






 BTC/HKD+1.57%
BTC/HKD+1.57% ETH/HKD+1.58%
ETH/HKD+1.58% LTC/HKD+0.17%
LTC/HKD+0.17% DOT/HKD-0.21%
DOT/HKD-0.21% ADA/HKD+1.13%
ADA/HKD+1.13% SOL/HKD+4.06%
SOL/HKD+4.06% XRP/HKD+0.89%
XRP/HKD+0.89% DOGE/US+2.77%
DOGE/US+2.77%作者:七哥
來源:登鏈社區
編者注:原標題為《也許是國內第一篇把以太坊工作量證明從算法層講清楚的》
對于沒有把數學學會的同學來說,如果希望從算法層了解以太坊的工作量證明是非常困難的。一本黃皮書會難倒一大批吃瓜群眾。因此,本文將試圖使用圖文和盡量簡單的數學來解釋以太坊挖礦工作量證明,包括以太坊是如何對抗ASIC1、如何動態調整挖礦難度、如何校驗挖礦正確性的。
認識工作量證明PoW
工作量證明是一種對應服務與資源濫用、或是拒絕服務攻擊的經濟對策。一般是要求用戶進行一些耗時適當的復雜運算,并且答案能被服務方快速驗算,以此耗用的時間、設備與能源做為擔保成本,以確保服務與資源是被真正的需求所使用。
摘自維基百科
這種經濟性應對政策概念,是在1993年提,直到1999年才使用Proof-of-Work一詞。
ProofofWork,直接翻譯過來是工作量證明。這個詞的中文直接聽起來有點不知所云。實際上如果我跟你說結婚證明,離職證明,那你是不是首先想到的是一張上面印著一些東西的紙呢?別人看到這張紙就知道你的確結婚了,或者你的確從某單位離職了。工作量證明從語法上也是一個邏輯,也可以理解成一張紙,通過這張紙就可以證明你的確完成了一定量的工作。這就是工作量證明的字面意思。
那工作量證明有什么特點呢?我們拋開計算機,用現實世界的例子來說明。例如我上課不認真,老師罰我把《桃花源記》抄寫十遍,我用了兩個小時的勞動,最后給老師的就是一張紙,而老師要確認我的確付出了大量勞動,其實只需要看一眼就可以了。這個例子道出了POW機制的一大特點,那就是生成需要花費大量勞動,但是驗證只需一瞬間。另外一個工作量證明的例子可以是,老師給我出一道題,我給老師的運算結果,或者說就是最后的那個數字,就是我的工作量證明。回到計算機情形下,紙當然是不存在的,所以所謂的工作量證明就是花費了很多勞動而得到的一個數了。
再說說POW最早的用途。人們在使用電子郵件的時候會收到垃圾郵件的騷擾。如果沒有成本,那么發送一百萬封郵件的確是很輕松的事情了。所以,聰明的人就會想,如果讓每一封郵件發送時候,都有一個微小的成本,那么垃圾郵件就會被很大程度的遏制了。而POW就是為了服務這個目的產生的。基本過程就是郵件接收方會先廣播一道題出去,郵件發送方發郵件的時候必須附帶上這道題的答案,這樣郵件才會被接受,否則就會被認為是垃圾郵件。
摘自:https://zhuanlan.zhihu.com/p/42694998
動態 | ConsenSys CSO計劃為新區塊鏈投資基金籌集5000萬美元:金色財經報道,即將離職的ConsenSys首席戰略官Sam Cassatt在11月15日的公告中宣布,他正在啟動的一家新的面向區塊鏈的投資公司Aligned Capital將尋求為其第一只基金籌集5000萬美元。Cassatt將繼續擔任ConsenSys的顧問,同時全職擔任Aligned Capital的創始管理合伙人。[2019/11/17]
挖礦
挖礦就是在求解一道數學方程。方程的多個可能的解被稱為解的空間。挖礦就是從中尋找一個解。不同于幾何方程,這個挖礦方程有如下特點:
1.沒有比窮舉法更有效的求解方法;
2.解在空間中均勻分布,每一次窮舉查找到解的概率基本一致;
3.解的空間足夠大,保證一定能夠找到解;
假設挖礦方程是:n=random(1,10),求n<D。
當D為10時,我們只需要運算一次就可以找到任意的n都滿足n<10,可當D=5,則平均需要兩次運算才能找到n<5,隨著D的減小,需要運算的次數就會增大。
