






 BTC/HKD-0.05%
BTC/HKD-0.05% ETH/HKD+0.24%
ETH/HKD+0.24% LTC/HKD+0.62%
LTC/HKD+0.62% DOT/HKD+2.01%
DOT/HKD+2.01% ADA/HKD+1.76%
ADA/HKD+1.76% SOL/HKD+1.05%
SOL/HKD+1.05% XRP/HKD+2.34%
XRP/HKD+2.34% DOGE/US+0.3%
DOGE/US+0.3%你知道《太空歌劇院》嗎?
它是一幅AI作的畫,并拿到了藝術比賽的一等獎。在2022年,AI作畫已經變得如此簡單,你只要會打字就行。在一片高斯噪聲中逐漸顯露出精彩絕倫的顏色和圖案,AI是怎么畫畫的?為什么能畫得這么好?會不會取代人類設計師?
更令人費解的在于,AI有沒有自己的邏輯思辨能力?
其實,我們還處在人工智能的早期,AI對真正的邏輯和某個垂直領域的理解還不深,但不斷強化它的邏輯思維能力一定會是接下來研發的重點。
書接上回,這次真格投資副總裁林惠文將帶領我們,從上次ChatGPT的AI文字跳到AI圖片,繼續探索AI世界。從AIGC圖片背后的模型,到模型之間的關系以及發展歷程。除此之外,我們還準備了對AI領域相關問題的解惑和一些好用的工具推薦,請一定不要錯過~
非常榮幸今天能跟大家分享一些AIGC圖片相關的梳理,在漫漫的熊市之中,近期我們看到了很多驚人的生成效果。
首先我們來看一下AI生成的圖片。

這是最近非常火的AI生成圖片平臺Midjourney產生的一些圖片效果,可以看到非常真實,也有很強的創意效果。它是如何做到的?
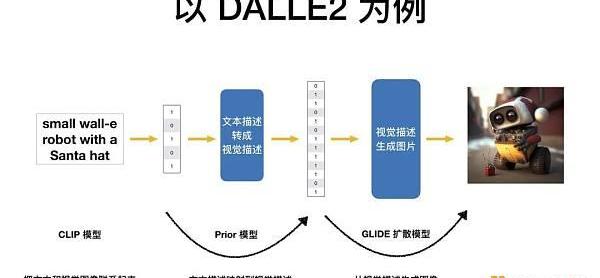
通俗易懂地來講有三個步驟。首先,把人類的文字轉換成計算機能夠理解的表達,然后把計算機能理解的文本表達轉換成計算機能理解的視覺描述,再接下來,把計算機能理解的視覺描述生成人類能夠看懂的圖片。
被黑客攻擊的Vanity Address從Arbitrum空投中竊取50萬美元:3月24日消息,被黑的Vanity Address已被用于從Arbitrum的空投中竊取價值 500,000 美元的代幣。Vanity Address是一種定制的加密貨幣地址,其中包含用戶選擇的特定單詞或短語,目的是使它們更加個性化和易于識別。但是,缺點包括可能被黑客攻擊的安全風險。
該推文解釋說,代幣被某人竊取,該人編譯了有資格接收 ARB 代幣的Vanity Address,使用Vanity Address生成器生成了類似的地址,并將空投的代幣定向到它們。對這些Vanity Address的黑客攻擊使得原始所有者無法索取他們的 ARB 代幣。(Cointelegraph)[2023/3/24 13:24:39]
以DALLE2為例,它訓練了3個模型來做這件事情。接下來,我會分別講述。
CLIP模型
第一個模型是CLIP模型,負責將文本和視覺圖像聯系起來。
過去的很多算法就像是拿1萬張人類已經標注了類別的照片,讓計算機去尋找不同類別照片的差異化特征。最大的缺點是,它無法標注世間萬物,只能分類有限的集合,同時人力標注會成為學習的上限。
CLIP模型帶來的新思路是什么?它很像是真實生活中教小朋友認識物體。看到一個東西就直接告訴小朋友,這是一只游泳的鴨子,而不是一次性拿20張鴨子的圖片告訴他,這是鴨子,你記住它的所有特征。CLIP模型的算法實現了這樣一個特點,只要我們有充足的算力,就能學會世間的萬物。

