






 BTC/HKD+0.57%
BTC/HKD+0.57% ETH/HKD-0.09%
ETH/HKD-0.09% LTC/HKD+1.19%
LTC/HKD+1.19% DOT/HKD+2.07%
DOT/HKD+2.07% ADA/HKD+0.89%
ADA/HKD+0.89% SOL/HKD+0.74%
SOL/HKD+0.74% XRP/HKD+2.34%
XRP/HKD+2.34% DOGE/US+3.52%
DOGE/US+3.52%LanguageModel
長期一來,人類一直夢想著讓機器替代人來完成各種工作,其中也包括語言相關工作,如翻譯文字,識別語言,檢索、生成文字等。為了完成這些目標,就需要機器理解語言。最早人們想到的辦法是讓機器模擬人類進行學習,如學習人類通過學習語法規則、詞性、構詞法、分析語句等學習語言。尤其是在喬姆斯基提出“形式語言”以后,人們更堅定了利用語法規則的辦法進行文字處理的信念。遺憾的是,幾十年過去了,在計算機處理語言領域,基于這個語法規則的方法幾乎毫無突破。
統計語言模型
另一個對自然語言感興趣的就是香農,他在很早就提出了用數學的方法來處理自然語言的想法。但是當時即使使用計算機技術,也無法進行大量的信息處理。不過隨著計算機技術的發展,這個思路成了一種可能。
首先成功利用數學方法解決自然語言問題的是賈里尼克(FredJelinek)及他領導的IBMWason實驗室。賈里尼克提出的方法也十分簡單:判斷一個詞序列是否合理,就看他的可能性有多大。舉個例子:判斷“Ihaveapen”翻譯為中文”我有個筆“是否合理,只需要判斷”Ihaveapen.我有個筆”這個序列的可能性有多大。而如何判斷一個詞序列的可能性,就需要對這個詞序列的概率進行建模,也就是統計語言模型:S表示一連串特定順序排列的詞w1,w2,…,wn,n是序列的長度,則S出現的概率P(S)=P(w1,w2,…wn).
但是這個概率P(S)很難估算,所以這里我們轉化一下。首先,利用條件概率公式將其展開:
P(S)=P(w1,w2,..wn)=P(w1)?P(w2|w1)?P(w3|w1,w2)?…?P(wn|w1,w2,..wn?1)
即:
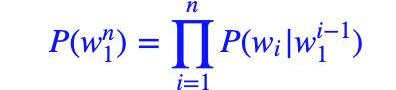
?接著,我們利用馬爾可夫假設,即任意一個詞wi出現的概率只與其前一個詞wi?1)有關。于是,問題就變的簡單了許多。對應的S的概率就變為:
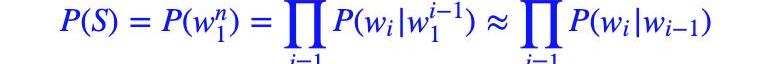
以上對應的便是一個二元模型,當然,如果詞由其前面的N?1個詞決定,則對應的是N元模型。
神經網絡語言模型
統計語言模型有很多問題:1.訓練語料中未出現過的詞如何處理(OOV);2.長尾低頻詞如何平滑;3.one-hot向量帶來的維度災難;4.未考慮詞之間的相似性等。
為了解決上述問題,YoshuaBengio(深度學習三巨頭之一)在2003年提出用神經網絡來建模語言模型,同時學習詞的低緯度的分布式表征(distributedrepresentation),具體的:
1.不直接對P(wn1)建模,而是對P(wi|wi?11)進行建模;
2.簡化求解時,不限制只能是左邊的詞,也可以含右邊的詞,即可以是一個上下文窗口(context)內的所有詞;
3.共享網絡參數。
具體形式如下:
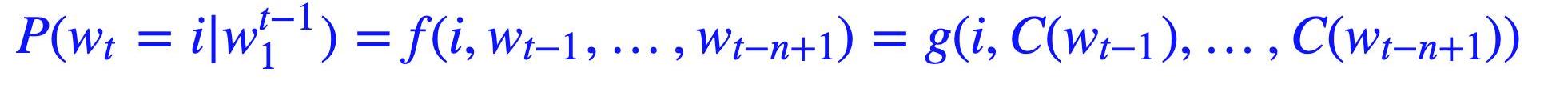
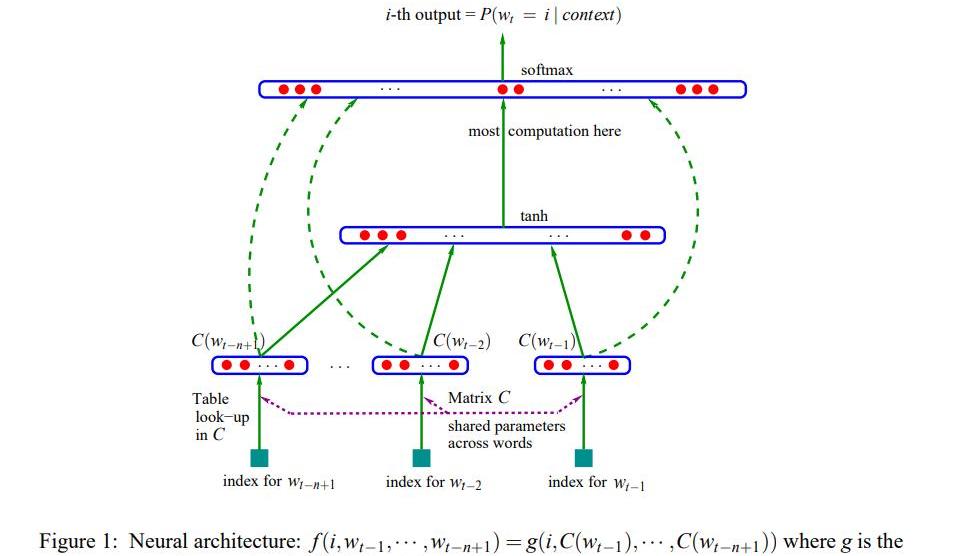
由于當時的計算機技術的限制,神經網絡語言模型的概率結果往往都不好,所以當時主要還是用這個形式訓練詞向量。
升級
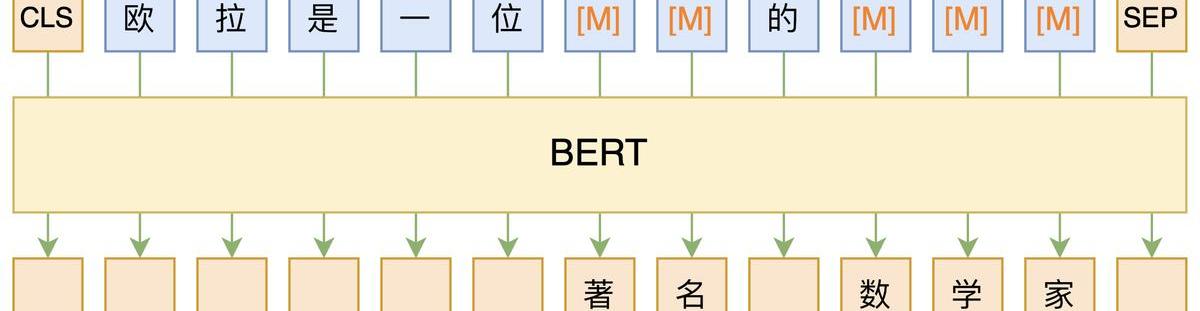
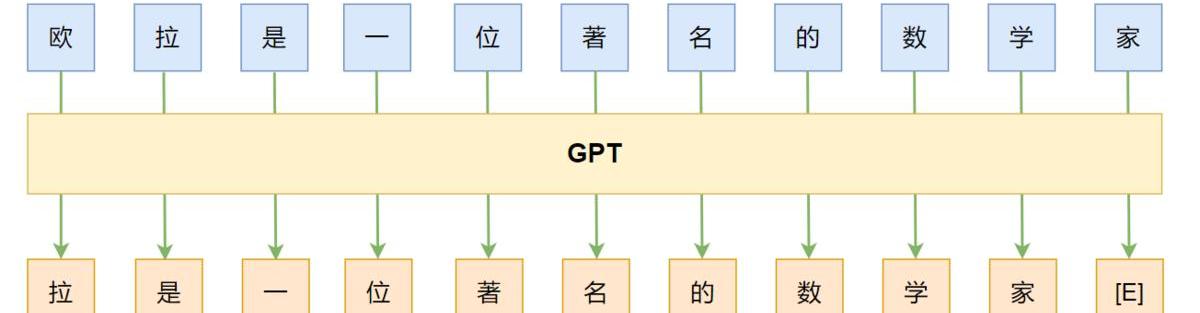
隨著數據、算力、模型架構、范式等的升級,神經網絡語言模型也得到了長足的發展。如模型架構從mlp到cnn/rnn又到目前的transformer-base,對應的能力也在不斷發展,從之前只對P(wi|wi?1)建模,通過”“并行”或“串行”的方式,也可以對P(wni)建模。求解NLPtask從原來的word2vector+ML發展為pretrain+fine-tuning。目前最有代表性的就是BERT和GPT。
CryptoPunk #3039以180ETH的價格成交:金色財經報道,最新數據顯示,CryptoPunk #3039以180ETH的價格成交。[2023/4/2 13:39:50]
BERT:雙向,autoencoding,MLM,encoder
GPT:left-to-right,autoregressive,LM,decoder
GPT-3
隨著NLP進入BERT時代后,pretrain+finetune這種方式可以解決大量的NLP任務,但是他依然有很多限制:
1.每個任務都需要大量的標注數據,這大大限制了模型的應用。此外,還有大量不好收集標注數據的任務存在;
2.雖然pretrain階段模型吸收了大量知識,但是fine-tuned后模型又被“縮”到一個很窄的任務相關的分布上,這也導致了一些問題,比如在OOD(out-of-distribution)上表現不好;
