






 BTC/HKD+0.79%
BTC/HKD+0.79% ETH/HKD+0.37%
ETH/HKD+0.37% LTC/HKD+1.87%
LTC/HKD+1.87% DOT/HKD+2.41%
DOT/HKD+2.41% ADA/HKD+2.89%
ADA/HKD+2.89% SOL/HKD+2.98%
SOL/HKD+2.98% XRP/HKD+5.04%
XRP/HKD+5.04% DOGE/US+5.37%
DOGE/US+5.37%原文標題:web3數據市場展望
今天就從數據市場開始,梳理一下自己對這個領域的一些理解。
2022年伊始,我在推特寫下:
2022個人更關注的領域:web3數據市場/infrastructure、web3社交/流媒體、非資金盤鏈游、錢包、亞文化/青年文化NFT消費、DeFi監管解決方案、技術突破性公鏈/跨鏈?
今天就從數據市場開始,梳理一下自己對這個領域的一些理解。
目錄
一、數據到底有多重要?
1、生產方式變革與組織形態遷徙
2、互聯網對傳統商業模式的重構
3、web2的信息孤島
二、數據使用存在哪些難題?
1、隱私邊界與隱私保護
2、數據外部性與產權確立
3、物聯網與數據采集
4、數據價值匹配
5、數據估值
三、web3可能會從哪些途徑解決這些問題?
1、什么是web3?
2、區塊鏈解決部分問題的可能途徑
3、web3數據市場展望
一、數據到底有多重要?
生產方式變革與組織形態遷徙
人類社會發展至今,生產力幾經變革。生產力變革帶來生產方式的變化,進而又會影響到生產的組織形態,因為生產組織畢竟是為了適應生產活動而產生的。純粹的生產為了滿足需求,需要以物易物,這通常是低效且繁瑣的。為了適應效率提高的需求,貨幣得以出現,成為了商品間交換的一般等價物。流通市場開始逐步建立,以流通市場為基礎的商業活動開始日益繁榮。
我認為人類至今共發生過三類生產方式變革:
第一,以器具的出現為標志,從原始社會進入農耕社會。通過對石器、青銅器、鐵器等各類工具的使用,人類開始順應自己的需求改造自然,開始種植水稻小麥,開始蓄養家禽,開始定居。這一時期以自給自足的生產活動為主,并且隨著文明發展逐漸出現了一些商業活動。隨著社會發展,產品日益復雜,自給自足的生產方式越來越難以滿足個體需求,商業活動的占比也越來越高。就這么幾千年延續下來,很多現代社會常見的商業機構已經在這一階段初具雛形,比如銀行、海關等。
第二,以蒸汽機的發明為標志,從手工工業進入機械工業。煤炭與鋼鐵分別解決了生產力變革的能源與材料問題,蒸汽機對付的則是勞動效率問題。人類的長處終究不在體力,重復性的低效生產終究會遇到上限與瓶頸。而機械的出現,解放了人類的雙手,提高了生產的效率。就此,生產方式開始向專業分工的方向演化,人類通過奴役機械,擁有了更多的時間去發展科技人文,文明得以向更復雜多樣的道路前進。生產端的解放造就了流通端的興盛,商業活動開始爆發,現代企業制度初具雛形。
第三,以互聯網的出現為標志,從機器生產進入信息生產。互聯網,顧名思義就是計算機間互相聯接而成的網絡。文明在發展中產生大量信息,以記賬為例,人類最早是用結繩、刻契等方式來記錄經濟活動中的數量關系;數字出現后,它們被記錄在龜甲、銅器、竹簡直到造紙術發明后記錄在紙上。隨著文明演進,生產活動越來越復雜,對一套清晰易懂的記賬規則的需求開始日益強烈。慢慢發展至今天我們熟悉的、會計里的復式記賬法。
然而這些生產出來的信息并沒有機會發揮更大的價值,在漫長的歷史長河中,它們要么被記錄、沉淀到無人冊封的一角;要么被遺忘,消散在過往云煙中。直到計算機代替紙筆成為承載信息的工具,人類才能以一種更為高效、容量更廣闊的方式來記錄與分享信息。在互聯網的語境下,生產活動與商業活動重新發掘了信息的價值,使得信息不僅僅只是產品,也能夠承擔生產資料的角色。
在互聯網產品出現之前,信息當然也能夠作為生產資料,但這意味著高額的成本;而互聯網的出現使得信息得以數字化,這賦予了其一條非常重要的特性:零邊際成本。
事實上,信息生產相對于機器生產的另一大優勢在于網絡外部性。網絡效應的意思是,網絡中每一個節點的增加,都會對現存節點帶來正效用。這本質上仍來自于信息零邊際成本的特性——每一個新加入的節點都會向網絡中的所有節點零成本共享一部分新的信息。
