






 BTC/HKD+1.45%
BTC/HKD+1.45% ETH/HKD+2.42%
ETH/HKD+2.42% LTC/HKD+3.01%
LTC/HKD+3.01% DOT/HKD+2.44%
DOT/HKD+2.44% ADA/HKD+3.14%
ADA/HKD+3.14% SOL/HKD+3.43%
SOL/HKD+3.43% XRP/HKD+2.41%
XRP/HKD+2.41% DOGE/US+3.29%
DOGE/US+3.29%原創:陳彬
來源:遠川研究所

圖片來源:由無界AI工具生成
每一個大模型都是一臺昂貴的“碎鈔機”,這已經成為各路AI觀察家們津津樂道的常識。
大模型訓練成本有一個簡單的比例:訓練費用跟參數量的平方成正比。比如OpenAI訓練1750億參數的GPT-3費用大概是1200萬美元,訓練5000億參數的GPT-4成本就飆升至1億美元。
成本大都來自GPU使用時長。Meta訓練650億個參數的LLaMA模型耗費100萬個GPU小時;HuggingFace訓練Bloom模型耗費了超過兩個半月的時間,使用的算力相當于一臺裝有500個GPU的超級計算機。
Google在訓練5400億參數的PaLM模型時,在6144塊TPUv4芯片上訓練了1200小時,然后又在在3072塊TPUv4芯片上訓練了336小時,總共消耗了2.56e24FLOPs的算力,折合成Google云計算的報價,大概在900~1700萬美元左右。
但是……幾百上千萬美金的訓練費用和幾億美金的硬件投入,相比AIGC開啟的浪潮,真的算貴嗎?
微軟2022年的凈利潤是727億美金,Google是600億美金,Meta則是230億美金,在OpenAI花費460萬美金訓練GPT-3之前,這些巨頭都投入了幾十甚至上百億美金用來尋找所謂的“新方向”。
微軟迄今為止向OpenAI投入了100多億美金,這個數字看起來很多,但要知道微軟當年收購LinkedIn就花了262億美金,而在更早的時候收購諾基亞手機業務花了71.7億美金,基本等于打了水漂。
Meta則花了更多“冤枉錢”來尋找第二曲線。2021年扎克伯格把Facebook的名字改成了“Meta”,投入巨資Allin元宇宙,2022年元宇宙部門虧損137億美元。在ChatGPT問世之前,Meta甚至一度準備把2023年的20%預算投入到元宇宙中去。
Google對AI一向重視,不僅收購了“前GPT時代”的明星DeepMind,還是Transformer這一革命性模型的提出者,但Google并沒有像OpenAI那樣孤注一擲地“死磕”大語言模型,而是在多個方向上“撒胡椒面”——總投入并不少,但效果加起來都不如一個ChatGPT。
截至2023年6月1日,全職區塊鏈開發者有6793名:金色財經報道,Wu Blockchain發推稱,Electric Capital開發者報告顯示,截至2023年6月1日,全職區塊鏈開發者有6,793名,月活躍開源開發者有21,300名,較2022年同比下降22%。工作時間12個月及以上的開發者貢獻了80%以上的代碼。過去一年,Osmosis、Sui、Aptos、TON、Optimism 和 Aztec Protocol 的開發者數量大幅增加。[2023/7/10 10:12:38]