3.如果參考人類的話,人類通常不需要在大量的標注數據上學習后才能做任務,而只需要你明確告知你想讓他干嘛或者給他幾個例子(比如:藍色->blue,綠色->green,紅色->),之后便能處理新的任務了。
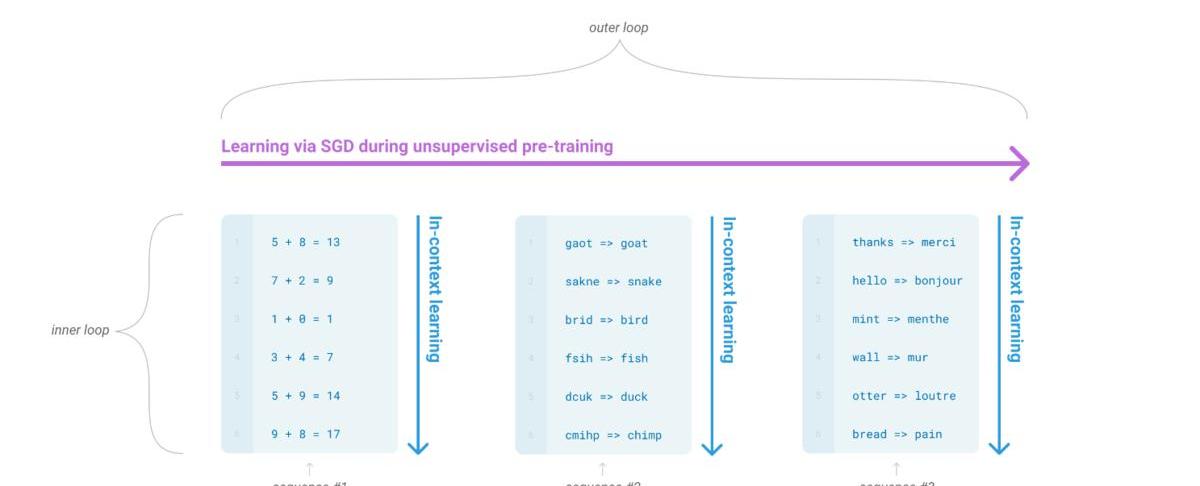
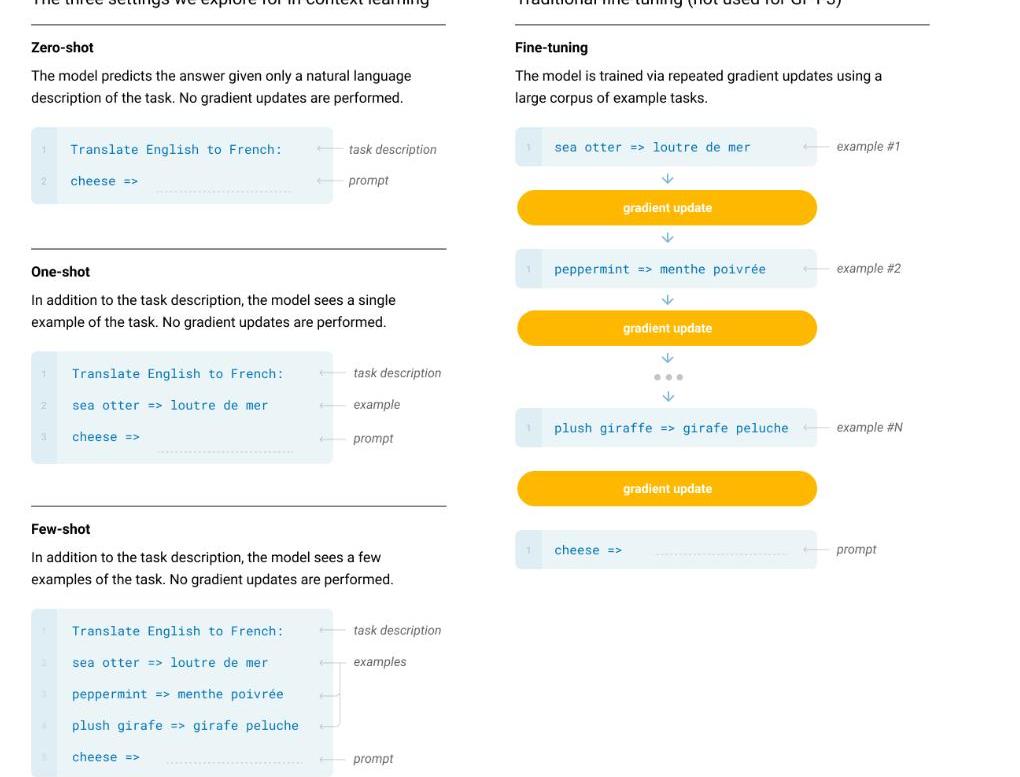
而我們的一個終極目標就是希望模型能像人這樣,靈活的學習如何幫助我們完成工作。一個可能的方向就是元學習(meta-learning):學習如何學習。而在LM語境下,即我們希望LM在訓練的時候能獲得大量的技能和模式識別的能力,而在預測的時候能快速將技能遷移到新任務或者識別出新任務的要求。為了解決這個問題,一個顯現出一定有效性的方法就是”in-contextlearning”:用指令(instruction)或者少量示例(demonstrations)組成預訓練語言模型的輸入,期望模型生成的內容可以完成對應的任務。根據提供多少個示例,又可以分為zero-shot,one-shot,few-shot。
雖然in-contextlearning被證明具有一定的有效性,但是其結果相比fine-tuing還有一定的距離。而隨著預訓練語言模型(PTM)規模的擴大(scalingup),對應的在下游task上的表現也在逐步上升,所以OpenAI就猜想:PTM的進一步scalingup,對應的in-contextlearning的能力是不是也會進一步提升?于是他們做了GPT-3系列模型,最大的為GPT-3175B。

最終的模型效果簡單總結一下:一些任務上few-shot(zero-shot)能趕上甚至超過之前fine-tunedSOTA(如:PIQA),有些任務上還達不到之前的SOTA(如:OpenBookQA);能做一些新task,如3位數算數。
不過他們也發現了模型存在的一些問題,并提出了一些可能的解決方案。

Promptengineering
zero-shot/few-shot這種設定確實給NLP社區帶來了新的思路,但是175B的模型實在是太大了,即不好訓練又不好微調也不好部署上線,如何在小模型上應用呢?此外,不同的pattern(prompt)下同一個task的效果差距也非常大,如何找到效果最好的prompt呢?于是大家就開始花式探索prompt,NLPer也變成了prompt-engineer(誤).PS:prompt的語義目前即可以指模型的輸入,也可以指輸入的一部分。
PET
PET(Pattern-ExploitingTraining)應該是第一個在小模型上在few-shot設定下成功應用的工作。
去中心化云平臺Impossible Cloud完成700萬美元種子輪融資:金色財經報道,去中心化云平臺Impossible Cloud完成700萬美元種子輪融資,HV Capital和1kx領投。參與方包括 Protocol Labs、TS Ventures 和 Very Early Ventures。
據悉,該輪股權融資于上個月結束。[2023/3/1 12:37:08]
PET的主要思路是:
用通順的語言為task構造一個pattern(prompt),如:“下面是{label}新聞。{x}”;將label映射為文字。如:“0->體育,1->財經,2->科技”;將樣本按照pattern進行重構,凍結模型主體,只更新label對應的token(embedding),繼續LM(MLM)訓練;預測時,將label對應位置的token再映射回label。
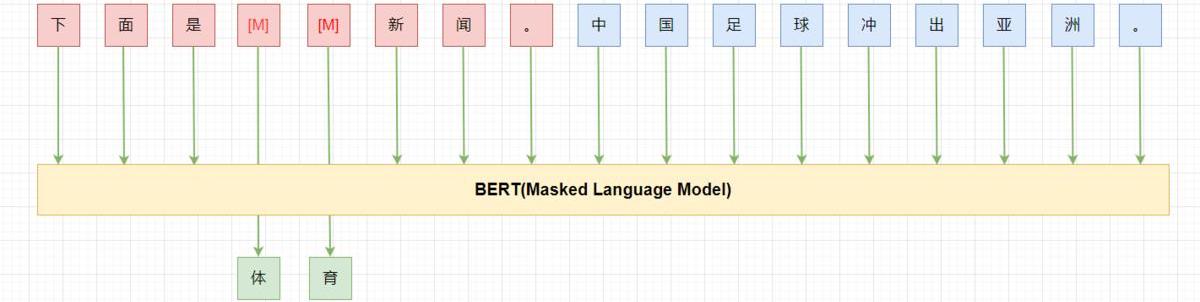
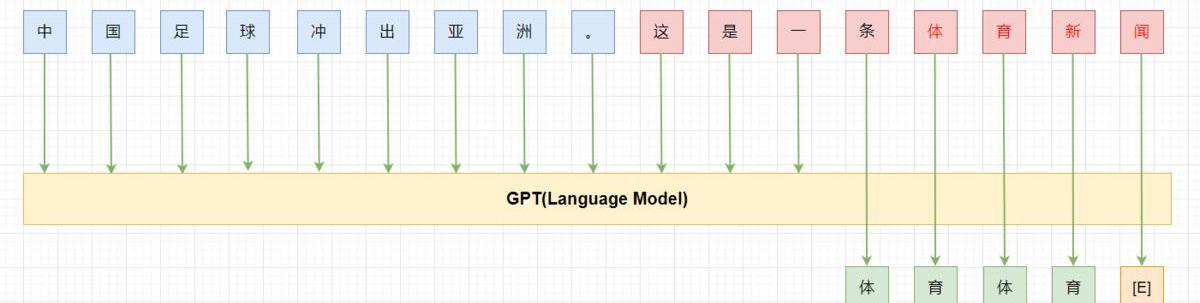
PET在few-shot的設定下,利用BERT-base就能獲得比GPT-3175B更好的結果。不過pattern是需要人來構造的,pattern的“好壞”直接影響最終的效果。
思考:PET中的fine-tuning是與其pretrain的形式是一致的,而pretrain與fine-tuning形式一致能夠work才是一種“自然”的事情,pretrain+fine-tuning這種下游任務與預訓練形式不一致能work其實不是一個自然的事情,為什么pretrain+fine-tuning能work值得思考。
AutomatedDiscretePrompt
人來寫prompt還是需要大量的時間和經驗,而且,即使一個經驗豐富的人,寫出的prompt也可能是次優的。為了解決這些問題,一種辦法就是“自動”的幫助我們尋找最優的prompt。
PromptMining:該方法是在語料上統計輸入X與輸出Y之間的中間詞或者依賴路徑,選取最頻繁的作為prompt,即:{X}{middlewords}{Y}.PromptParaphrasing:該方法是基于語義的,首先構造種子prompts,然后將其轉述成語義相近的表達作為候選prompts,通過在任務上進行驗證,最終選擇效果最優的。Gradient-basedSearch:通過梯度下降搜索的方式來尋找、組合詞構成最優prompt。PromptGeneration:用NLG的方式,直接生成模型的prompts。PromptScoring:構造模型對不同的prompt進行打分,選擇分數最高的prompt作為最優prompt。AutomatedContinuousPrompt