這里的D就是通常說的挖礦難度,通過調整解空間中的符合要求的解的數量來控制求解所需要嘗試的次數,間接的控制產生一個區塊所需要的時間。使得可以調控和穩定區塊間隔時間。
當挖礦的人很多,單位時間內嘗試次數增多時,求解的速度也就更快,區塊挖出用時更短。此時則增大挖礦難度,增大平均嘗試次數,使得挖礦耗時上升。反之依然。
以太坊新區塊挖礦流程
通過父區塊可計算新區塊的挖礦難度,再求解挖礦方程。
挖礦工作量證明通過一個密碼學安全的nonce來證明“為了獲得挖礦方程解n,已經付出了一定量的計算”。工作量證明函數可以用PoW表示:
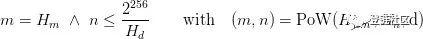
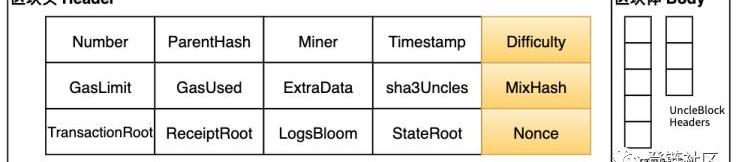
其中
1.?
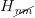
是新的區塊頭,但nonce和mixHash均為空值;2.
聲音 | 高飛發:跨行業的資源融合為區塊鏈提供更多的機遇和發展:在今日舉行的2019搶灘區塊鏈新風口會議上,創飛集團董事長高飛發談到區塊鏈企業發展時表示,第一是合規發展。在合規環境內適應監管制度是區塊鏈企業發展的必要前提,行業的趨勢也向著標準化提速;第二是產業協同。企業與政府部門、學術機構之間的緊密合作,產、學、研不同部門的合作及互通有無讓區塊鏈技術的發展更加穩健;第三是創新融合。區塊鏈技術不斷更選,對于商業模式的探索也從未停,與區塊鏈自身特性契合度較高的商業模式不斷完之中。跨行業的資源融合為區塊鏈提供更多的機遇和發展。[2019/4/13]
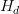
?是區塊difficulty值。;3.
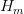
?是區塊mixHash值;挖礦方程算法返還的第一個參數值;4.
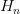
是區塊nonce值;挖礦方程算法返還的第二個參數值;5.d是一個計算mixHash所需要的大型數據集dataset;6.PoW是工作量證明函數,可以得到兩個值,其中第一個是mixHash,第二個是密碼學依賴于H和d的偽隨機數。
這個基礎算法就是挖礦方程Ethash。通過可以信任的挖礦方程求解,來確保區塊鏈的安全性。同時,挖出新塊還伴有區塊獎勵,所以工作量證明不僅提供安全保障,還是一個利益分配機制。
下面是挖礦工作量證明的計算過程:

大致流程如下:
1.根據父區塊頭和新區塊頭計算出
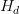
;2.在PoW開始時選擇一個隨機數作為Nonce的初始化值;3.將Nonce和作為挖礦方程Ethash的入參;4.執行Ethash將得到兩個返回值:mixHash和result;5.判斷result是否高于
金色晨訊 | 螞蟻區塊鏈上線供應鏈協作網絡“螞蟻雙鏈通” 以太坊計劃將挖礦能耗降低99%:1.以太坊開發者暫時同意阻止ASIC挖礦的新代碼。
2.君士坦丁堡硬分叉預計于1月16日啟動。
3.原中國銀行副行長王永利:要跳出“比特幣”范式看區塊鏈發展。
4.螞蟻區塊鏈正式發布上線供應鏈協作網絡“螞蟻雙鏈通”。
5.智利財政部推出區塊鏈平臺 處理公共支付。
6.印度總理莫迪第四次談及區塊鏈的重要性。
7.BCHSV挖出103MB最大區塊。
8.中本聰被評為金融界最有影響力的人物 排名第44。
9.以太坊計劃將挖礦能耗降低99%。[2019/1/5]
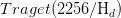
。如果是則nonce加1,繼續窮舉查找;否則,如果是則說明求解成功。返回mixHash和Nonce;6.兩個值記錄到區塊頭中,完成挖礦。
區塊難度difficulty
以太坊的挖礦難度記錄在區塊頭difficulty上,那么在它是如何動態調整的呢?