零邊際成本與網絡外部性賦予信息生產方式一些非常恐怖的特性,比如迅速擴張與天然壟斷。理解了這兩點,你會非常容易理解為什么互聯網公司能夠在短短幾年內創造出超越傳統制造業的價值,理解為什么互聯網行業的創業公司總是喜歡燒錢大戰,理解為什么最近中國互聯網公司開始走下坡路。
Memeland:Season 1 of Raids已正式上線:金色財經報道,NFT 項目 Memeland 在社交媒體宣布 Season 1 of Raids 已正式上線,與試點季期間相比,正式版發生了一些關鍵變化,主要包括:每個加入 Season 0(試點季)的用戶可以獲得 69 EXP(經驗值),每個加入突襲(Raid)的用戶也均能贏得“戰利品(Booty)”,Booty 值 = Raid 積點/ Raid 總積點,據悉,第一季的 Booty 戰利品總價值將為 4 萬 USDC。[2023/5/14 15:01:59]
而基于互聯網的生產方式變革也影響到了對應的組織形態。按照制度經濟學大師科斯的理論,企業之所以存在,是因為其交易成本小于市場。而基于互聯網的市場,信息是具有零邊際成本的,也就是說,企業的交易成本必須變得更低才能夠適應,原先的縱向管理形態必須開始向橫向協同進行轉化。類似于OKR之類更注重內部協同的管理系統也開始代替原有的KPI系統。
互聯網對傳統商業模式的重構
伴隨著生產方式的不斷變革,人類的經濟活動重心也開始轉移,相比于物質生產,信息生產以其更廣闊的發展前景得到了更多的關注。除去互聯網上原生的商業活動,應用互聯網對傳統行業進行改造將會是更勢在必行的方式。
現存的改造方式有兩個方向,其一從生產流程入手,目標是提升生產效率,比如很久之前就被喊爛了的工業4.0,通過“互聯+智能”來改進現有生產系統、產業分工、物流管理等;另一個就是重構商業模式,比如共享經濟、信息平臺、網購、社交等。
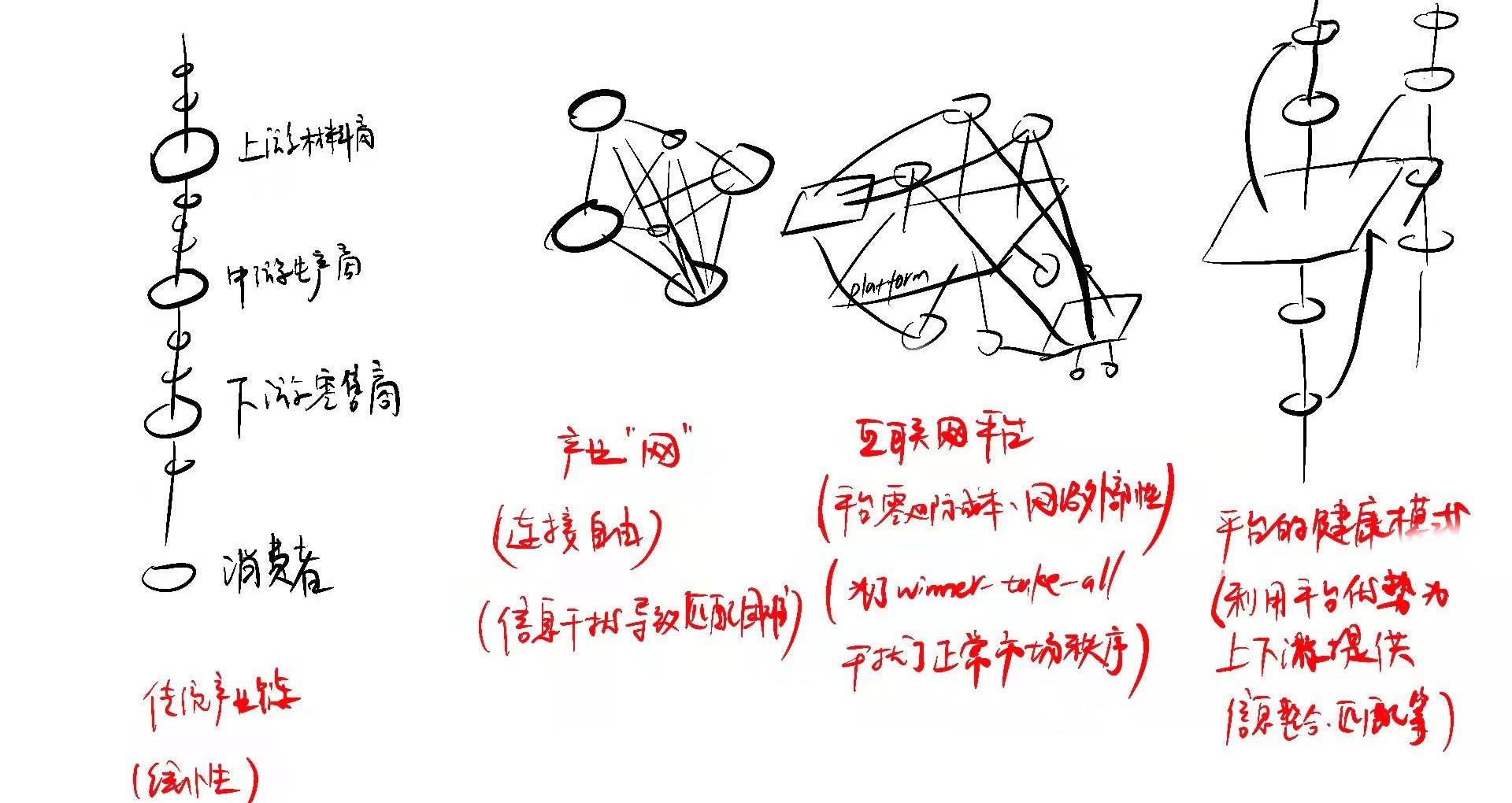
傳統的商業模式是線性的。假設你想買一個保溫杯,你最先想到的是去超市/商場等零售商;你不會說我先去找廠家拿貨,廠家通常也不會給你;你更不會說我希望我的保溫杯是用鈦鋼做的去找更上游的鋼鐵廠。從上游材料商到中游生產商這樣一個完整的鏈條,就是產業鏈。
廠家的生產也是相對盲目的。為什么這么說?因為廠家有自己的一本賬,這本賬一頭是成本一頭是利潤。利潤來自于下游的訂單,通常誰的條件更適合就接誰的訂單。消費者的需求無法直接傳達給廠家。廣泛來說,產業鏈上的每一個節點都無法低成本地去和非相鄰節點直接進行信息與價值傳輸。
互聯網對此的重構,就是將“鏈”變成“網”。
在網絡里,任意節點之間都是可以建立起相互連接的。消費者可以繞過零售商直接找到廠家,去進行批發或者定制產品;看起來似乎是有意消弭了零售商這個角色,實則不然。互聯網實際上強調了零售商信息中介的作用,因為消費者直接去找廠家是需要成本的,而如果零售商可以很好地整合及匹配信息,就能夠賺取利潤。
然而我們知道,分布式系統會帶來大量冗余信息。如果互聯網僅僅是將“鏈”變成“網”,那么隨之而來的,就是信息阻隔與信息干擾,信息之間無法完成高效而準確的匹配。互聯網對商業模式重構的第二個要點,就是平臺的出現。
平臺所做的事情,本質上來說就是信息匹配。線性的傳統產業鏈被互聯網重構為一個個節點后,需要有一個東西來實現原本由產業鏈實現的東西,那就是匹配供需信息。廠商去了B端,消費者去了C端。消費者對某一類產品的需求可以為生產商所捕捉,當整個平臺上出現足夠多相同的需求,生產商的生產就會變得有利可圖。
我們前面說過,互聯網進行生產的兩大特性:零邊際成本與網絡外部性。當越來越多的節點通過平臺獲得連接,他們也會逐漸對平臺產生路徑依賴,這意味著平臺在生產/商業活動中的話語權在越來越強。話語權意味著定價權,零邊際成本帶給平臺的是幾乎為零的成本,因此定價權幾乎就意味著單個節點更高的利潤空間;而網絡外部性帶給平臺的是加速的節點進入。當利潤的兩個因子都在以恐怖的速度增加時,可想而知,一個成功的平臺將會獲得多大的利益。
讓我們來就此解釋以下之前提到的三個問題:
為什么互聯網公司能夠在短短幾年內創造出超越傳統制造業的價值?為什么互聯網行業的創業公司總是喜歡燒錢大戰?為什么最近中國互聯網公司開始走下坡路?