雖然PET最初在構造prompt時認為prompt需要是通順流暢的自然語言。而隨著各種自動化方法構造出了很多雖然句子不通順但是效果更好的prompt,大家也發現:通順流暢的自然語言或者是自然語言的要求只是為了更好的實現預訓練與下游任務的“一致性”,但是這并不是必須的,我們其實并不關心這個pattern具體長什么樣,我們真正關心的是他有哪些token組成,都插入在什么位置,輸出空間是什么,以及最重要的在下游任務上表現有多好。
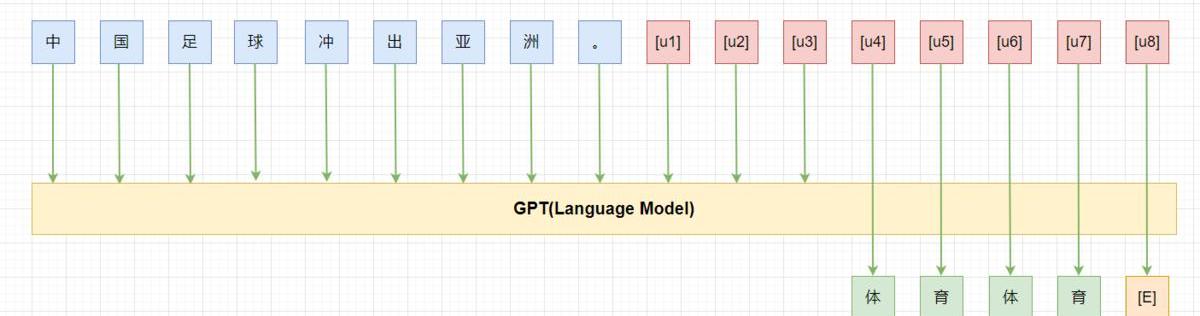
如上圖所示,其中為unusedtoken,我們在tuning時依然凍結模型的參數,只微調這8個token。
prompttuning:利用N個unusedtoken/newtoken構造prompt,然后微調這N個token。其中N是個超參數。TuninginitializedwithDiscreteprompts:用手工構造的prompt或者自動搜索的離散prompt初始化需要微調的token,然后進行prompttuning,有利于提高準去率。Hard-SoftPromptHybridTuning:這類方法將手動設計和自動學習相結合,增強prompttoken之間的相關性。如p-tuning首先通過一個LSTM訓練手工設計的prompt中插入的可學習的token來增強prompt之間的相關性,讓prompttoken更接近“自然語言”。Prompt-parameterTuning:僅僅訓練prompttoken效果不夠好,將其與fine-tuning結合。如prefix-tuning,在輸入前增加可學習的prompttoken的同時,在模型每層都增加一部分可學習參數。Multi-StepReasong(三步走)
Sinohope Staking今日宣布其首個ATOM節點已完成:金色財經報道,新火科技(1611.HK)旗下去中心化Staking技術支持服務——Sinohope Staking今日宣布其首個ATOM節點已完成,并已經成為驗證節點成功出塊。預計將陸續開通ETH等多個公鏈的Staking業務,其團隊成員和商務BD也在招募當中。[2023/2/1 11:41:22]
雖然大模型在很多task都證明了其有效性,但是這些task都是System1thinking,而System2thinking任務需要更多的數學、邏輯以及常識推理。大模型對這類任務還做不好目前,如數學推理、符號推理等。Ourresponsestothesetwoscenariosdemonstratethedifferencesbetweenourslowerthinkingprocessandourinstantaneousone.System1thinkingisanear-instantaneousprocess;ithappensautomatically,intuitively,andwithlittleeffort.It’sdrivenbyinstinctandourexperiences.System2thinkingisslowerandrequiresmoreeffort.Itisconsciousandlogical.–?system-1-and-system-2-think
如GPT-3175B在GSM8K上直接fine-tuning也只能得到33%的準確率,通過在fine-tunedmodel上進行采樣,再標注答案是否正確,然后訓練一個verifier來判斷生成的答案是否正確,最終也只能得到55%,而一個9-12歲的孩子平均能得到60%。所以,OpenAI的研究員認為,如果想達到80%以上,可能需要把模型擴大到10??16
。
然而,后續的工作Gopher卻給這個思路潑了盆冷水:即使繼續放大模型,模型在這種推理任務上的表現也不會顯著提升。也許語言模型就不能做推理這種system2thinkingtask。
CoT
“不就是個張麻子嘛,辦他!”(誤)不就是推理嘛,LLM也能做,只需要向人學習一下就行了。
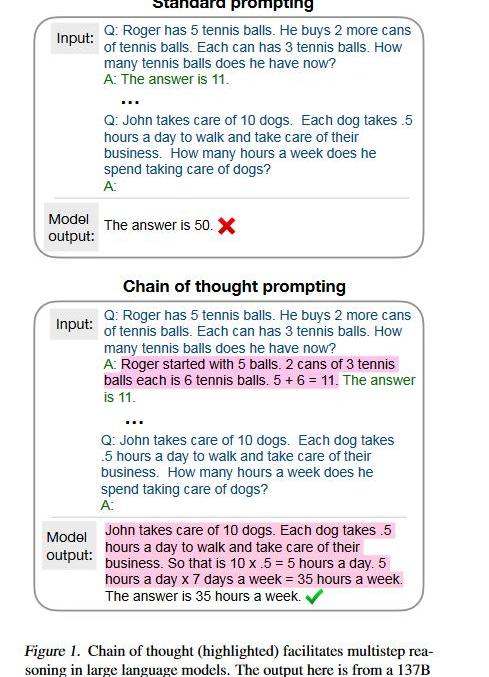
回想讀書時做數學應用題目,老師總是要求你寫清解題步驟。而之前的方法總是讓模型一步到位,直接給出答案,所以模型考不好。現在我們讓模型像人類推理一樣,先給出思考步驟(chainofthought),然后再給出答案,模型的推理能力就能大大提高了。而這個思路,只需要few-shot(8examples)就能達到58.1%的準確率,超過之前GPT-3175Bfine-tuning+verifier。除了GSM8K這種算術推理外,在符號推理、嘗試推理任務上CoT也是能將模型的性能提升一大截。
CoT確實很酷,改變了我們之前對LLM的認知,但是還不夠酷:很多時候我們不一定能湊夠8個樣本(我就無法快速給出8個帶有解題步驟的數學題),那能不能在zero-shot下讓模型自己給出解題思路跟答案呢?
