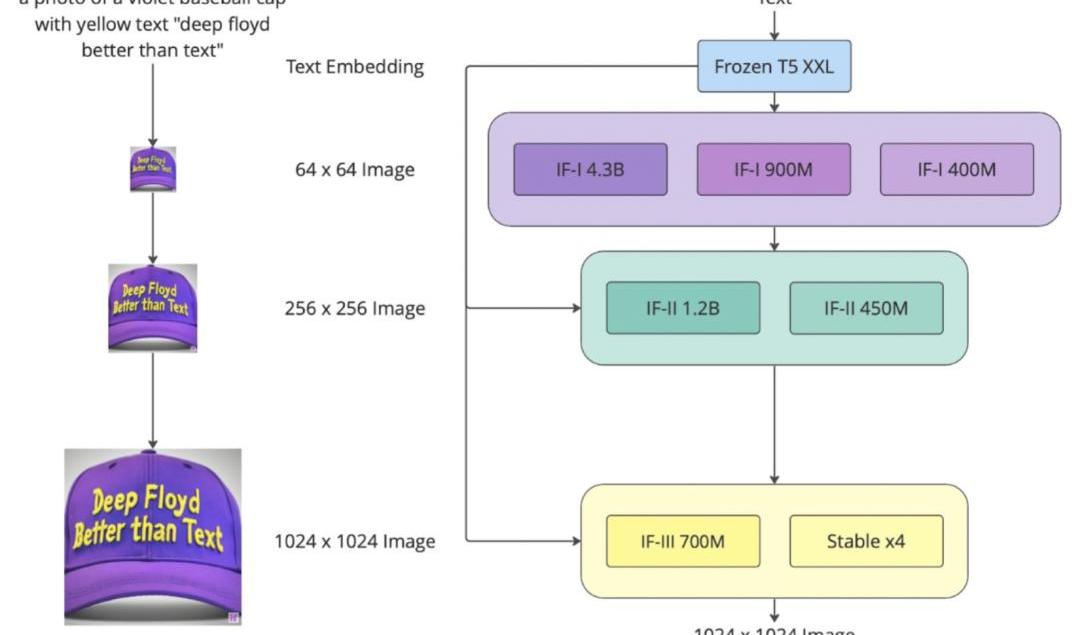
上面這個流程圖展示的就是,DeepFloydIF三個階段的性能:
階段1:
基本擴散模型將定性文本轉換為64x64圖像。DeepFloyd團隊已經訓練了三個版本的基本模型,每個版本都有不同的參數:IF-I400M、IF-I900M和IF-I4.3B。
階段2:
為了「放大」圖像,團隊將兩個文本條件超分辨率模型應用于基本模型的輸出。其中之一將64x64圖像放大到256x256圖像。同樣,這個模型也有幾個版本:IF-II400M和IF-II1.2B。
階段3:
應用第二個超分辨率擴散模型,生成生動的1024x1024圖像。最后的第三階段模型IF-III擁有700M參數。
值得注意的是,團隊還沒有正式發布第三階段的模型,但DeepFloydIF的模塊化特性讓我們可以使用其他上采樣模型——如StableDiffusionx4Upscaler。
團隊表示,這項工作展示了更大的UNet架構在級聯擴散模型的第一階段的潛力,從而為文本到圖像合成展示了充滿希望的未來。


數據集訓練
DeepFloydIF是在一個定制的高質量LAION-A數據集上進行訓練的,該數據集包含10億對。
LAION-A是LAION-5B數據集英文部分的一個子集,基于相似度哈希去重后獲得,對原始數據集進行了額外的清理和修改。DeepFloyd的定制過濾器用于刪除水印、NSFW和其他不適當的內容。
目前,DeepFloydIF模型的許可僅限于非商業目的的研究,在完成反饋的收集之后,DeepFloyd和StabilityAI團隊將發布一個完全免費的商業版本。
參考資料:
https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
https://stability.ai/blog/deepfloyd-if-text-to-image-model
作者:chengshutong一、初聞Ordinals、BTC-NFT、BRC-20這部分是概念的堆砌,雖然可以幾句話講明白,但是還是想從原理的角度,將每一個知識點穿起來.
1900/1/1 0:00:00文: 娛樂獨角獸,作者:赤木瓶子,編輯:把青由AI創作的第一首“神曲”走紅不到一個月,便被唱片公司與流媒體聯合抵制下架,這并不是“賽博戰役”的首次打響.
1900/1/1 0:00:00隨著英國隆重迎來國王查理三世時代,電視報道將主要集中在游行盛典和皇冠珠寶上。但在全國各地,慶祝加冕典禮的方式不再過時,而是更加數字化,不乏有創新者使用區塊鏈和限量版NFT等新興技術來大肆慶祝.
1900/1/1 0:00:00來源:鋅刻度,作者|陳鄧新,編輯|高智 圖片來源:由無界AI工具生成AI,成為游戲的重要一環。當AIGC大潮起,各行各業都面臨競爭力重塑,游戲行業也不例外,大大小小的游戲企業紛紛加碼,渴望搶占技.
1900/1/1 0:00:00原文作者:@milesdeutscher原文編譯:Biteye核心貢獻者Crush在短短21天內完成37.5萬倍漲幅之后,$PEPE改變了許多人的生活.
1900/1/1 0:00:00來源:新智元 導讀:Gen-1能在iPhone上用了,安卓版用戶坐等上線。沒想到,「視頻版的Midjourney」已經上線APPStore了! 劃重點,能夠免費體驗.
1900/1/1 0:00:00