拉開視野來看,全球科技巨頭——包括國內的大型互聯網企業在移動互聯網滲透率見頂之后,展開了慘烈的“存量博弈”,卷算法推薦、卷短視頻、卷Web3、卷本地生活……投入的資金遠遠超過OpenAI在ChatGPT誕生前燒掉的10億美金。
發現新大陸的費用,跟舊大陸的內耗向來不在一個數量級。歐洲人在哥倫布發現新大陸之前內卷了1000年,而發現新大陸只花了西班牙王室投資的200萬馬拉維迪——跟新大陸給世界帶來的變化相比,這點兒錢其實微不足道。
事實上,“資金”從來都不是啟動本輪AI浪潮的核心因素。真正核心的因素是另外兩個字:信仰。
蠻力的神跡
ChatGPT走紅后,好事兒的媒體跑去采訪了Google旗下的DeepMind創始人DemisHassabis。
被OpenAI搶去了所有風頭的Hassabis言辭有點兒不客氣:“面對自然語言這一挑戰,ChatGPT的解決方案如此不優雅——僅僅是更多的計算能力和數據的蠻力,我的研究靈魂對此倍感失望。”

DemisHassabis和柯潔
這句話聽起來很“酸”,然而他接著話鋒一轉:“但這的確是獲得最佳結果的方式,所以我們也以此為基礎。”意思就是雖然不太認同,但OpenAI的“蠻力”真的很香,我們也不得不去學。
Hassabis身段靈活,但早期對“蠻力”這件事的態度,讓Google和OpenAI有了致命的分野。
曼聯官方NFT系列被指控抄襲藝術家DesLucrece的作品:金色財經報道,曼聯足球俱樂部的官方NFT系列被指控抄襲藝術家DesLucrece的作品,DesLucrece是一位以Des Monsters NFT系列而聞名的匿名藝術家,該系列目前在OpenSea的地板價為17.5ETH(約20,825美元)。一位Twitter用戶指責曼聯的“The Devils”系列與DesLucrece的作品幾乎相似,包括相同的角色設計、配色方案等。曼聯于今年早些時候首次與Tezos基金會合作,并于12月21日開始發布“The Devils”。該系列共有7,777個NFT,每個售價約36美元,此后已售罄。DesLucrece在推特上表示,他和相關方正在商討解決方案,并等待曼聯的回復。[2022/12/29 22:13:05]
2017年,谷歌在論文中公開了革命性的Transformer模型,業界逐漸意識到這個模型對于構建AGI的意義。然而,基于同樣的Transformer,谷歌與OpenAI卻走上了兩條不同的兩條路。
OpenAI旗幟鮮明地從Transformer構建大語言模型,瘋狂堆參數,2018年6月發布GPT-1,參數1.17億;2019年2月發布GPT-2,參數15億;2020年5月發布GPT-3,參數1750億,在蠻力的道路上“一條路走到黑”。
而Google雖然也地祭出BERT、T5和SwitchTransformer,表面上跟OpenAI斗的有來有回,但光從模型的名字就能看出來:Google總在更換模型搭建的策略,而OpenAI的策略更單一更專注。
比如GPT-2和GPT-1相比,OpenAI沒有重新設計底層結構,而是將Transformer堆疊的層數從12層增加到48層,并使用了更大的訓練數據集,而GPT-3進一步把層數增加到了96層,使用比GPT-2還要大的數據集,但模型框架基本上沒有改變。