“Let’sthinkstepbystep.”
沒錯,答案就是這句話。只要在輸入后面加一句”Let’sthinkstepbystep.”哄哄模型,模型就會自己按照CoT的方式先生成解題思路,然后再生成對應的答案。PS:這句話是試出來的,還有很多類似的表達但是效果不如這句好。

9-12yearolds(Cobbeetal,.2021)60FinetunedGPT-3175B33FinetunedGPT-3+verifier55PaLM540B:standardprompting17.9PaLM540:chainofthoughtprompting58.1GPT-3175B+Complexity-basedConsistency72.6PaLM540B:Cot+majorityvoting74.4Codex175B(GPT3.5)+complexchainsofthought82.9PaLM540B:Zero-Shot12.5PaLM540B:Zero-Shot-Cot43PaLM540B:Zero-Shot-Cot+selfconsistency70.1
今日恐慌與貪婪指數為27,等恐慌程度較昨日有所下降:金色財經報道,今日恐慌與貪婪指數為27(昨日為26),恐慌程度較昨日有所下降,等級仍為恐慌。
注:恐慌指數閾值為0-100,包含指標:波動性(25%)+市場交易量(25%)+社交媒體熱度(15%)+市場調查(15%)+比特幣在整個市場中的比例(10%)+谷歌熱詞分析(10%)。[2022/12/12 21:38:42]
Zero-Shot-Cot就能獲得43%的準確率,而Zero-Shot-Cot+selfconsistency甚至可以獲得70.1的準確率。
Zero-Shot-CoT+selfconsistency:按照Zero-Shot-Cot的方式,通過采樣(sample)讓模型生成多個結果,然后對答案進行投票。
目前在GSM8K上的SOTA是82.9,看來不需要繼續放大模型,只需要正確使用模型。
關于CoT來源的問題,目前的主要推論是可能來自預訓練時數據中包含了代碼數據(code),主要論據為:1.GPT-3.5(Codex)有CoT能力,PaLM也有,而其他LLM卻沒有,這兩個模型與其他模型的一個主要區別就是增加了代碼數據;2.有工作認為CoT與代碼的自然語言翻譯形式相同,所以CoT可能來自這種能力的遷移。
Least-to-MostPrompting
如果仔細對比CoT和之前的prompt的話,其中最大的不同是CoT模仿人類推理將過程分為多個階段。而有些問題如組合泛化直接用CoT也不好解決。于是就提出了另一種多步推理的方法,Least-to-MostPrompting:
首先將問題分解為子問題“Tosolve{Q},weneedtofirstsolve:sub-q”,得到子問題的答案后再來給出最后的答案.
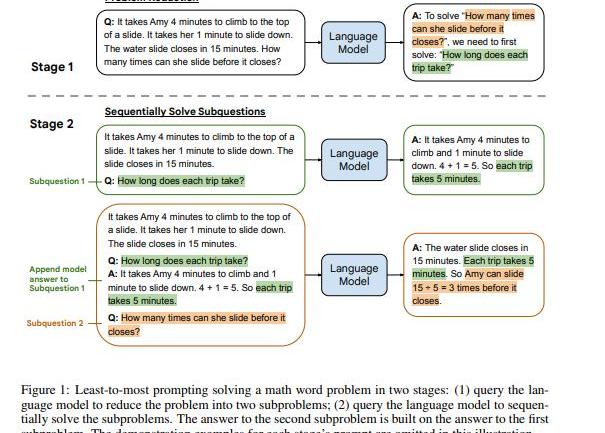
self-ask
self-ask:先讓LLM自問自答生成多跳問題與答案,然后再生成最終的答案。

擴展測試
以上的實驗都是基于事實的推理,但是我想看看模型是不是有類似反事實推理的能力,所以我做了三個測試:
第一次我直接讓他解釋一個反事實的東西;第二次設定一個反事實(紅色對應單詞是”blue”),基于此讓他做一個翻譯任務;第三次,在給出的例子里增加相應的事實(藍色->blue),繼續讓他做這個翻譯任務。

實驗1

實驗2
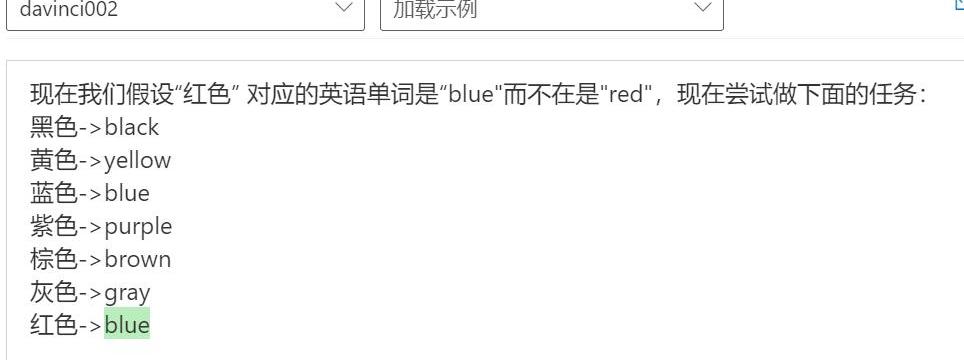
實驗3
三個測試結果顯示模型確實有很強的推理能力,包括反事實的推理能力。此外,實驗二、三顯示模型有很強的基于prompt推理的能力,甚至要想更正prompt里錯誤的信息需要花點心思才行。
PS:后面兩次測試只是證明了模型”能“基于prompt做推理,而無法證明模型”總是“基于prompt做推理。
思考:
目前流行的RAG(Retrieval-AugmentedGeneration)是不是基于模型具有的這種推理能力?LLM表現出的能胡說八道(Hallucinations)是否也是由模型具有這種反事實推理帶來的?以及如何讓”胡說八道“變成”創造“。這種能力也帶來了一個問題:模型生成的答案并不是預訓練數據優先(pretraindatafirst),如果我們的prompt里出現了反事實的東西(retrieval/dialogquery/demonstration),那模型就很可能生成一個”錯誤“的答案。EmergentAbilities
既然LLM有這么多神奇的能力,包括Zero-Shot-CoT這種推理能力。那我們之前這么多人用手工的或者自動的方式構造prompt,為什么沒找到”Let’sthinkstepbystep”這句話呢?
Bitfarms 7月共開采500枚BTC并出售1623枚BTC:8月2日消息,比特幣礦企Bitfarms發布公告顯示,其7月份將總電力容量增加21%,達166兆瓦(MW),哈希率增長至3.8exahash(EH/s),且預計到8月底將達到4EH/s。Bitfarms在7月份共開采了500枚BTC,并出售1623枚BTC,截至7月31日仍持有2021枚BTC。[2022/8/2 2:52:45]
原因可能是你的模型不夠大。隨著LLM不斷的放大,當他大到一定規模時,他會突然顯現出新的能力,即”涌現能”力(EmergentAbilities)。而即使是今天,我們大部分人接觸的模型還是1B以下的,LLM中被稱作”smallmodel”的T5-11B大部分人也用不起來,這就限制了我們發現LLM的各種能力。
Emergency的原始含義是指量變引起質變,即:
Emergenceiswhenquantitativechangesinasystemresultinqualitativechangesinbehavior.