問題一已解。問題二。因為處在競爭狀態的平臺所面臨的,一是話語權的不穩定性,一是新節點的多選擇,即使做到超大的規模、即使有很高的利潤,但只要戰場上還存在哪怕一個差不多的對手,結果就都是不確定的。而不停地融資燒錢搶爭用戶,就是要在未來讓用戶別無選擇,進而利用自己的話語權謀求利潤。
這是互聯網平臺商業模式的本質。“winner-take-all”
過去24小時全網爆倉1.81億美元:金色財經報道,據coinglass數據顯示,過去24小時全網爆倉1.81億美元。其中比特幣爆倉5753萬美元,以太坊爆倉3675萬美元。[2023/3/19 13:12:59]
但其實平臺能做的不只有這些。如果僅僅因為平臺本身的特性而干擾到市場正常的發展,這種行為是短視且不可持續的。如果燒錢獲得勝利,未來勢必要向節點“征稅”來彌補已經燒掉的錢。這個時候再出現實力不錯的新平臺,很容易通過更好的服務與更低廉的價格吸引流量,別人此時無債一身輕,而你呢?
網絡外部性并不意味著純粹的護城河,而是“好的服務=無比堅固的護城河”與“壞的服務=大廈將傾”。這種不健康的商業模式長期是不成立的。
說回平臺能做的。
前面說到互聯網對產業鏈重構,是將“鏈”變為“網”,平臺為了搶奪這些節點而大打出手。但他們忽視了網絡外部性的前提是節點對平臺的路徑依賴,也忽視了節點之間的區別。以網約車為例,司機與乘客是兩種不同性質的節點,乘客打車這一消費行為更多具有隨機性,更注重“打到車去目的地”這一結果,至于優惠多少是哪個平臺則擺在了后面,相信我,網約車大戰時乘客每個APP都會下載,能白嫖的基本不會錯過;而司機則不同,司機與平臺之間更像是一種新型的、自由的雇傭關系,盡管會同時使用多個APP,但每個APP待他們怎么樣他們是心知肚明的。
也就是說,司機更容易培養忠誠度,在打車這一行為中也扮演著更重要的角色。所以目標就是要用激勵機制使司機與平臺的利益盡可能一致,無論是補貼還是什么措施,都要盡可能偏向于司機一方。有人說,那乘客呢?別忘了,現在是在網絡外部性的語境下,乘客的兩個選擇中后者仍然是最優選擇。
所以通過生命周期的利益平衡來傾倒更多資源對司機進行長期激勵,讓其與平臺保持利益一致;乘客端則優先保證提供比出租車更便捷舒適的體驗,經濟激勵放其次,才是更合理也更健康的打法。
另外一點,平臺之間橫向爭奪倒不如縱向延伸。如果平臺能夠利用自己獲得的網絡外部性惠及上下游,何愁沒有用戶粘性呢?如果不能,并且存在有外部激勵讓用戶打破路徑依賴,現有平臺的網絡外部性就會受到威脅。
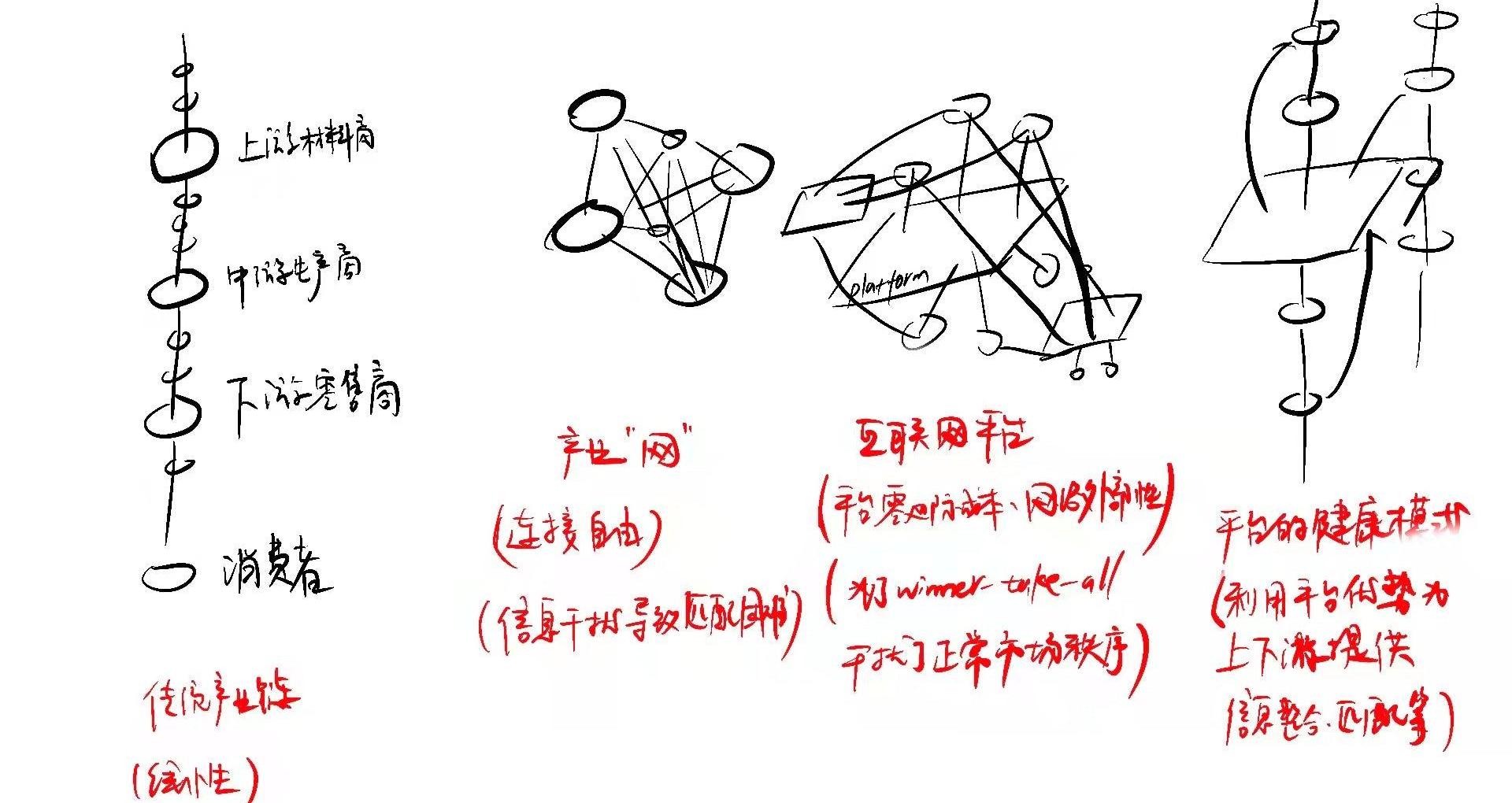
給提到的幾種模式畫了個示意圖
以上所談的全部為互聯網,是存在于計算機與計算機之間的;而如果物聯網也加入呢?計算機與計算機、計算機與計算機的連接會使網絡成長冪次級別的倍數。想想我們平均一個人擁有多少個物,每一個新的節點加入會使網絡復雜性增加多少就能夠明白了。
互聯網/物聯網對傳統商業模式的重構,還遠遠沒有停止。而互聯網的“信息生產”,本質上就是對網絡中節點產生的數據的再利用。某種角度來說,數據之于互聯網,猶如能源之于現代工業。
web2的數據孤島
前面說了,互聯網公司通過建立平臺來完成信息采集與匹配,利用零邊際成本與網絡外部性的信息生產特性賺取了大量利潤。隨著物聯網、大數據、云計算、人工智能等技術的日益發展,人類的生活將越來越“數字化”:利用數字化解決支付場景、解決工作流、解決社交聯系、解決金融業務需求……在這場數字化遷徙中,人類的“在線”時長會繼續增加,更多的人類活動將會被記錄為數據存儲在互聯網。