另外,基于Transformer的大模型演化有三個分支:EncoderOnly,Encode-Decoder,DecoderOnly。OpenAI一直堅持只用DecoderOnly方案,而Google則變來變去:BERT模型使用EncoderOnly,T5模型又改成了Encode-Decoder。
比特幣礦工儲備跌至191萬枚BTC,創12年新低:金色財經報道,IntoTheBlock披露截至10月12日下午的數據顯示,比特幣礦工儲備跌至191萬枚BTC,創近12年以來新低。
此外,自2022年初以來,比特幣礦工儲備僅有46天高于200萬枚BTC。比特幣礦工儲備于2010年2月19日首次超過200萬枚。(Decrypt)[2022/10/13 10:33:14]
等到OpenAI突破后,Google匆忙轉向DecoderOnly方案,時間已經錯失了至少一年半。
在跟OpenAI的軍備競賽中,Google卻總沉浸在一些貌似炫酷,但實則對AI缺乏信心的產品上——比如2022年發布的Gato。Gato的思路是先做一個大模型底座,然后再灌不同的數據,以此生成出大量小模型——每個小模型都有特定的能力。
這么做的目的是讓單個AI具備盡可能多的功能,更加通用。做一個簡單的類比:谷歌路線相當于讓一個上完九年義務教育的12歲小孩兒,去參加鋼琴、寫作、編程、舞蹈等一系列專業技能培訓班,靠著“1+1+1...”培養出一個多才多藝的“全才”。
Gato能執行604種不同的任務,包括給圖片配文、玩雅達利游戲、操作機械臂搭積木。不過,Gato雖做到了“通才”,但實用性卻相當堪憂:其中近一半功能,還不如便宜小巧的“專才AI”好使,有媒體評價:一個平庸的人工智能。
“萬能”但又不那么萬能的Gato
相比之下,OpenA更熱衷于讓AI“做好一件事”,即像人類一樣理解自然語言——這是通向AGI的必經之路。
在所有站在Transformer模型肩膀上的團隊中,OpenAI是把“蠻力”發揮到最淋漓盡致的一個,算力不夠就買算力,數據不夠就找數據,別人的牛逼技術我直接拿來用,反正就是要把規模堆上去。終于,在“暴力美學”的指引下,奇跡出現了。
從成立第一天起,OpenAI就把創造接近甚至超越人類的AGI作為幾乎唯一的目標。而且相比Google的遲疑不定,OpenAI發起人們是真的相信AI可以成為一個18歲的成年人,而不是永遠停留在12歲上打轉。
BTC中位交易量達2年低點:金色財經報道,據Glassnode數據顯示,BTC中位交易量達2年低點,7日均值數額為291.74 美元。注:交易量中位數(MedianTransactionValueperBlock)該數據維度統計了每日網絡中每個區塊的交易量(單位:BTC),從而得到當日區塊交易量中位數,可以用于衡量網絡的活躍用戶。[2022/9/18 7:04:26]
黃仁勛在今年3月對談OpenAI聯合創始人IlyaSutskever時,問了一個問題:“在這個過程中,你一直相信,擴大規模會改善這些模型的性能嗎?”Ilya回答道:“這是一個直覺。我有一個很強烈的信念,更大意味著更好。”
這是一場蠻力的勝利,但更是一種信仰的勝利。大模型回報給“信仰”的禮物,也遠超想象——隨著參數量的暴力提升,研究人員突然有一天發現大模型出現了令人驚喜,但又難以解釋的能力飆升。
他們找了一個老詞來形容這種現象:Emergence。