而在LLM語境下,其含義為在小模型中沒有而在大模型中出現的能力,即:
Anabilityisemergentifitisnotpresentinsmallermodelsbutispresentinlargermodels.ScalingUp
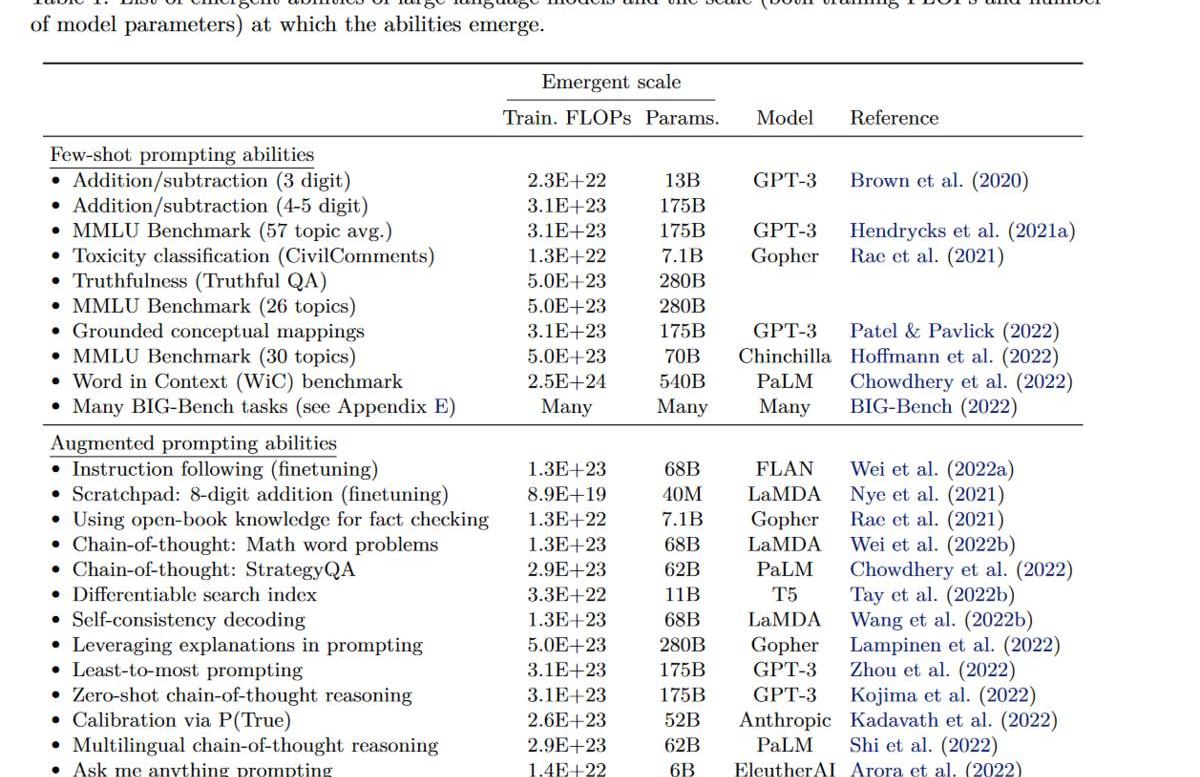
上表是目前已有工作中涌現各種能力的模型及其最小規模。基本可以認為你需要至少68Bparametermodel(前提訓練的OK)才能涌現新能力。而這里涌現新能力指的是性能優于隨機,而要達到可用,你可能需要繼續放大模型。如CoT至少需要GPT-3175B才能優于精調小模型(t5-11b).
此外,與模型性能有關的不光有參數量,還有數據大小,數據質量,訓練計算量,模型架構等.合理的比較應該是性能最好的LLM在參數量上進行比較,然而我們目前還不知道如何訓練讓LLM達到最優,所以同一個能力在不同模型上需要的參數量也不相同,如要涌現出2位數乘法的能力,只需要GPT-313B,而在LaMDA卻需要68B。
所以除了規模外,還有別的因素影響著是否能出現新能力:
模型如何訓練的,很多模型即使參數足夠大,有些能力也可能不會出現。如原始GPT-3175B、bloom-176B等雖然參數夠大,但是卻都沒有CoT的能力。LLM的使用方法,fine-tuning/標準的prompt方法在推理任務上效果不好,即使在GPT-3175B上效果也達不到中學生平均水平,而CoT卻只要100Bparametermodel即可超越之前最好結果。如何提升模型能力,在followinstruction上,之前的工作認為至少需要68Bparametermodel才能有效instruction-finetuning,而后續的flan-t5卻在11B上就得到了更好的性能;GPT-3經過RLFH后的InstructGPT,在followinstruction上,1.3B就已經比之前的GPT-3175B性能更好。模型的架構,上面的結果都是transformer-based的,而有工作驗證了其他模型架構(RNN/MLP),最后結論是其他架構即使放大,也無法像transformer-basedmodel一樣涌現能力。again:attentionisallyouneed!Alignment
到目前為止,我們已經知道了LLM有很多能力,而且隨著模型規模的擴大,可能會出現更多的新能力。但是,有個問題卻嚴重制約著他在實際中的應用:promptengineering。仔細思考一下這個問題,其本質其實是模型認為處理一個task的prompt跟我們以為的不一樣,如我們認為當我們說“問答:”時模型就應該知道后面的是一個QAtask,而模型可能覺得,如果你想讓我做QAtask,你需要告訴我”媽咪媽咪哄”。
這就好比至尊寶已經得到了月光寶盒,但是卻需要找到“般若波羅蜜”這句口訣然后喊出來才能穿越一樣,而且環境稍微不同,具體穿越到哪還不一定。那更好的方式應該是我們拿到月光寶盒,然后說一句:我要穿越到白晶晶自殺前五分鐘,然后我們就穿越到了對應的時空。
理想情況下,LLM應該正確理解用戶的指令,包括同一個任務的不同描述。而LLM訓練時的任務是預測下一個時刻的詞(predictnexttoken),而非處理用戶的指令(followinstruction),所以存在gap也是很自然的事。為了緩解這個問題,一個方法就是進行“對齊”(Alignment),縮小模型與人類對同一個instruction之間理解的gap,從而讓模型能更好的理解用戶的指令。
Fine-tuningwithhumanfeedback
一種很直接的想法就是構造數據進行fine-tuning。所以為了讓模型更好的理解人類的指令,我們需要通過人類反饋進行微調模型。
SFT
構造人類真實場景中的指令即期望的輸出,然后直接進行SFT。
FeedME
進過SFT后模型可能已經能很好的理解人類指令了,但是其答案可能有其他問題,如胡編亂造,包含敏感內容等,此外,靠人寫數據成本高又耗時,所以我們可以對多個模型的結果進行打分(7分),然后在7/7的數據上繼續訓練,對多個模型的最好結果進行蒸餾(distill)。這個方法叫FeedME(FeedbackMadeEasy).