想想今天,睡眠監測儀可以獲得你的睡眠數據、智能家居獲得你的生活數據、智能出行工具獲得你的行動軌跡、無處不在的監控獲得你所有的體態與行為數據……而在未來,物聯網的加入只會讓你的數據資料庫更豐富,大數據與云計算會讓算法通過數據描繪出你的數字形象、會通過搜索精確定位數據與個體的聯系……
web2的數據生態顯然已經難以滿足越來越復雜的數據生產與需求活動了。
巨頭互聯網公司通過壟斷用戶數據來牟利,但本質上他們并不擁有這些數據的所有權——他們只是通過提供免費的服務來獲得了這些數據;他們也沒有完善的機制去保護這些數據,隱私泄露成為常態;數據存儲于他們的中心服務器之上,他們也不會去刻意記錄每一次拷貝的細節。最重要的是,不同機構擁有自己的數據庫,來自于無效的重復性采集;數據的存儲與管理不成系統,存在大量失真;機構間形成數據孤島,缺乏互操作措施;非正當的數據交易頻發,信任成本畸高。
紐約已提出一項法案,將比特幣作為國家機構的”支付手段\":金色財經報道,Bitcoin Magazine在社交媒體上稱,紐約已提出一項法案,將比特幣作為國家機構的”支付手段\"。[2023/1/28 11:33:12]
當web3攜手物聯網到來后,數據將呈冪次級增長,如果上面這些問題仍然得不到解決,將會誕生多少低效率的市場交易?新技術的應用價值將大打折扣。
數據孤島是行不通的。人類是社會性動物,數據也是。數據要想利用信息生產的兩大特性,就必須開放互聯。隨著各類新技術的出現,對數據的應用出現了一些可能性。本篇第二部分,我將詳細說一說數據的使用目前存在有哪些難題。
二、數據使用存在哪些難題?
現代商業活動建立在市場機制之上,按照交換對象的不同,市場通常被劃分為:商品市場、服務市場、技術市場、金融市場、勞動力市場和信息市場。
其中,技術市場可分為技術商品與技術服務,砍掉;而服務本質上也可以打包為商品;因此從我的角度,一般這么劃分:商品市場、勞動力市場、金融市場、信息市場。
前三者是我們經常可以接觸到的,信息市場這個概念卻較為抽象。顧名思義,信息市場中的交換對象是信息,比如商業信息、經濟信息、人才信息等。這些已知的信息市場所交換的信息,例如房產中介、獵頭、知網、用戶信息交易等,大多存在有專門的信息中介。使用者為獲得這類信息必須付費,否則就需要付出大量成本去尋找。
正如前文所說,目前可供交易的信息只占互聯網生產的數據的極小部分,并且基本處于灰色地帶。數據要想如能源驅動現代工業一般驅動數字化經濟,必須具備通行的行業標準、合規的市場、合適的交易規則等。而這困難重重。
隱私邊界與隱私保護
最先需要被提到的問題,就是隱私保護。我在前文提到了很多會被記錄的數據:
睡眠監測儀可以獲得你的睡眠數據、智能家居獲得你的生活數據、智能出行工具獲得你的行動軌跡、無處不在的監控獲得你所有的體態與行為數據……
這些數據對提供相應服務的公司都具有價值。例如智能空調檢測到你冬天喜歡開空調,該條數據可能會被某”巴拉巴拉離子暖風機“廠商購買,然后向您推送他家產品的廣告”比空調更健康、更省電“……廠商定向買1000條這樣的數據花的錢可能遠低于去某網首頁做個廣告。當然,理想情況下,這些錢是付給你的,畢竟你才是這條數據的所有者。
問題來了:如果你不想自己喜歡開空調這件事被人知道怎么辦?