CLIP模型的數據集從哪來?它來自于互聯網上圖文的匹配對,總共收集了4億張的圖文匹配對,再經過一個圖文編碼器,把人類能看懂的文字和圖片轉換成計算機能懂的數據結構。
孫宇晨地址從Aave借貸池V2提取190萬枚TUSD,并轉至Poloniex:金色財經報道,派盾監測數據顯示,標記為Justin Sun的地址從Aave的Lending Pool V2中提取190萬枚TUSD,并轉移到Poloniex 4,然后向Aave Protocol V2提供約79.2萬枚USDT。[2023/2/13 12:03:08]
CLIP模型用到了兩個編碼器,視覺編碼器叫VisionTransformer,文字編碼器叫Transformer。下圖是VisionTransformer編碼器產生的效果圖,可以看到兩張圖片里背景部分的顏色被大幅弱化,強調了網球和黑狗的輪廓。這就是優秀的編碼器能實現的效果:用人類的視角找重點,進行數據降維。
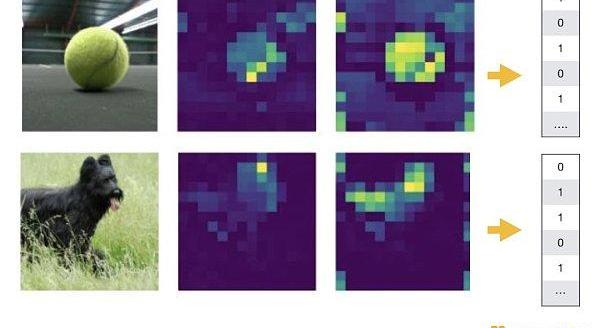
CLIP模型做的事是什么?把來自互聯網的4億張圖片和4億條文本進行編碼,并兩兩配對,形成一個4億*4億的矩陣。
CLIP模型的訓練目標是什么?通過各種各樣的復雜計算,讓原本匹配的圖片和文本產生正相關。將蘋果的照片和蘋果的文字進行匹配,而不是摩托車或其他。

CLIP模型實現的功能是什么?給定任何一個文本,能返回相關性最高的圖片;給定任何一張圖片,能返回相關性最高的文本描述。實現海量的圖像和文字特征的mapping。
GLIDE模型
有了mapping以后,接下來重要的是如何從視覺的描述中產生圖像,這是GLIDE擴散模型。
安全團隊:Oapital地址從Aave V2撤回500萬枚USDC,并轉入FTX 400萬枚:金色財經報道,據派盾(PeckShield)監測,標記為Oapital的0x66B8開頭地址從Aave V2撤回500萬枚USDC流動性,并將400萬枚USDC轉移到FTX。[2022/10/11 10:30:42]
它就像是教小朋友學畫畫,先給小朋友看一張簡筆畫,逐漸把它擦掉,讓小朋友在大人的引導之下,試著從白紙開始恢復這張簡筆畫。
從計算機的視角來看,擦除的過程就是給圖片不斷增加噪聲的過程,這種噪聲是一種正態分布的噪聲,叫高斯噪聲,直到最后變成一張純噪聲的圖片。恢復的過程就是通過概率除去噪聲的過程,這中間往往會加一些指引,叫Guidance,以確保恢復的過程朝著對的方向。

左圖為增加噪聲的過程,右圖為除去噪聲的過程
GLIDE擴散模型帶來最大的創新就是在訓練的過程中融入了文本的信息。在CLIP模型的基礎上,在恢復的過程中嵌入文本的信息,這就導致了難度的快速疊加,因為它既要學會恢復的算法,又需要學會識別的算法。然而,在恢復的過程中,它并沒有把知識完全融入其中,如何才能把知識徹底地融入到圖像生成里?
GLIDE模型的抽象理解,就像是爸爸教小朋友騎車,目標是希望在有爸爸扶和沒有爸爸扶的時候,小朋友都能騎出同樣的曲線。這往往通過一種中間形態來實現,從一直扶到偶爾扶,偶爾撒手,最終的訓練目標就是不斷在這種狀態里達成。

Multichain團隊從Andre Cronje處得到原網站域名,并將其重定向至multichain.org:3月10日消息,跨鏈基礎設施Multichain發推稱,原網站multichain.xyz已經被重定向至multichain.org,multichain.xyz不會關閉,仍提供跨鏈服務。非常感謝AndreCronje轉移域名給Multichain團隊。[2022/3/10 13:49:33]
GLIDE擴散模型的目標也是如此,在它的原理中,爸爸扶著小朋友就是分類器,能幫助分類或目標識別,撒手就意味著無分類器指引,有時會將一些文本的信息替換成空的字符串,隨機替換掉一些信息。當有分類器產生的曲線和沒有分類器指引產生的曲線一致時,整個文本的信息就融入到了生成過程中。
有了GLIDE擴散模型以后,還可以制定不同的引導目標,因此會產生不同的效果,如果你想生成與某張圖片一樣效果的圖片,你可以輸入這張圖片,接著就會得到一張類似風格的圖片。這就像是一個小朋友的爸爸告訴他,自行車的前輪其實是個裝飾品,他最終在不斷的強調之下,就會學會這樣騎車的方式。
PRIOR模型
當CLIP模型將文本和視覺相連,GLIDE模型通過概率恢復一張隨機的模糊照片,并把文本信息融入其中,我們還缺少了這兩者之間的聯結,如何把文本描述映射到視覺描述中,這就是PRIOR模型的核心。
有了CLIP模型,雖然能夠實現文本和視覺之間相關性的描述,但還缺少一個轉換器,那就是面對一個新的描述,如何產生一張新的圖片。就像你教會了小朋友畫帽子,也教會了畫兔子,現在如何讓他畫一張戴帽子的兔子。PRIOR模型其實是在CLIP模型之后產生一個新的效果,在CLIP模型中用到的文本和圖片編碼器,給編碼后的東西再增加一個特征,這就使得文本和圖片的信息都融合在同個維度,便于我們去操作。
約2283.75萬枚USDT從Aave貸款池轉出:金色財經報道,Whale Alert數據顯示,北京時間10月6日0:01,22,837,548枚USDT從Aave貸款池轉入0xbb7d開頭未知錢包地址,交易哈希為:0xcff56fb5dc8f0c8a288fc54dba78dfe9884b59fb1cd6315432199afd210ea423。[2020/10/6]
三個模型的關系
CLIP模型理解了圖片與文字的關系,PRIOR模型就是在理解圖片與文字的關系之上,從文字中產生一個腦海中的構圖,GLIDE擴散模型就是要把腦海中的構圖畫出來,畫出人類能懂的視覺圖片。