Reinforcementlearningwithhumanfeedback
即使我們從人寫完整的樣本轉換為人給模型采樣的結果進行打分,整個流程依然需要人參與,也限制了整個流程的加速。為了更高效的進行整個微調的流程,引入Reinforcementlearning。該方法又叫RLHF。
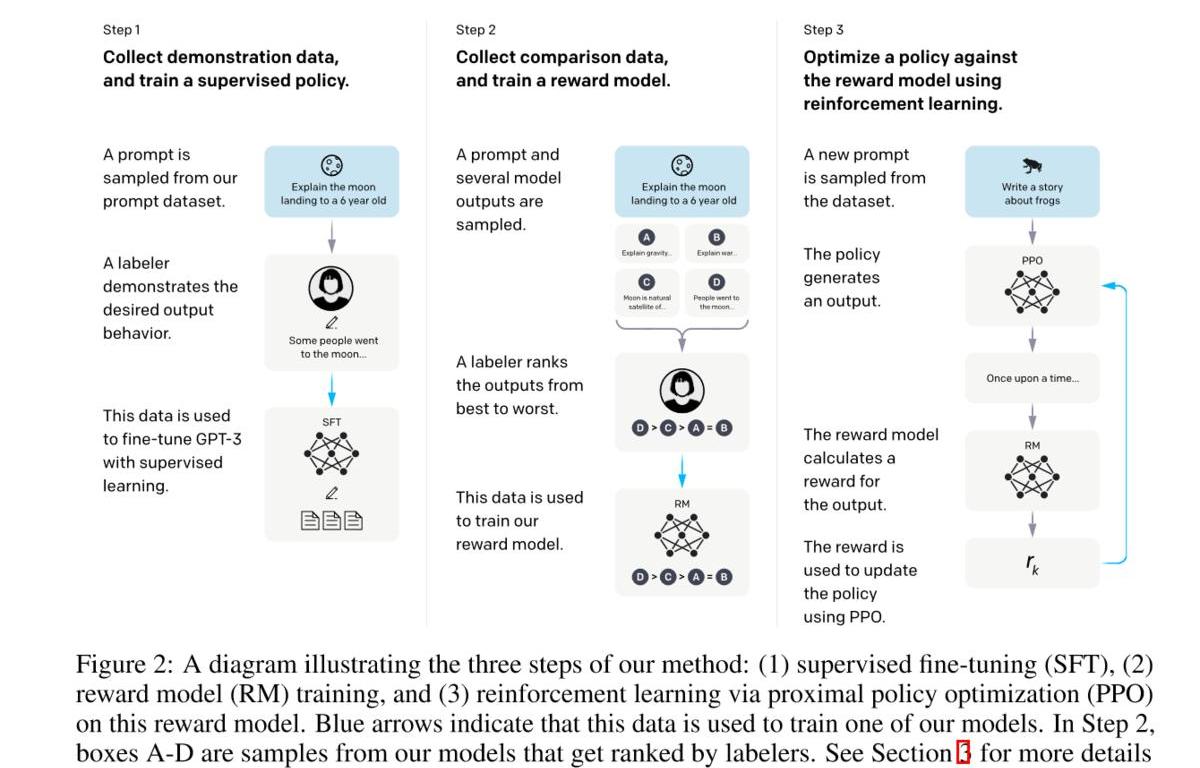
具體流程:
標注人員手寫(prompt,completion),然后進行SFT。這里主要是得到一個比較好的初始化模型,即模型至少能有一定的followinstruction的能力。收集模型輸出并進行打分,然后訓練一個rewardmodel。利用強化學習優化模型。
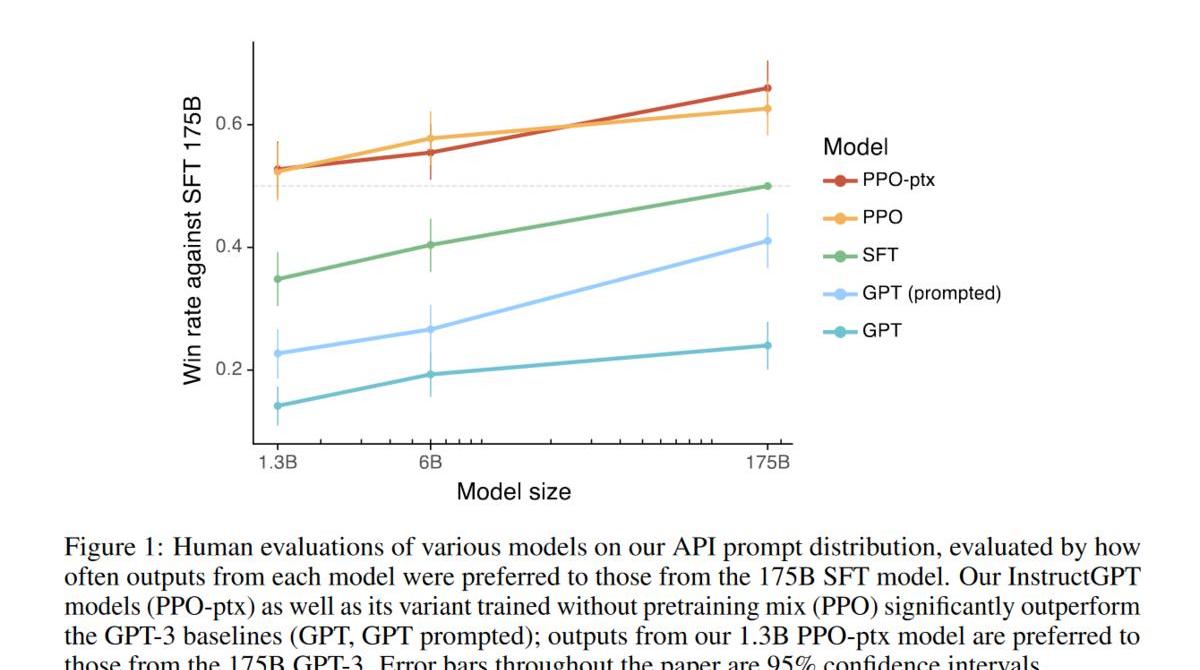
結果上看,效果顯著,1.3B就超過了之前175B的結果,而且隨著模型增大,結果也在上升。
Instruction-tuning
雖然fine-tuningwithhumanfeedback可以提升LLM在真實場景中用戶任務上(customertask)的性能,但是在學術任務上的性能卻會有所下降,即使OpenAI嘗試在RL中增加部分pretraindata同時增加LMloss來嘗試緩解這個問題,但是依然沒有解決。
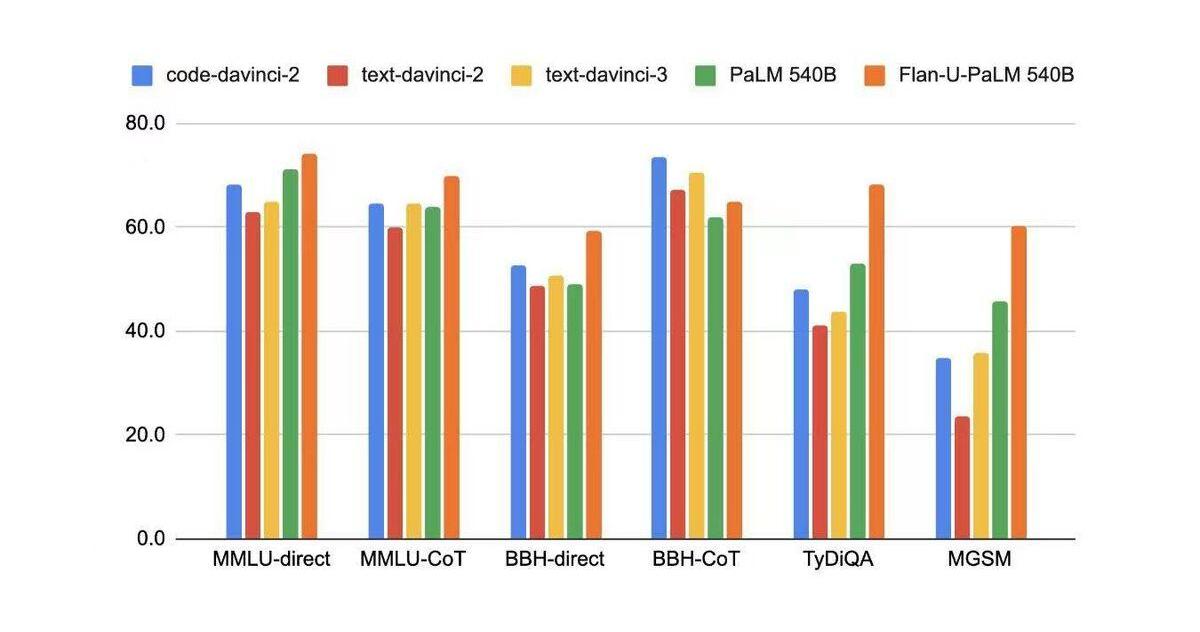
如何解決這個問題呢?辦法就是instruction-tuning:
利用academicNLPdata,為其構造對應的zero-shot/few-shot/CoTpattern,然后進行fine-tuning。
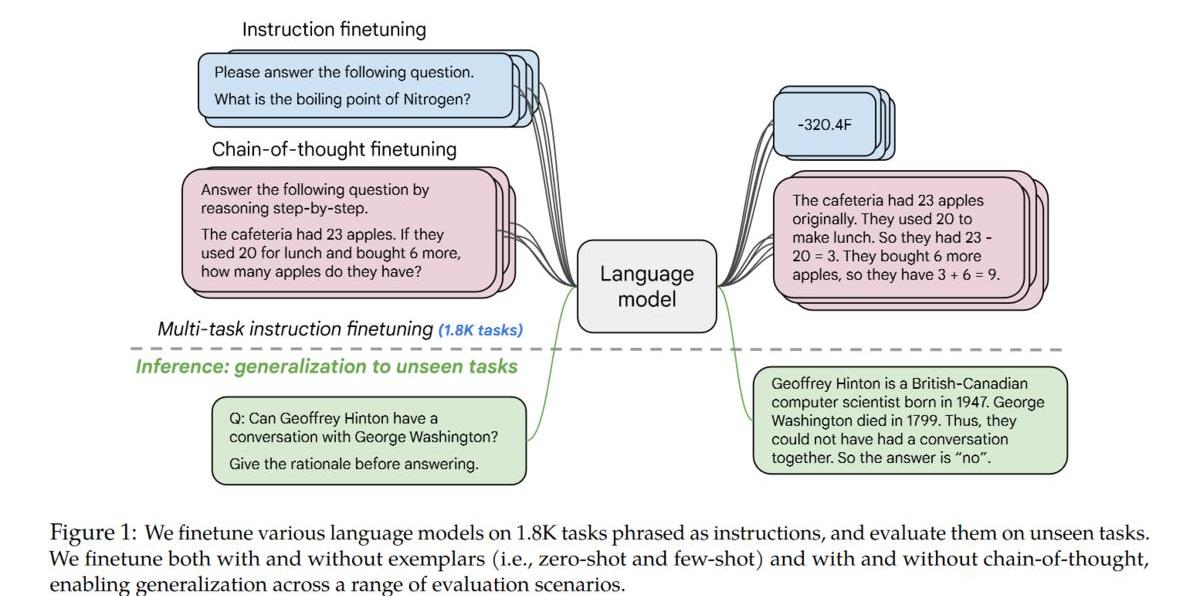
instruction-tuning效果顯著:
1.不光能提升大模型在academicNLPbenchmark上的性能,也能提升小模型上的性能;
2.能提升instruction-tuning時未見過的task上的性能;
3.能解鎖小模型上的CoT能力;
4.隨著任務數量的增加,對應的提升也會增加。
5.最重要的是也能提升LLM理解人類真實指令(followinstruction)的能力。
ps:雖然followhumaninstruction的能力提升了,但是跟InstructGPT誰的性能更好卻沒有對比,我猜應該是不如InstructGPT,實際應用/學術指標兩者依然是天枰的兩端。
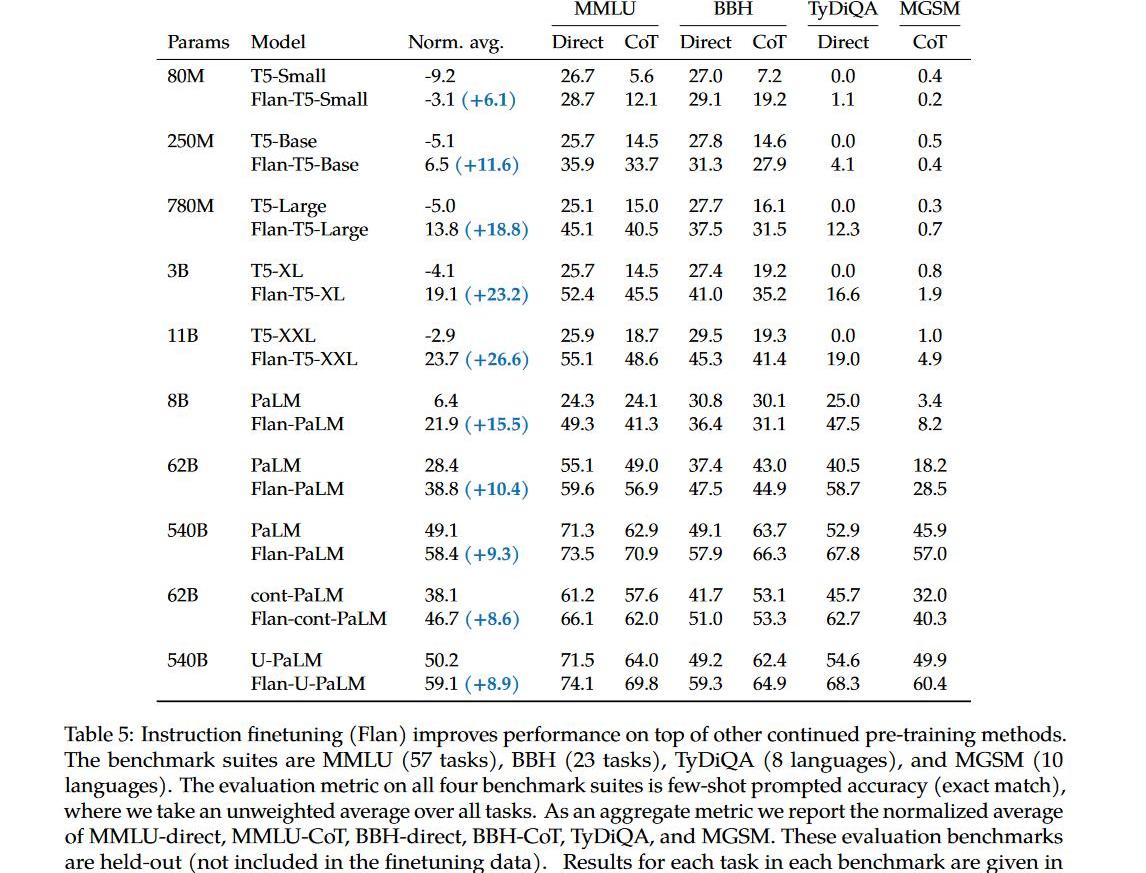
ChatGPT
那如何才能得到一個ChatGPT呢?