最粗放的方式當然是直接把智能空調卸了,換上普通空調;可如果普通空調的芯片也能收集數據怎么辦?去二手市場淘一個老式電風扇可能比較靠譜。智能冰箱也是,最好換成地窖儲冰;不能坐高鐵,也不能過收費站,為了去外地只好徒步穿越無人村落……然而一通操作下來,你發現你的生活品質急劇下降,科技明明在進步,你卻退化成了原始人。
——排斥新產品與排斥數據收集顯然是不太現實的。重點在于個體要擁有自主選擇的權利,可以選擇什么樣的數據被收集,什么樣的數據不被。然而這真的現實嗎?
學過經濟學的朋友都清楚一個概念叫做“道德風險”,來源于事后的信息不對稱。即:如果由用戶選擇什么樣的數據被收集,用戶完全可以選擇不提供任何數據,或者為了用數據牟利提供虛假的數據,因為誰都不想有關自己生活的一些真實數據被人知道。
如果事情發展成這樣,討論數據是沒有任何意義的,數字化經濟也會不復存在。因為沒有人會愿意千辛萬苦最后得知你的名字叫“坎布尼特爾斯威齊巴克尼布維斯達我就不給你真名你自己慢慢猜吧但是我錢先拿走了撒油拉拉·張”。
所以數據收集一定需要是客觀默認的,這就需要做到被用戶自己也認可的足夠程度的隱私保護。這一點現行的密碼學技術已經有了一些方向。
但其實真正的問題往往是哲學性的:如何定義隱私的邊界?隱私的邊界該由個體選擇還是群體選擇?如何平衡監管與個體權利?如何處理隱私的外部性?
舉個例子,如果默認數據收集,而收集的數據是否加密則由用戶選擇,這樣一旦有危急事件政府可以選擇啟用被用戶選擇“加密”的數據,而平時涉足到商業的部分數據也是由用戶親手選擇,并由用戶獲得收益,這看似是一個不錯的解決方案。
但實際上,如果這個人是一個恐怖分子,他選擇不公布的數據中藏有能夠找到他的信息怎么辦?有人說,那就讓政府啟用啊!問題來了,在啟用前政府不知道恐怖分子是誰,為了知道是誰只能全面啟用,這又會波及到其他無辜的用戶;同時,該恐怖分子作惡會對其他人產生負外部性。如何處理這些外部性?
紐約時報:FTX與美國法明頓州立銀行的關系引發質疑:11月24日消息,FTX破產暴露出一些“奇怪”的資產,他們與美國法明頓州立銀行的關系正引發質疑。位于華盛頓州的法明頓州立銀行(Farmington State Bank)目前已更名為Moonstone Bank。今年三月Alameda Research對其母公司FBH投資1150萬美元并獲得該行股份,當前該行擁有一家分行和8400萬美元的存款,其中7100萬美元存在四個賬戶中。
目前尚不清楚FTX如何被允許購買一家美國許可銀行的股份,因為此類行為必須通過美國聯邦監管機構的批準,銀行業資深人士表示很難相信監管機構會故意允許FTX控制一家美國銀行。
據悉,法明頓州立銀行母公司FBH董事長是Jean Chalopin,他也是Deltec Bank董事長,而USDT 發行方Tether的儲備金就存儲在Deltec Bank。截至目前,Deltec Bank和法明頓州立銀行均未就此事回復置評請求。(紐約時報)[2022/11/24 8:03:11]
隱私如同文學作品,不同人對其的理解可能是千人千面的。我覺得露脖子不算什么,可能有的人會非常反感。這導致如果推行一個通用型的標準,總會有部分人的“隱私”被侵犯。如此通用型標準只能夠越寬泛越好,但如果過于寬泛,也不能稱之為“標準”了。
2、數據外部性與產權確立
談及數據的外部性,必先介紹兩個概念:非競爭性與非排他性。這兩個概念是用來規定公共品的,而外部性就是存在于公共品問題之中。
非競爭性指,當一個人消費某種產品時,不會減少或限制其他人對該產品的消費。通常來說,這意味著零/低邊際成本。我們所見到的絕大部分數據,都是可以被重復使用的,不會因為用過一次而自焚或者改變內容。與之不同的是,大學入學名額,我擠進了分數線就一定有一個人被擠下去,所以高考就是“競爭性”的。
非排他性指,當一個人在消費某種產品時,無法排除其他人也消費這一產品。什么意思呢?舉個例子,你去魚塘釣魚,不能不讓別人釣;或者你半夜去軋馬路,看到另一個軋馬路的,但你不能打他,除非給他很多錢請他離開,但如果他走了又有一個人過來軋馬路,你還是不能打他,因為馬路大家都有份。
滿足非競爭性與非排他性的就是公共品。公共品問題中存在一個著名的博弈:“公地悲劇”,意思是每個人都想盡可能多地利用公共資源謀私利,最終導致公共資源難以承受而崩潰。這是因為每個人對公共資源的使用都會對其他人產生一個“負外部性”。我們知道,在互聯網中,外部性是正的。這源于信息生產的零邊際成本,而公共資源顯然不具有這個優勢。
無論外部性是正還是負,外部性的存在意味著產權不夠明晰。而市場是無法為產權不夠明晰的商品做出合理定價的。如何看待數據的外部性?
首先我們需要就非競爭性與非排他性的概念給數據進行分類。對于非競爭且非排他的數據而言,顯然應該由政府/公共組織提供,收益歸其所有。比如天氣預報、宏觀經濟數據。這類公共數據有一個特點:他們都與個體毫無瓜葛。這是最為清晰明了的一種。
對于競爭性/排他性數據,由于在生產過程中無法明確分離權利主體,導致無法分離出數據中的公共內容與私人內容。例如某公司想通過X市一個普通人的生活數據來尋找X市的投資機會,X市總共有10萬人愿意提供這類數據,但該公司只需要1萬條。這類數據就具有外部性,因為它們的一部分內容是共享的,任意一條數據被采用都會使得其他數據受到“負外部性”影響而貶值。
又例如,我的聽歌數據,除了我自己知道,記錄該數據的軟件也一定知道,因為我使用這個軟件聽歌。除去我的行為部分,其余的部分本質上來說由軟件生產,難道這就意味著軟件也擁有我的聽歌數據的部分產權?