調整算法在以太坊主網有多次修改,即使以太坊黃皮書中的定義也和實際實現代碼也不一致,這里我以程序實現代碼來講解區塊難度調整算法。
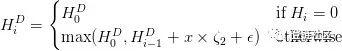
其中有:
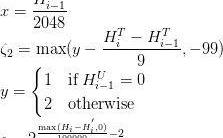
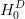
是創世區塊的難度值。難度值參數
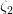
被用來影響出塊時間的動態平衡。使用了變量而非直接使用兩個區塊間的時間間隔,是用于保持算法的粗顆粒度,防止當區塊時間間隔為1秒時只有稍微高難度情況。也可以確保該情況下容易導致到軟分叉。
-99的上限只是用來防止客戶端安全錯誤或者其他黑天鵝問題導致兩個區塊間在時間上相距太遠,難度值也不會下降得太多。在數學理論是兩個區塊的時間間隔不會超過24秒。
楊東:法律、監管可能是區塊鏈未來的一個應用場景:中國人大教授楊東今日在第二屆區塊鏈新金融高峰論壇上表示,法律、監管可能是區塊鏈未來的一個應用場景;相比于互聯網、大數據、人工智能等,區塊鏈技術對于監管來說更為核心,是一項支撐性技術。對于最近落實的歐洲GDPR法案,他認為區塊鏈技術和GDPR會發生一定程度的沖突,一旦上鏈,“被遺忘權”不能被很好地落實。他還認為,數字貨幣的證券屬性是監管的深水區,其中項目本身的合規性、落地過程中的操作準則,都是對允許ICO國家的監管難題。[2018/6/6]
難度增量∈會越來越快地使難度值緩慢增長,從而增加區塊時間差別,為以太坊2.0的權益證明切換增加了時間壓力。這個效果就是所謂的“難度炸彈”或“冰河時期”。
以太坊的設想是最終從PoW過度到PoS,為了給過度施加時間壓力,所以在區塊難度中預埋了一個難度炸彈∈,他是以2的指數級增長的。如果聽過“棋牌擺米”的數學故事,就應該清楚指數級增長是非常恐怖的。
最終,在拜占庭版本中,伴隨EIP-649,通過偽造一個區塊號
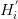
來延遲冰河時期的來臨。這是通過用實際區塊號減去300萬來獲得的。換句話說,就是減少∈和區塊間的時間間隔,來為權益證明的開發爭取更多的時間并防止網絡被“凍結”。
在君士坦丁堡版本升級中,以太坊開發者在視頻會議中表示,如果直接執行難度炸彈,那么難保以太坊能順利切換到PoS就有大量礦工離開,這很有可能極大的影響以太坊的安全性。因此,伴隨EIP-1234,再一次修改
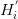