虔誠的回報
Emergence這個詞,常見于哲學、系統學、生物學等領域,其經典的定義是:當一個實體被觀察到具有各個部分單獨存在時不具備的屬性和能力時,這種現象就被稱之為“涌現”,早在古希臘時代,這種現象就被亞里士多德研究過。
后來,英國哲學家GeorgeLewes在1875年第一次發明了Emergence這個詞,用來專門形容上述現象。1972年,諾貝爾物理學獎得主PhilipAnderson撰寫了一篇名叫“MoreisDifferent”的文章,用一句經典的金句來給“涌現”做了解釋:
當一個系統的量變導致質變時,就稱之為“涌現”。
“涌現”被引入到大模型中,可以說是相當貼切:AI工程師們觀察到一個現象,隨著模型的參數量越來越大,當超過某個閾值或者“臨界點”的時候——比如參數量達到100億,模型會出現一些讓開發者完全意想不到的復雜能力——比如類似人類的思維和推理能力。
比如,Google大模型測試基準BIG-Bench里有一項任務:給出4個emoj表情符號,讓模型回答代表什么電影。簡單和中等復雜度的模型都回答錯了,只有參數超過100億的大模型會告訴測試者:這是電影FindingNemo。
BitMEX創始人:我仍相信以太坊在年底前到達10,000美元:6月2日消息,BitMEX 創始人 Arthur Hayes 在最新博文中探討了當前的市場形勢,Arthur 認為美聯儲加息不可持續,加密市場將在縮表預期消失后迎來反彈。中期選舉前,人們會意識到,加息不能解決由全球供應鏈危機帶來的通脹,而只會破壞資產價格。
文中進一步提出,加密市場與納斯達克的相關性在本輪加息中已經降低,比特幣和以太坊每一輪的熊市底部都高于上一輪的牛市頂部,并提出本輪下跌的中比特幣的底部在 25,000 到 27,000 美元,以太坊在 1,700 到 1,800 美元,“我仍相信以太坊將在年底前到達 10,000 美元,但我不確定美聯儲決策轉變的拐點在哪里”。[2022/6/2 3:58:09]

2022年,來自Google、DeepMind、斯坦福和北卡萊羅納大學的學者分析了GPT-3、PaLM、LaMDA等多個大模型,發現隨著訓練時間、參數量和訓練數據規模的增加,模型的某些能力會“突然”出現拐點,性能肉眼可見地驟然提升。
這些“涌現”能力超過了137多種,包括多步算術、詞義消歧、邏輯推導、概念組合、上下文理解等。這項研究給大模型的“涌現”下了一個定義:如果一項能力只有在大模型中存在,在小模型中觀測不到,這項能力就是“涌現”出來的。
微博博主tombkeeper做過這樣一個測試:在ChatGPT剛誕生時,他將發表于2018年的一篇充滿隱喻的微博——“對微博上的佩奇來說,今天是黑暗的一天——她們的摩西殺死了她們的加百列”,交給ChatGPT理解,但ChatGPT回答失敗了。
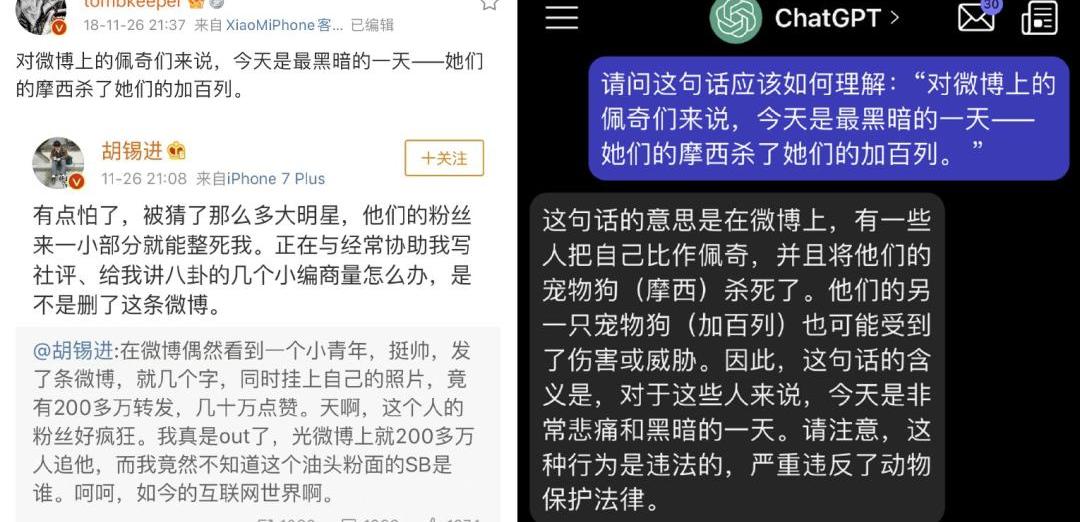
來源:微博tombkeeper
而等到2023年3月OpenAI推出了GPT-4,tombkeeper再次將這個問題扔給AI,回答基本接近滿分。

來源:微博tombkeeper
Google在訓練大模型PaLM時,也發現隨著參數規模的增加,模型會不斷“涌現”出新的能力。