人做任何行為,最終一定是要與外部世界交互的;無論這種交互是物理性的,還是通過生活狀態表現出來的。這使得交互對象通常存在于你的數據里,無論他是物體還是人。既然外部性似乎不可避免,我們又如何去為數據確立明晰的產權呢?
物聯網與數據采集
前面兩點都或多或少地涉及到了數據采集。比如數據采集應該是自發而是被選擇受控制的?受個體控制的數據采集如何保證真實性?自發的數據采集如何保證不侵犯隱私?數據采集的范圍、方式與量規?
現有的數據采集可能主要發生于“上網”這一行為。舉例來說,通過支付與消費記錄獲得購物習慣、行動軌跡;通過網絡言論推測個體想法與認知;通過瀏覽記錄、應用下載記錄等獲得個人喜好等。然而智能家居、自動駕駛、監控等背后代表的可能會是另一種覆蓋面更廣的數據采集路勁——物聯網。
Filecoin上數據存儲和檢索工具Boost發布v1.0.0版本:金色財經消息,Filecoin上數據存儲和檢索工具Boost發布v1.0.0版本,Boost引入了v1.2.0存儲交易提議協議(SDPP),使存儲客戶端能夠指定傳輸數據的不同傳輸類型。該協議的先前版本v1.1.0僅支持Graphsync,這是目前Filecoin上默認且唯一的數據傳輸協議。除了v1.2.0 SDPP,Boost還支持HTTP、libp2p-http和Graphsync數據傳輸,為存儲客戶端提供了更多選項。[2022/6/24 1:28:51]
物聯網將在個體的生活中布滿裝有高速計算芯片的機器,這些機器的日常工作將會積累到大量的數據,通過計算與加工匹配入數據庫。這些更豐富的細節將會使得大數據對個體的畫像更加清晰,從簡單的行為習慣深入到思維認知、精神特性等。這從一方面對數字化經濟及社會治理具有極大意義,另一方面也引發了奧威爾式的個體隱私困境——不僅僅來源于被時刻監控的焦慮,更因為這些重要數據一旦泄露,基本上可以宣布一個數字時代公民的“死亡”。
因此,物聯網在數據采集過程應該做到什么程度、遵守什么規則,設備的可信度、設備的身份核實、設備的記賬系統等,是一定需要被提前約定并嚴格遵守的。
數據價值匹配
提到數據市場,不得不說的一個問題是數據的價值匹配。
什么意思?對比商品市場,每個商品能夠做什么我們都是非常清楚的,正是據此我們結合自己的需求給出了期望價格。比如我是一名農夫,我一天可以砍十斤柴,一斤柴可以賣二十塊,我想去市場買只斧子,斧子可以用三十天,于是我知道了:斧子總共能砍六千塊的柴,我砍柴這么累應該賺三千,那么斧子的期望價格就在三千以下。
但數據市場不同。數據的價值討論存在一個悖論:即如果我不知道一條數據的內容,我無法為其確定價值;但一旦我知道這條數據的內容,這條數據對我來說就不存在價值了。這種特性讓數據市場自然完成價值匹配變得非常困難。
好在大數據技術讓內容無法一目了然的數據完成了價值發現。數據需求者可以搜索或挖掘想要的數據,現在擺在他們面前的難題成了:如何確定這些數據內容的“正確性”?
即:如果低價值的數據偽裝成高價值數據,無法提前查看內容的數據需求者如何快捷地進行篩選以便滿足自己的需求?
密碼學中存在有一種“在不向驗證者提供任何有用的信息的情況下,使驗證者相信某個論斷正確”的技術,稱為“零知識證明”。然而,零知識證明的提供者,如何保證他提供正確論斷的動機不受高額利益的影響?設計事前激勵機制是個好主意,然而如果無法知道數據的準確價值,如何調節激勵的額度?
即使解決了數據內容與數據標題的匹配“正確性”,在海量的交易需求面前,需要的顯然是一個高并發、高性能、可自動執行交易的系統。好在區塊鏈已經走在了解決問題的路上。
數據估值
還有個容易被忽略的一點:數據估值。既然要做交易,就必須有通行被認可的估值體系,否則市場將亂象叢生。現行的數據估值方法包括:
成本法,將收集、存儲和分析數據的成本作為數據估值基準。一個明顯的問題是,大部分數據并非專門生產,而是其他活動中的附屬物;大部分數據的收集、存儲等也是同時進行;大部分數據的產權還難以進行界定。這導致它們的成本難以劃分。
收入法,預測數據的未來現金流并進行折現。然而數據所產生的效用根本難以建模,以剛才說到的價值匹配為例,如果匹配出錯,數據是有可能一文不值的,這部分概率是否要折入期望值?此外,同一個數據對不同使用者的效用是完全不同的,難以去制定一個通行的標準。
市場法,根據市場上類似數據的交易價格進行類比估值。這要求市場機制較為完善,有大量交易和數據累積。我個人認為市場法是最為合理的,但仍然存在很多問題。比如,由于價值匹配問題的存在,數據的交易是不具有穩定性的,好比開盲盒開到垃圾,這會反映到市場之中影響估值。又比如,數據是非標準化的,如何界定類似數據也會是一大問題,界定過細影響累積深度,界定過寬卻又沒什么用……
三、web3可能會從哪些途徑解決這些問題?
?1、什么是web3?