到500萬來延遲冰河時期。
這個挖礦難度調整機制保證了區塊時間的動態平衡;如果最近的兩個區塊間隔較短,則會導致難度值增加,因此需要額外的計算量,大概率會延長下個區塊的出塊時間。相反,如果最近的兩個區塊間隔過長,難度值和下一個區塊的預期出塊時間也會變短。
挖礦方程Ethash
區塊鏈鼻祖比特幣,是PoW共識,已經穩定運行10年。但在2011年開始,因為比特幣有利可圖,市場上出現了專業礦機專門針對哈希算法、散熱、耗能進行優化,這脫離了比特幣網絡節點運行在成千上萬的普通計算機中并公平參與挖礦的初衷。這容易造成節點中心化,面臨51%攻擊風險。因此,以太坊需要預防和改進PoW。因此在以太坊設計共識算法時,期望達到兩個目的:
日本Innlovi公司建立區塊鏈專業人才招聘網站,以解決業界人才短缺問題:日本Innlovi宣布,由該公司開發運營的區塊鏈專業人才招聘網站“Blockchain Jobs”已于3月28日開放提前登陸。[2018/3/29]
1.抗ASIC1性:為算法創建專用硬件的優勢應盡可能小,理想情況是即使開發出專有的集成電路,加速能力也足夠小。以便普通計算機上的用戶仍然可以獲得微不足道的利潤。2.輕客戶端可驗證性:一個區塊應能被輕客戶端快速有效校驗。
在以太坊早期起草的共識算法是Dagger-Hashimoto,由Buterin和Dryja提出。但被證明很容易受到SergioLerner共享內存硬件加速的影響。所以最終拋棄了Dagger-Hashimoto,改變研究方向。在對Dagger-Hashimoto進行大量修改,終于形成了明顯不同于Dagger-Hashimoto的新算法:Ethash。Ethash就是以太坊1.0的挖礦方程。
介紹
這個算法的大致流程如下:
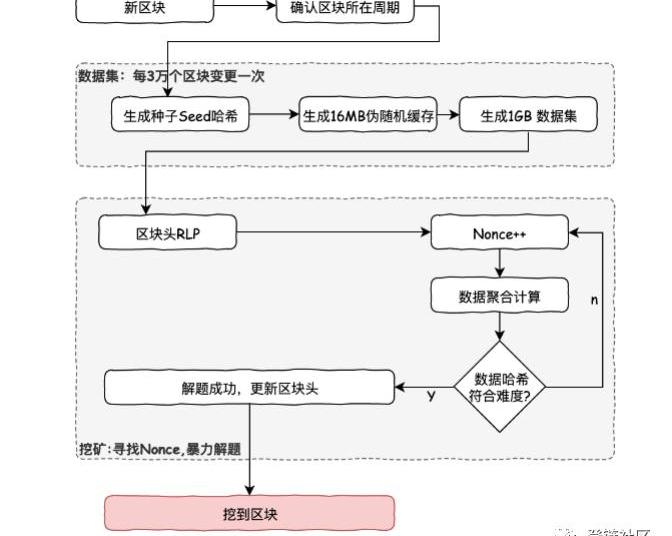
1.通過掃描區塊頭直到某點,來為每個區塊計算得到一個種子Seed。2.根據種子可以計算一個初始大小為16MB的偽隨機緩存cache。輕客戶端保存這個cache,用于輔助校驗區塊和生成數據集。3.根據cache,可以生成一個初始大小為1GB的DAG數據集。數據集中的每個條目(64字節)僅依賴于cache中的一小部分條目。數據集會隨時間線性增長,每30000個區塊間隔更新一次。數據集僅僅存儲在完整客戶端和礦工節點,但大多數時間礦工的工作是讀取這個數據集,而不是改變它。4.挖礦則是在數據集中選取隨機的部分并將他們一起哈希。可以根據cache僅生成驗證所需的部分,這樣就可以使用少量內存完整驗證,所以對于驗證來講,僅需要保存cache即可。