當最終把PaLM的參數堆到5400億時,模型就具備了區分因果關系、理解上下文概念、解釋冷笑話等能力。比如像前文一樣根據4個emoj表情符號來猜電影名字。

對于大模型“涌現”的背后邏輯,現在幾乎沒有科學家能徹底講清楚。這讓人想起了1950年阿蘭?圖靈在《計算機器與智能》這篇論文中論述過一個觀點:“學習機器有一個重要的特征,即它的老師往往對機器內部運行情況一無所知。”
當然,有人對此欣喜若狂,有人則會覺得毛骨悚然。不過無論是哪一派,都不得不承認那句老話:大力真的能出奇跡。“大力”背后就是信仰——人類一定可以用硅基來模仿大腦結構,最終實現超越人類的智能。而“涌現”告訴我們:這一刻越來越近了。
信仰的充值
有信仰,就要對信仰充值。中世紀基督徒用的是贖罪券,新世紀AI信徒用的則是晶體管。
文心一言面世之后,李彥宏的一段采訪曾沖上熱搜——李廠長直言“中國基本不會再誕生一家OpenAI”,這似乎有點兒不太給王慧文面子。但這一觀點確實有理有據:大模型軍備競賽,大概率會比曾經燒掉數十億美金的網約車戰爭還要慘烈。
如果按照業界預估的成本,GPT-4訓練成本大約在1億美金左右,GPT-3的訓練費用也要1200萬美元。先不說昂貴的人才團隊費用,王慧文的5000萬美元光是投入到GPU購買或租賃上,都顯得捉襟見肘。
大模型發展的三要素:算法、算力、數據。其中算力是數字時代的“石油”,未來的缺口一定會越來越大。自2012年開啟黃金時代后,AI對算力的需求開始呈現指數級增長。從2012年的AlexNet,到2017年的AlphaGoZero,算力消耗足足翻了30萬倍。
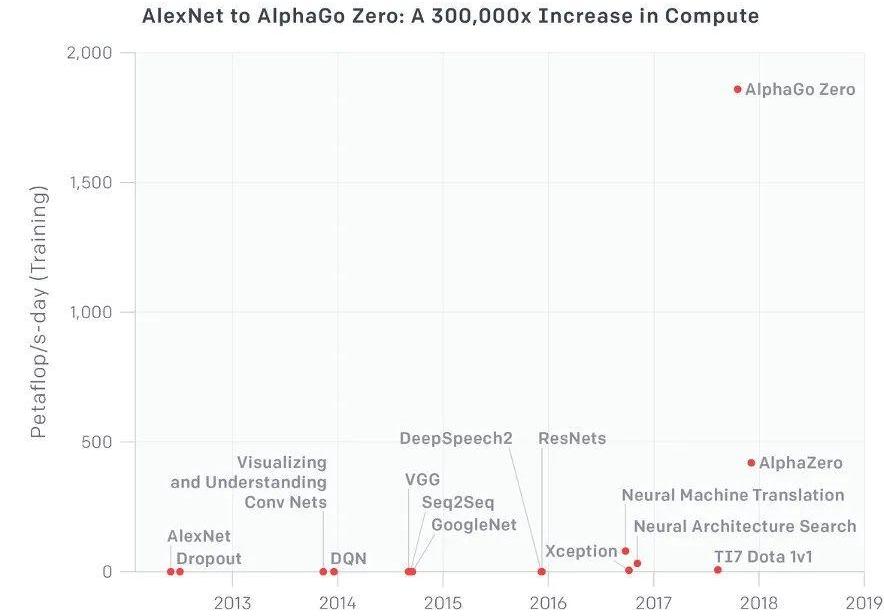
訓練大模型需要專門的GPU集群,傳統數據中心的用場不大。微軟為了“迎娶”OpenAI,曾特地配備了一臺擁有數萬塊A100與H100GPU的超級計算機,光硬件入場費就花了近10億美金。
即便如此,據相關機構測算,由于ChatGPT與GPT-4的訪問量仍在增長,10億美金的超級計算機馬上又要不夠用了。要么進一步擴大算力,要么只能盡力控制成本,繼續采用限流等手段。

英偉達AI超算產品的第一個客戶,就是OpenAI
對此,貼心的賣鏟人英偉達推出了AI超算云服務:租賃8塊旗艦版A100,每月只需37000美元,童叟無欺。若要達到訓練GPT-4的算力月租金需4600萬美元左右——每月凈利潤不足一個小目標的企業,的確可以洗洗睡了。
跟用神經網絡來模仿大腦一樣,AI算力的昂貴也跟人腦的屬性保持一致。
一個人的大腦大約有860億個神經元,每個神經元平均跟其它7000個神經元相連接,所以大約有6000萬億個連接。盡管大腦的重量只占人體的2%左右,但當無數神經元連接工作的時候,它們每天需要消耗人體總能量的20%~30%。
因此,即使是碳基生物的“智能”,也是一種暴力堆砌神經元后的“涌現”,對能量的消耗巨大。而相比經過上億年進化的碳基神經元,晶體管構建的神經網絡離“低功耗”相距甚遠——比如柯潔功率是20w,而跟他下棋的AlphaGo功耗是他的5萬倍。
因此,人類要想做出真正的AGI,還需要繼續給信仰來充值。
對全人類來說,這種充值顯然是無比劃算的。仔細算一算,OpenAI燒掉的10億美金,不僅給全球的科技公司找到了一片“新大陸”,還給愈發內卷的全球經濟點亮了增量邏輯。在美元泛濫的當下,還有比這10億美元性價比更高的項目嗎?