關于web3有很多形象的說法:


從網上搜羅了幾個
這些說法分別指向了web3的幾個突出特征:數據產權、社區共建共享、開源、數據透明、個體價值創造、價值層。
數據產權:個體擁有私人數據的所有權,可以利用自己的數據創造及獲取價值;私人數據由隱私技術確定邊界。與web2巨頭壟斷用戶數據相對應。
社區共建共享:在以區塊鏈為底層技術的web3背景下,共識成為價值發現的基石。社區/DAO建立于共識之上,共同建設、共同分享建設成果。與現代企業制度相對應
開源:共識的前提是開源,共建共享的前提是開源。開源是未來基于算法的信任機制。
數據透明:數據在共識認可下被記錄,可追溯、不可篡改。
個體價值創造:個體能夠作為一個完整體,通過算法建立的合作機制與他人完成分工生產。各類治理問題開始變得清晰簡明。
價值層:web3建立在貨幣等價值底層之上,這讓數據確權與交換、社區共建共享、個體價值創造等擁有了激勵引導。
web3的技術底層是區塊鏈。區塊鏈具有分布式記賬,交易可追溯、不可篡改,公開透明,智能合約可編程性、“算法+激勵機制”協同驅動等特點。我之前也寫過一篇文章可進一步了解:說說我對區塊鏈行業的一些看法
2、區塊鏈對現存問題的可能解決途徑
那么在解決前文所提的數據市場問題時,區塊鏈到底具有什么優勢呢?
來爬一下前面提過的問題,總結如下,并附上我的個人回答:
Q:巨頭互聯網公司通過壟斷用戶數據來牟利,但本質上他們并不擁有這些數據的所有權——他們只是通過提供免費的服務來獲得了這些數據;
A:用戶在區塊鏈上進行的每一筆交易都由多個礦工進行維護,交易記錄是公開透明可查詢的;目前任何需要這些數據的項目會通過分發token的方式完成冷啟動,這同時給用戶帶來了獎勵。隨著隱私、零知識證明等技術的進步,未來用戶將擁有自己的私人數據以及其產權,將可以自主決定這些數據的用處。
Q:他們也沒有完善的機制去保護這些數據,隱私泄露成為常態;
A:公鏈的共識機制決定了其安全性不受單個或多個中心的影響,因為區塊鏈的設計已經將共識機制與激勵機制相結合,所以,除去挖礦獎勵也無需專門的激勵。對于惡行,共識機制也會根據算法實施懲罰。共識機制的安全破綻來自于遵循機制規則的惡意攻擊,隨著越來越多節點的加入,這樣的機會將會越來越少。
Q:數據存儲于巨頭的中心服務器之上,他們也不會去刻意記錄每一次拷貝的細節;
A:區塊鏈將數據存儲于分布式賬本之中,由去中心化的礦工們進行維護。目前似乎無法記錄數據的查閱記錄,但這并沒有必要,因為可供查閱的記錄一直是公開透明的,未來如果是涉及到隱私的私人數據,將會由對應的算法進行保護。任何查閱都將需要支付成本并擁有交易記錄的。
Q:不同機構擁有自己的數據庫,來自于無效的重復性采集;
A:由于底層的數據共享,區塊鏈的使用者無需進行重復采集,他們只需要使用模塊化前端或者自己去爬取即可,他也完全可以和他人共享這些成果。無所謂共享,本就是公開透明的。
Q:數據的存儲與管理不成系統,存在大量失真;
A:但凡被記載在鏈上的都是經過共識機制下礦工群體的確認,由于賬本是分布式的,因此不存在丟失的問題;對于嚴重的分歧,會在社區投票后進行分叉。歷史仍然可以被真實記載。
Q:機構間形成數據孤島,缺乏互操作措施;
A:數據共享。模塊化產品將更有利于互操作。
Q:非正當的數據交易頻發,信任成本畸高;
A:所有公開數據無需非正當交易。非公開數據的交易是完全自由并且會被記載,無需單獨的信任程序,因為算法實現了這一點。
Q:如何定義隱私的邊界?隱私的邊界該由個體選擇還是群體選擇?
A:關于隱私邊界存在有一個概念叫“合理隱私期待”,在1967年凱茨訴聯邦案中為解決隱私權的邊界問題提出,由于凱茨使用的公共電話亭被聯邦官員竊聽,凱茨將其告上法庭。美國最高法院認定“保護人民而不是保護場所”,意思是只要個人的行為意愿并非想要公之于眾并刻意避免引起注意,即使發生在公開場合也是可以被保護的。然而這個概念存在有一個致命問題,那就是沒人知道“個人的行為意愿”到底是善意還是惡意。正如我前面所舉的例子,恐怖分子并非想要公之于眾并刻意避免引起注意,這樣的隱私該受到保護嗎?
我個人的觀點是,如果隱私不具有外部性,這種隱私就該受到保護。一旦個人隱私對外界產生不良影響,就需要有人來為此負責,產生負外部性的個體應該支付成本使得社會恢復原樣,就如同污水治理問題規定污水排放權一樣。
然而前面又說了,不確定負外部性來自于誰,只能查看全部個體的隱私來進行搜尋,這種行為反而又造成了另一種負外部性。是否存在有這樣的一種技術,對信息查詢者的任意問題由機器進行零知識證明驗證,從而解決上述難題呢?
對于后一個問題,我認為應由群體選擇基本邊界,外部性原則確定客觀邊界,二者并集即為法定隱私邊界。而個體可以根據個人選擇,在法定邊界的基礎上自由選擇維持隱私還是通過使用私人數據獲利。
Q:如何平衡監管與個體權利?
A:恕我愚昧。
Q:如何處理隱私的外部性?
A:區塊鏈技術由“算法+激勵機制”驅動,當交易發生在鏈上時,可以將多個交易方進行劃分,同時一組交易中的多個子交易也可根據公共/私人等不同性質進行劃分,如果能夠明確任意交易中不同節點的歸屬,就可以由此進行產權劃分,解決數據外部性問題。隱私同樣屬于數據,但隱私外部性還存在問題,即如何事前預防作惡。
Q:數據的外部性似乎不可避免,我們又如何去為數據確立明晰的產權呢?
A:以上。
Q:數據采集應該是自發而是被選擇受控制的?受個體控制的數據采集如何保證真實性?自發的數據采集如何保證不侵犯隱私?