這里cache選擇16MB緩存是因為較小的高速緩存允許使用光評估方法,太容易用于ASIC。16MB緩存仍然需要非常高的緩存讀取帶寬,而較小的高速緩存可以更容易地被優化。較大的緩存會導致算法太難而使得輕客戶端無法進行區塊校驗。
選擇初始大小為1GB的DAG數據集是為了要求內存級別超過大多數專用內存和緩存的大小,但普通計算機能夠也還能使用它。數據集選擇30000個塊更新一次,是因為間隔太大使得更容易創建被設計為非常不頻繁地更新并且僅經常讀取的內存。而間隔太短,會增加進入壁壘,因為弱機器需要花費大量時間在更新數據集的固定成本上。
同時,緩存和數據集大小隨時間線性增長,且為了降低循環行為時的偶然規律性風險,數據大小是一個不超過上限的素數。每年約以0.73倍的速度增長,這個增長速率大致同摩爾定律持平。這仍有越過摩爾定律的風險,將導致挖礦需要非常大量的內存,使得普通的GPU不再能用于挖礦。因為可通過使用緩存重新生成所需數據集的特定部分,少量內存進行PoW驗證,因此你只需要存儲緩存,而不需要存儲數據集。
緩存和數據集大小
緩存c和數據集d的大小依賴用區塊的窗口周期Eepoch。
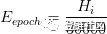
每過一個窗口周期后,數據集固定增長8MB(223字節),緩存固定增長128kb。為了降低循環行為時的偶然規律性風險,數據大小必須是一個素數。計算緩存大小公式:
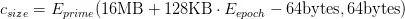
計算數據大小公式:
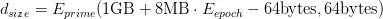
其中,求素數公式如下:
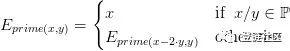
這個素數計算是從不高于上限值中向下依次遞減2*64字節遞歸查找,直到x/64是一個素數。
生成種子哈希值
種子seed實際是一個哈希值,每個窗口周期更新一次。它是經過多次疊加Keccak256計算得到的。
第一個窗口周期內的種子哈希值s是一個空的32字節數組,而后續每個周期中的種子哈希值,則對上一個周期的種子哈希值再次進行Keccak256哈希得到。

生成緩存cache
緩存cache生成過程中,是將cache切割成64字節長的若干行數組操作的。
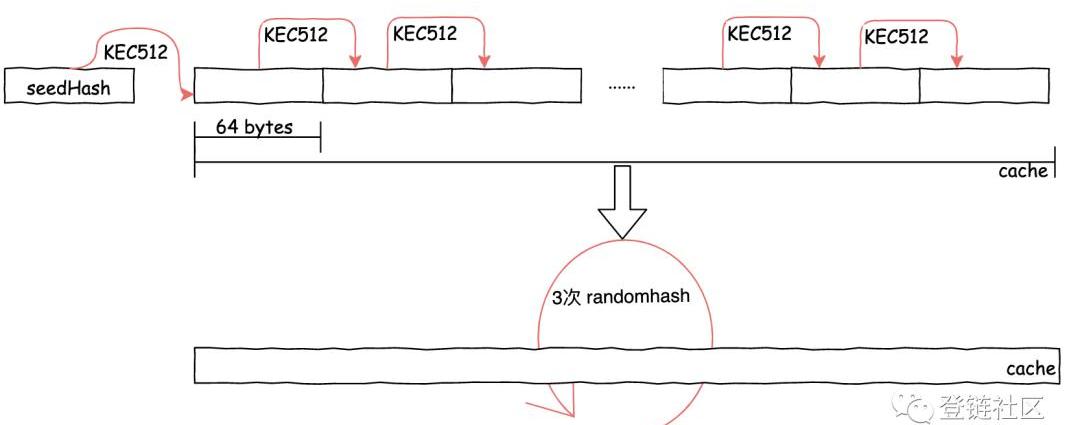
先將種子哈希值的Keccak512結果作為初始化值寫入第一行中;隨后,每行的數據用上行數據的Keccak512哈希值填充;最后,執行了3次RandMemoHash算法。該生成算法的目的是為了證明這一刻確實使用了指定量的內存進行計算。