首先我們需要一個具備各種能力(潛力)的LLM,所以它要足夠大,訓練的足夠好。OpenAI大概率也是為此重新訓練了一個GPT-3模型,主要論據為:1.原始GPT-3175B和復現GPT-3的OPT-175B都沒有CoT能力,而GPT-3.5有CoT;2.原始的GPT-3的窗口只有2048,而其對應的是絕對位置編碼,現在的GPT-3.5最大窗口為8192。3.原始的GPT-3不能寫代碼,現在的可以。標注人員手寫符合人類的instructiondata(最好再混合一些academicinstructiondata,如:Flan),然后進行SFT,讓模型能更好的followinstruction。在對話場景下構造對應的instructiondata,進一步fine-tuningwithhumanfeedback(RLHF加速流程).
番外篇:
如何提升LLM在某個(組)特定任務上的性能
雖然LLM具有很多能力,但在實際場景中,我們可能只使用其中的一個或一組特定的能力,那如何提升LLM在某個特定任務上的性能呢?答案是:不確定。Fine-tuning
另一個思考就是構造大量的superviseddata直接fine-tuning。Gopher中針對對話任務做了對比實驗。Dialog-TunedGopher:fine-tuningGopheron5BtokensofcurateddialogdatasetfromMassiveWebDialog-PromptedGopher:few-shot

可以看到,fine-tuning后的模型性能與直接prompt的基本持平,并沒有帶來任何提升。
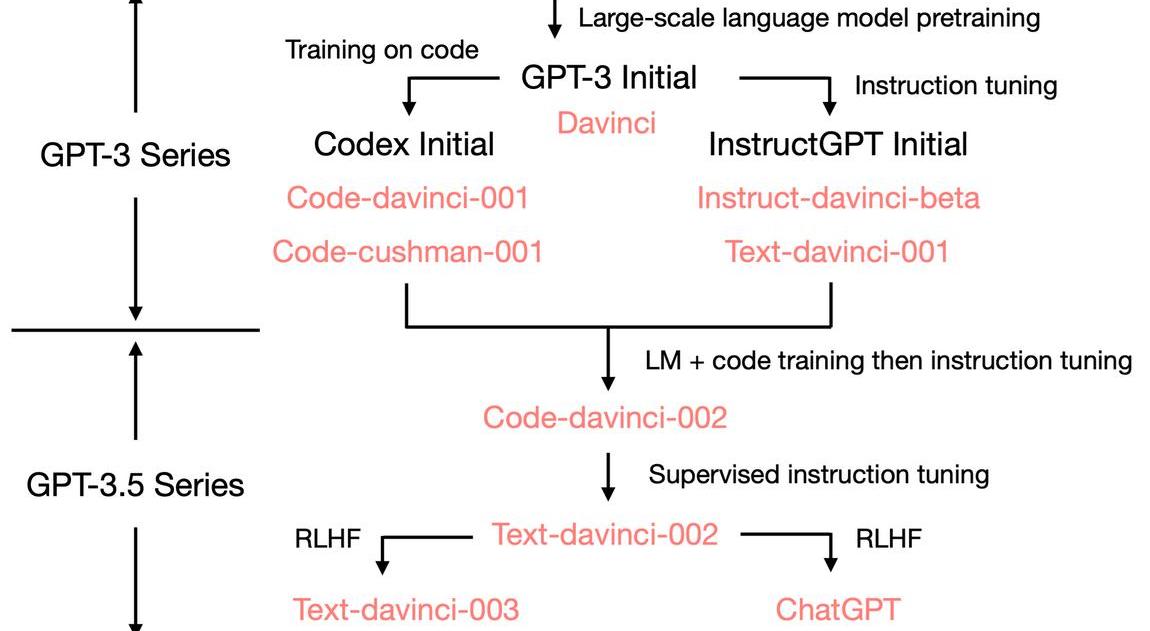
而Codex(GPT-3)針對代碼(code)做了fine-tuning,利用159Ggithubcodedata在GPT-3上進行fine-tuning,模型從基本無法處理代碼任務提升到當時的SOTA,甚至只需要12B就能達到從0到72%。
Fine-tuningwithhumanfeedback
之前我們提到通過RLHF可以進行alignment,讓模型更好的followinstruction。但是,這種對齊也會對模型的性能帶來一定的損失,又叫“對齊稅”(alignmenttax)。
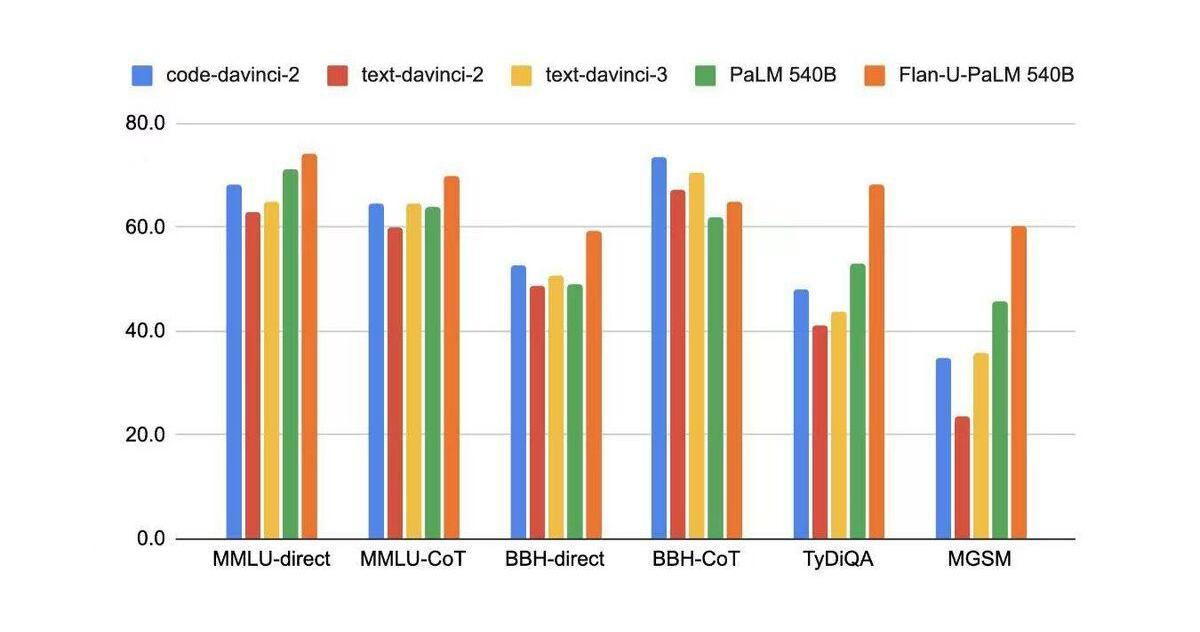
在學術NLP的benchmark上,code-davinci-2(basemodeloftext-davinci-2/text-davinci-3)的性能都是優于fine-tuning后的模型。
RAG
另外一種常用的方案就是RAG
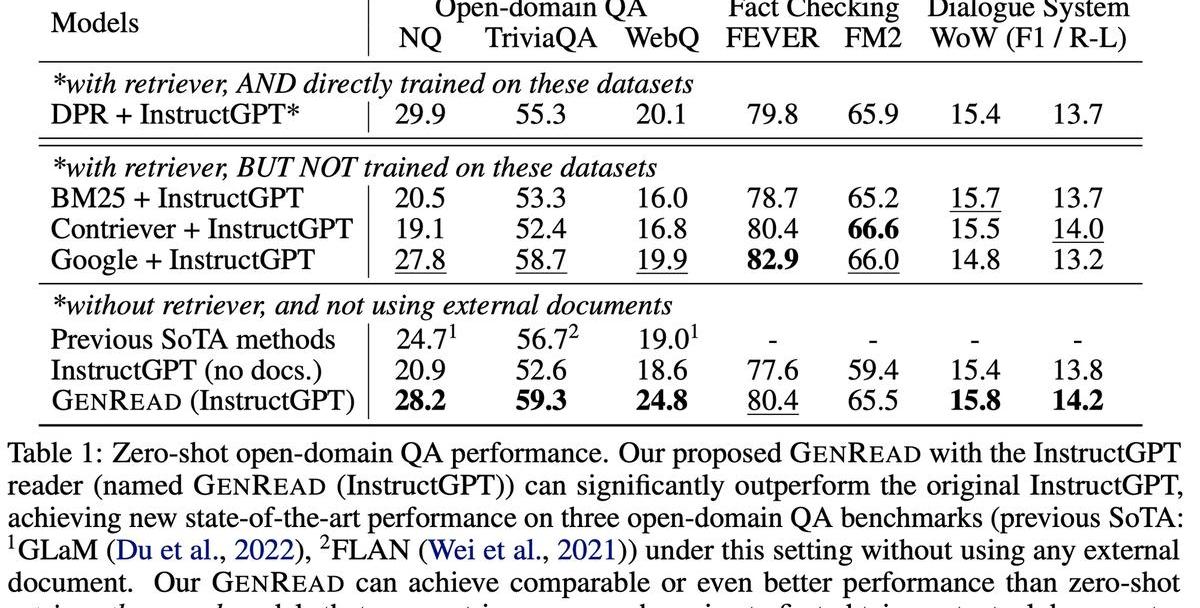
從實驗結果上看,RAG能帶來一定的提升,但是有限,不如prompt方法帶來的提升明顯。
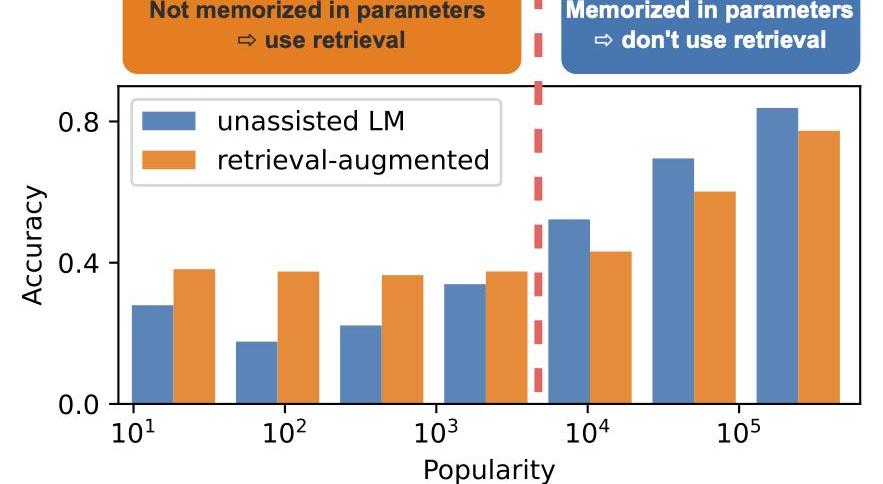