我們再從下圖論文的原理來理解一下。圖中有一條虛線,虛線的上方是預訓練的過程。左邊的TextEncoder,就是之前提到的文字轉換器Transformer,它把一段文字轉換成計算機能理解的表達。右邊的ImageEncoder,也就是視覺轉換器VisionTransformer,把人類理解的視覺圖片轉換成計算機的數據結構。
在經過大量的訓練之后,這兩者之間產生了具有相關性的連接,也就是文字和圖片之間的關系產生了非常強的理解。
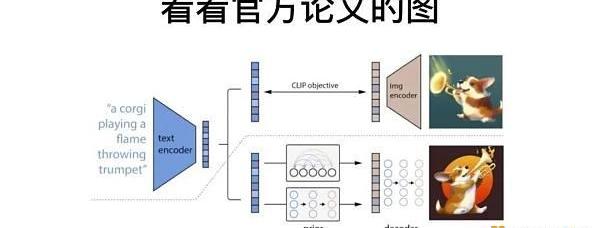
虛線之下是生成的過程,把文本放進PRIOR模型里面,從這段文本中生成計算機能理解的視覺表達結構,再用GLIDE模型生成人類能看懂的圖片。雖然上下兩只小狗的圖片看起來不一樣,但它們本質上包含了同樣的文本語義,這樣就實現了任何一段文本都能生成出一張人類能看懂的圖片。
發展歷程
整個夢開始的地方,始于2017年Google發布的一篇論文《Attentionisallyouneed》。它讓算法學會了人類的注意力機制,就是當我們去看一張圖片時,會看到重點,同時忽略背景的信息。
這篇論文發表之后,帶來一個NLP的模型,叫Transformer,一經發布便快速屠榜,接著很快有了BERT模型,有了OpenAI的GPT-3模型。在視覺領域,有DERT模型,iGPT模型,以及上面提到的VisionTransformer。
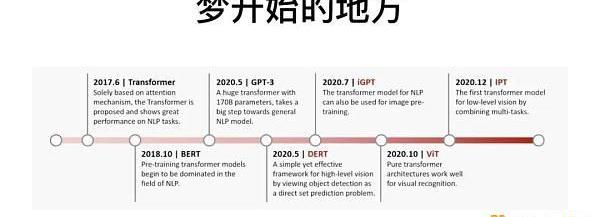
Transformer模型的重要性在于,它是我們剛才提到的三個模型的底座,學會找出圖片和文字的重點,才能夠搭建CLIP模型,才可能有之上的PRIOR和GLIDE擴散模型。
夢想的實現還有另一半,圖像生成。
從2005年開始的求解特定概率密度函數,通俗理解就是通過最快的方法去估算正態分布,再到2008年的去噪自編碼器的研發,加入高斯噪聲,一種正態分布的噪聲,再將它去除,我們用到的很多拍照中的去噪、降噪功能就是從這里來的。到了2011年,有人嘗試將這兩種算法結合在一起,2015年,開始嘗試用這種思想還原照片。但這時候還原照片的質量還不是很高。