RandMemoHash算法可以理解為將若干行進行首尾連接的環鏈,其中n為行數。
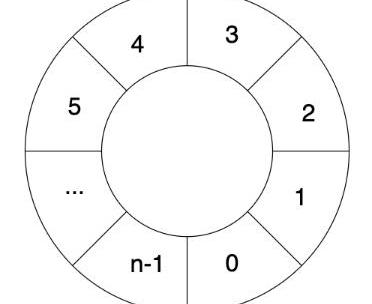
每次RandMemoHash計算是依次對每行進行重新填充。先求第i行的前后兩行值得或運算結果,再對結果進行Keccak512哈希后填充到第i行中。
最后,如果操作系統是Big-Endian(非little-endian)的字節序,那么意味著低位字節排放在內存的高端,高位字節排放在內存的低端。此時,將緩存內容進行倒排,以便調整內存存放順序。最終使得緩存數據在內存中排序順序和機器字節順序一致。
生成數據集
利用緩存cache來生成數據集,首先將緩存切割成n個16bytes大小的單元。在生成過程中時將數據集切割為若干個64bytes大小的數據項,可對每項數據mix并發生成。最終將所有數據項拼接成數據集。
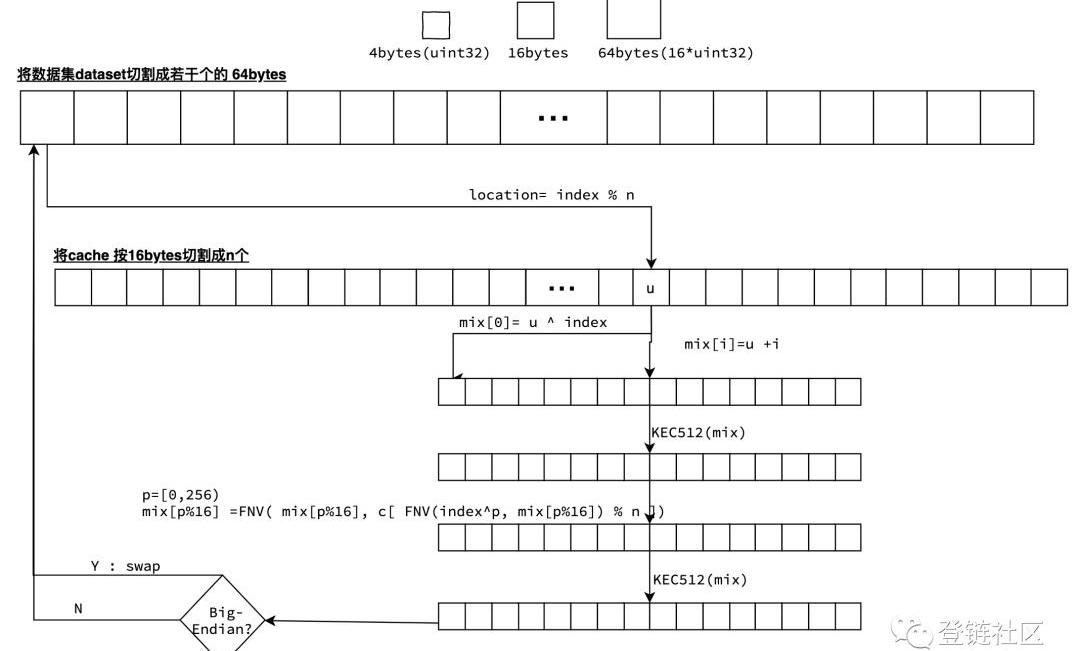
1.在生成index行的數據時,先從緩存中獲取第index%n個單元的值u;
2.數據項mix長度64bytes,分割為4bytes的16個uint32。第一個uint32等于u^index,其他第i個uint32等于u+i;
3.用數據項mix的Keccak512哈希值覆蓋mix;
4.對mix進行FNV哈希。在FNV哈希時,是要從緩存中獲取256個父項進行運算。
1)確定第p個父項位置:FNV(index^p,mix)%n;2)再將FNV(mix,cache)的值填充到mix中;其中,FNV(x,y)=x*0x01000193^y;這里的256次計算,相當于mix的16個uint32循環執行了16次。
5.再一次用數據項mix的Keccak512哈希值覆蓋mix;
6.如果機器字節序是Big-Endian的,則還需要交換高低位;
7.最后將mix填充到數據集中,即dataset=mix;
注意,在FNV哈希計算中,初始大小1GB數據集累積需要約42億次次計算。即使并發計算,也需要一定的時間才能完成一次數據集生成。這也就是為什么在啟動一個geth挖礦節點時,剛開始時會看到一段“GeneratingDAGinprogress”的日志,直到生成數據集完成后,才可以開始挖礦。
Ethash挖礦方程求解
準備好數據集dataset就可以用于工作量證明計算。依賴nonce、h、dataset可計算出的一個偽隨機數N,工作量證明就是校驗N是否符合難度要求。工作量計算由挖礦方程Ethash定義。
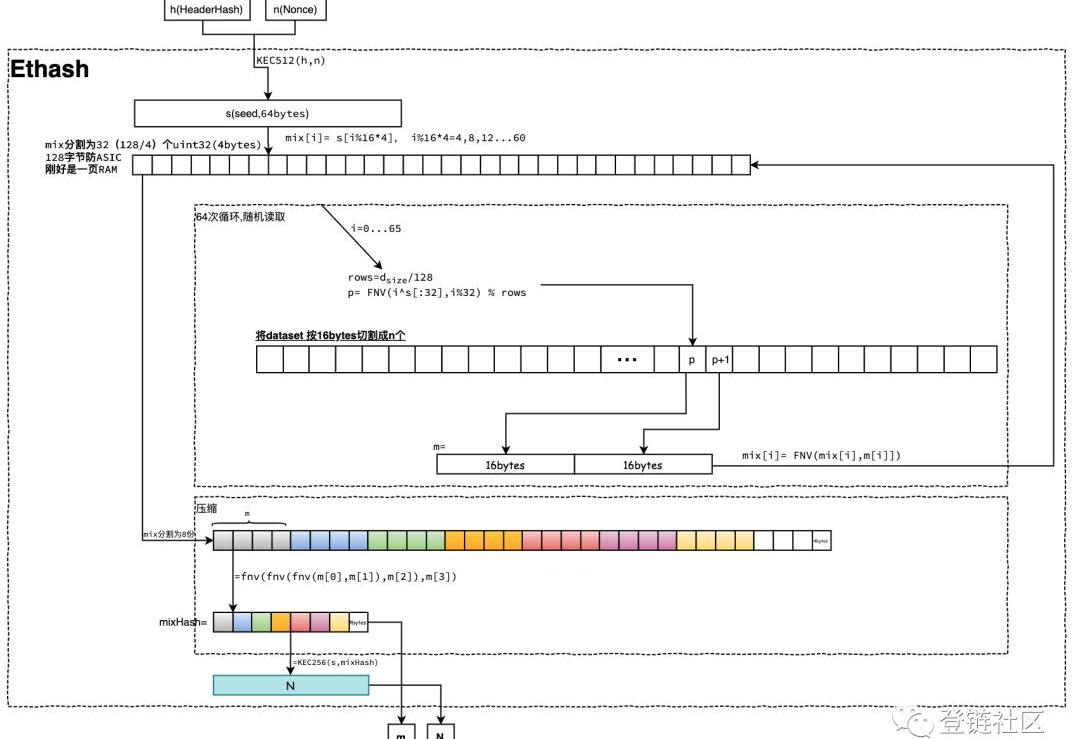