A:我認為在安全且完備的隱私算法的技術支持下,數據采集應該是自發的。原因我之前也說過,如果由個體控制,數據市場會被大量虛假數據污染,也就不復存在的必要了。受個體控制的數據采集如果要保證真實性,必定要保證擁有足額的懲罰機制,例如一旦生產虛假數據被發現,將會從數據市場中除名。然而,在技術無法保證數據采集的隱私安全性時,我認為應該保留個體參與數據采集的選擇權利。
Q:如何確定數據內容與數據標題的匹配“正確性”?即:如果低價值的數據偽裝成高價值數據,無法提前查看內容的數據需求者如何快捷地進行篩選以便滿足自己的需求?
A:同隱私外部性部分,寄希望于新技術——你永遠可以相信“算法+激勵機制”。如果你不信的話,那改成我一直相信“算法+激勵機制”好了。
Q:零知識證明的提供者,如何保證他提供正確論斷的動機不受高額利益的影響?設計事前激勵機制是個好主意,然而如果無法知道數據的準確價值,如何調節激勵的額度?
A:同隱私外部性部分,我對此的終極期待是,驗證者的角色由人工智能擔任。現有的解決辦法可能會是,一旦驗證者作惡,會被永遠踢出節點隊伍;但受限于區塊鏈的匿名性,我們仍然無法對地址的善惡做出經驗性判斷。正是由于懲罰的失效,驗證者有動機在面臨高額利益誘惑時做出不誠實的證明。從某些角度來說,如果零知識證明驗證者由現實世界受信任的主體擔任會帶來一個更好的結果。
Q:在利用市場法為數據進行估值的過程中,如何界定非標準化數據的“類似數據”?
A:“類似數據”并非一定要從現狀界定,或許可以從生產過程入手,即按照數據不同維度的分類對數據生產時的相關交易記錄進行匹配,每個分類統計特征滿足要求的數據可以列入該分類下的“類似數據”,對于結合了所有給定分類的標的數據,或許可以用統計學手段對每個“類似數據”的市場價格進行回歸來尋找擬合值。無論如何,數據的估值存在有諸多問題,估值方法的目的不是盡可能準確,而是盡可能維持市場秩序,促進市場來完成價值匹配。
3、web3數據市場展望
總結一下本文到現在的內容。
首先,從人類生產方式與對應的組織形態的變遷過程中,我指出了信息生產兩個特征:零邊際成本與網絡外部性。互聯網借助這些特征正在逐步完成對傳統產業、商業模式的重構,也使得人類逐漸向數字化遷徙。在這樣一個趨勢中,數據的重要性開始凸顯,然而web2對數據的使用存在有各種問題。具體到數據市場交易,又存在隱私邊界與保護、數據外部性、數據采集困境、數據價值匹配、數據估值等各種問題。基于區塊鏈技術的web3是對傳統互聯網的革新,希望能通過“算法+激勵機制”結合的思路去解決眾多難題,為數據市場的實現提供一個可能。
那么,我對數據市場的期待是什么樣的呢?
首先,關于數據市場的基礎設施。關于隱私、數據外部性、零知識證明等,現有的技術需要突破。高并發、高性能的新公鏈也會是一個剛需。從我個人的角度,由于數據市場中很多地方涉及到監管、通行規則確定、個體產權等,想在公鏈上構建是不太現實的,全球性的數據市場很可能是在公鏈實現技術突破后,由現存格局對應的受信任國家間構建穩定聯盟鏈,并在底層協議規則得到協商公認后再行發展的。
然而,局部性的數據市場一定會在公鏈上先發一步。涉及到哪些數據呢?所有dapp的使用記錄、用戶在公鏈上的創作內容這類公開數據并不具用戶間交易價值,但對B端是有價值的,預計仍然會通過空投token的方式。而未來由隱私算法所記錄的私人數據將會將會開始進行原始的點對點市場,最先興起的市場預計是用來做配套服務的,比如抵押擔保交易。
隱私算法成熟后,機構或者鯨魚會隱藏自己的一部分交易,因為在傳統金融里,信息即價值。鏈上token市場將會變得更加復雜,同時由于缺乏監管,普通用戶將承擔更多的風險。類似知識付費的商業形態可能會興起,因為算法可以自動完成相關交易,這對個人創作者將更為友好。
數據交易廣義來看,還包括鏈上文化精神消費。舉個例子,視頻網站、網絡小說平臺的會員制,本質上就是一種非競爭、排他的數據產品;如果這類文化產品不免費對外開放,就需要隱私算法支持,或者一些其他的技術手段。在精神消費領域中,有一個方向一直是各位紳士們的心頭所好,更是完美契合隱私匿名的特性,具體是啥我就不說了。
盡管說了這么多,但數據市場的未來仍舊是任重而道遠。說是2022年展望,等到那一天真的來到,或許是2032年了。或許……也有可能……不會到來?
0
作者:Jonas1997
2021年NFT流行度迅速上升,誕生了許多項目,社區圍繞著它們形成。春節臨近,我們何不自己部署一個NFT來獎勵自己呢?作為對項目的忠誠或支持的展示,許多用戶選擇將他們的個人資料圖片更改為一個NF.
1900/1/1 0:00:00“讓上海成為元宇宙之都,無論元宇宙怎么發展,都離不開上海的產業優勢。”從數字經濟的專題審議會,到小組討論的高頻熱詞,“元宇宙”成為今年上海兩會關注焦點.
1900/1/1 0:00:002020年萬維網之父蒂姆·伯納斯·李在接受《名利場》雜志采訪時表達了對當前互聯網表失望的看法,他說“互聯網的精神應該是去中心化的,但在一些公司已經把互聯網當成了壟斷聯盟”.
1900/1/1 0:00:001月18日,據官方消息,風投公司AnimocaBrands宣布其在最新一輪的融資中,以50億美元的估值籌集了3.58億美元.
1900/1/1 0:00:00去年,扎克伯格在一段沉浸式視頻中宣布將Facebook更名為Meta,旨在揭示他對未來的愿景。在視頻中,他用虛擬化身展示了虛擬世界以及在那里我們能做什么,這個新的虛擬世界也被稱為「元宇宙」.
1900/1/1 0:00:001月20日,美聯儲發布報告《貨幣與支付:數字化變革時代中的美元》,闡述對發行央行數字貨幣益處和風險的看法,明確發行數字美元的先決條件,并就20余項問題在120天內向公眾征求意見.
1900/1/1 0:00:00