時間撥轉到2019年,中國的宋飏博士把朗之萬動力學引入到數據分布的估算中,產生了非常好的效果。2020年,Google發布名叫DDPM的論文,這篇論文核心就是結合朗之萬動力學和擴散模型,產生了非常高的圖片生成質量。
2014年引起軒然大波的GANnetwork對抗生成網絡,已經能生成出效果不錯的圖片,但它的訓練難度很高,擴散模型降低了圖像生成模型的訓練難度,還能生成比GAN更多元的圖像。
在夢想實現的2021和2022年,OpenAI和Google都開始嘗試把文本信息加入到擴散生成的過程中,產生了今天的GLIDE模型。OpenAI在思想上的突破,用Transformer去海量地理解圖片和文本,產生了CLIP模型,再用擴散模型在圖像生成中融入海量的圖文信息,優質的AIGC圖片終于誕生。
接下來,我們將圍繞一些問題進行討論。
1、從產品化、商業化的角度出發思考,目前AIGC的技術層面的發展會產生影響?
有兩個維度。第一個維度是在海量數據中尋找我們最想要的內容,第二個維度是在海量數據中得出新的內容,反向給予我們創造的靈感。
從AI本身的能力再進行泛化的話,一方面很多現有產品的使用體驗能得到巨大的提升,例如在筆記類的軟件中加入AI后,在寫作過程中能得到更好的體驗;另一方面,未來創意不強,生成能力較弱的人可能會被AI替代。
2、回到基本邏輯,我想確認下自己的理解是否正確:相較于Transformer,ChatGPT并不是在AI領域出現了一個顛覆性的技術創新,而只是在一個模式上加了人類的feedback,設置了不斷迭代的參數,它自己越搞越聰明了。
過去的所有模型的進化,其實圍繞兩個方向在進化。第一個是DNA,第二個是方法論。DNA很像真實世界中材料的研發,方法論更像是真實世界中材料的使用。
Transformer是DNA的進化,是更核心的突破。ChatGPT是方法論,但它就更簡單了嗎?并不是的,它在探索的過程中經歷了很長的時間,同時要滿足很多先決條件,這個方法論才能得以運用。不論方法論突破還是DNA突破,都很有意義。
3、未來的生意模式會怎么樣?會不會更集中?圍繞這樣ChatGPT的模型,它會產生哪些創業方向?
可能有兩種商業模式,一種是ToB的,就跟阿里云一樣,另外一種就是讓開發者在這種大模型上去ToC。不論是DNA還是在方法論上的突破,它都可能讓一個企業產生壟斷,產生巨頭效應。
ChatGPT和用戶不斷互動,會得到源源不斷的反饋數據,數據也是一種資產,一種生產要素。這種生產要素產生的產品會是人類更高頻使用的東西,它的頻率越高,這種生產要素就越來越重要,反饋能夠創造的要素提升就越來越重要,同時帶來的經濟價值就越來越大。
4、會不會有規模效應或雙邊網絡效應?
我覺得背后既有這種網絡效應,又有一些規模效應。如果設想一下,第一個研發出來的這種中文大模型,它會快速地獲取市場上有限量的開發者,開發者在用它的產品去面向ToC去獲取C端用戶,它的數據會源源不斷反饋回來,去優化它的效果,其實就會產生更強的壟斷效應。
5、從投資的角度,在AIGC,我們應該投什么樣的團隊?
我覺得傳奇的團隊是有創造DNA能力的團隊,黃金的團隊是有能力把應用層和AI完美結合的能力,白銀的團隊就是打造AI領域的基礎設施的團隊。
最后分享一些我常用的工具,它們對于做投資判斷來說很有重要性,希望可以對你有所幫助。
論文追蹤:
https://paperswithcode.com
工程模型追蹤:
https://huggingface.co/
AI項目追蹤:
https://theresanaiforthat.com
來源:元宇宙之心
Tags:CHAFORGLITRANSUnchartedFORTH幣Glitch Protocoltransfercoin
2022年已經過去,這一年中發生了許多驚天動地的收購案,如微軟天價對動視暴雪的收購案以及爭議不斷的馬斯克收購推特案.
1900/1/1 0:00:002023年1月1日,一款名為《巽風數字世界》的APP登錄AppStore,這是由茅臺和網易聯合推出的虛擬世界APP.
1900/1/1 0:00:00對話者 SujiYan?MaskNetworkfounderLuke????Web3MQco-founderjoshua???RSS3founderTim?????.
1900/1/1 0:00:00注:本文寫于?2023?年?1?月?12?日,數據或與當前市場行情存在偏差 1.宏觀 宏觀數據和事件有市場較大影響,數據公布時會有劇烈波動.
1900/1/1 0:00:00為你詳細挖掘和解讀GTX交易所背后的團隊、業務模式,以及當前加密債權市場競爭格局。已倒閉的加密貨幣對沖基金三箭資本(3AC)的創始人SuZhu和KyleDavies重出江湖,1月16日,他們的新.
1900/1/1 0:00:00原文來源:Bitwise首席投資官MattHougan原文編譯:比推BitpushNewsMaryLiu尊敬的投資者,?2023年,我們將見證什么?這是每個加密貨幣投資者都想知道的問題.
1900/1/1 0:00:00