上圖是Ethash的計算流程圖。說明如下:
1.首先將傳入的新區塊頭哈希值和隨機數nonce拼接后進行KEC512哈希,得到64字節的種子seed;2.然后初始化一個128字節長的mix,初始化時分割成32個4字節的單元;使用128字節的順序訪問,以便每次Ethash計算都始終從RAM提取整頁,從而最小化頁表緩存未命中情況。理論上,ASIC是可以避免的;3.mix數組的每個元素值來自于seed;mix=s;是seed的第0、4、8...60位的值;4.緊接著完成64次循環內存隨機讀寫。每次循環需要從dataset中取指定位置p和p+1上的兩個16字節拼接成32字節的m;然后,使用fnv(mix,m)去覆蓋mix;其中,i是循環索引、s是種子seed的前32字節、rows是表示數據集dataset可分成rows個128字節。5.然后壓縮mix。壓縮是將mix以每16字節分別壓縮得到8個壓縮項。每16字節又是4小份的fnv疊加哈希值fnv(fnv(fnv(m,m),m),m);6.拼接這8個壓縮項就得到mix的哈希值mixHash;7.最后將seed和mixHash進行KEC256哈希得到偽隨機數N;8.最終,返回這兩個參數:mixHash和N;
隨著新冠肺炎疫情的全球大流行,人類在全方位、艱難地抗擊尚屬未知的COVID-19病。面對沒有確定的COVID-19治療方法,也沒有可以臨床的疫苗,至少一年、很可能常態的新型病流行的嚴峻形勢,
1900/1/1 0:00:00來源:萬向區塊鏈,本文有刪減4月23日,萬向區塊鏈蜂巢學院線上公開課直播間邀請了PlatON社區負責人余凱做客,為大家帶來《從傳統游戲看“區塊鏈游戲”的發展》.
1900/1/1 0:00:00?一、反脆弱性 如果你問我在加密貨幣世界里做投資什么最重要,我會毫不猶豫的回答你:反脆弱性。是的,你沒有聽錯,不是認知,不是理智,也不是其它七七八八的東西,就是反脆弱性.
1900/1/1 0:00:00撰文:AlfaBlok,CryptoEspa?ol頻道博主,前微軟員工編譯:PerryWang 來源:鏈聞 AMM是DeFi中最紅火的一個領域,其全稱是自動化做市商.
1900/1/1 0:00:00作者:LiangChe 來源:比推bitpush.news本周美國的一些居民陸續收到了美國國稅局發放的1200美元救濟金,很多人使用這些錢來購買加密貨幣.
1900/1/1 0:00:00本文翻譯自AvivZohar的博文《TheIncredibleMachine》。這是小編看過的最接地氣、最好理解的“零知識證明”解釋.
1900/1/1 0:00:00