當“新大陸”被發現后,全世界都會蜂擁而至。比爾?蓋茨雖然現在是AI的狂熱鼓吹者,但早在微軟第一次投資OpenAI時,他是強烈的懷疑者,直到去年年底看到GPT-4的內部演示才對外表示:It’sashock,thisthingisamazing。
比爾?蓋茨在未來可能擁有人工智能領域最雄偉大廈的冠名權,但OpenAI的創始人們、以及更多連接主義學派的人工智能先驅,值得人們在廣場上樹立雕像。大模型的煉丹之路,信則靈,不信則妄,跟風的投機主義者不配留下姓名。
最后,人類通往地獄或者天堂的道路,一定是由AI虔誠的信徒用一顆顆晶體管鋪就的。
參考資料
ChatGPTandgenerativeAIarebooming,butthecostscanbeextraordinary,CNBC
MicrosoftspenthundredsofmillionsofdollarsonaChatGPTsupercomputer,TheVerge
EmergentAbilitiesofLargeLanguageModels,JasonWei等,TMLR
TheUnpredictableAbilitiesEmergingFromLargeAIModels
137emergentabilitiesoflargelanguagemodels,JasonWei
HarnessingthePowerofLLMsinPractice
Alphabet’sGoogleandDeepMindPauseGrudges,JoinForcestoChaseOpenAI,TheInformation
編輯:戴老板
視覺設計:疏睿
責任編輯:戴老板
在所有協議中,UniswapV2提取的MEV最多,約占總量的62%。撰文:PaulVeradittakit,PanteraCapital合伙人編譯:Leah,ForesightNews MEV簡.
1900/1/1 0:00:00作者:Alluvial首席執行官MaraSchmiedt編譯:比推BitpushNewsMaryLiu以太坊Shapella升級終于要來了.
1900/1/1 0:00:00Crypto公司開始將自己與體育贊助聯系起來,希望他們的名字出現在球隊的球衣上或場邊,從而帶來更多的品牌知名度,并最終吸引新用戶。以下是這些合作伙伴關系迄今為止的進展情況.
1900/1/1 0:00:00作者:空島,ParallelVentures投資經理Twitter:@DittoJoBrr區塊鏈本身中立.
1900/1/1 0:00:00作者:畢良寰 距離以太坊Shapella升級僅剩一天的時間!自2015年以太坊上線以來,它已成為世界排名第二的加密虛擬資產,以太坊誕生于行業的意義在于它能夠讓開發者構建智能合約和去中心化應用.
1900/1/1 0:00:00吳說作者:nobody 本期編輯:ColinWu本文為NFT交易平臺生存現狀研究的第三篇,在后版稅戰爭,頭部平臺發展相繼陷入困境,小而美的平臺反而展現出了活力的一面.
1900/1/1 0:00:00