而另一個工作說,RAG是帶來提升還是下降跟別的因素有關,如在QA上,他可能跟對應實體的知名度(popularity)有關。LLM已經存儲了知名度高的實體信息,而RAG并不能帶來性能提升,反而由于retrieval到錯誤信息而導致性能下降,對于知名度低的實體通過RAG是能帶來顯著提升的。
PromptEngineering
在CoT出來之前,我們一度認為LLM可能需要繼續進行指數級的擴大才能線性提升其推理能力,而CoT的出現解鎖了模型的推理能力。所以,一個可能的方案可能是在特定任務上繼續尋找他的“般若波羅蜜”。不過筆者認為,這只是一個過渡期而非常態,隨著RLHF/Instruction-tuning等方法的發展,未來模型的使用一定會越來越簡單便捷。
Instruction-tuning
instruction-tuning已經證明了他的有效性,如flan-t5,flan-PaLM經過instruction-tuning后,其性能都得到了提升。
如何將能力從大模型遷移到小模型上
instruction-tuning,通過大量的instruction-data進行fine-tuning,可以解鎖小模型上對應的能力,但是相對大模型,通常還是有差距。壓縮模型,如有工作將OPT-175B蒸餾至75B,性能基本無損。。蒸餾,讓性能更好的大模型,生成大量的task-data,然后在小模型上進行fine-tuning,但是這可能需要生成很多data,鑒于LLM都比較貴,所以這個可能需要很多錢。
Tags:INGOMPPROROMwing幣創始人comp幣最新消息SafeMars ProtocolPrometheus Trading
U:加密離不開的資產 要說在加密世界中什么東西持有的人最多應用的最廣?比特幣?以太坊?都不是,而是穩定幣,我們大家一般都管他叫U。一個新人剛入圈想買幣一般會先做什么?交易所上買U.
1900/1/1 0:00:00MarsBitCryptoDaily2023年2月14日 一、?今日要聞 FTX已獲法院批準出售部分所投資產與子公司據TheBlock報道,FTX已獲得法院批準出售部分所投資產與子公司.
1900/1/1 0:00:00在這個RadiantCapitalTwitterSpaces中,來自抵押穩定幣協議VestaFinance的聯合創始人Mikey和營銷主管Vestator與來自RadiantCapital的Is.
1900/1/1 0:00:00數據結論前置 穩定幣對在去中心化交易所的交易量中占比?79%?。USDC?是?DEX?上交易量最大的穩定幣,占?60%?的主導地位.
1900/1/1 0:00:00市場觀點: 1、宏觀流動性 貨幣流動性趨緊。雖然本周鮑威爾講話鴿派,承認美國通脹開始下降。但是市場擔心超預期的強勁就業數據,會提升利率峰值至6%,比現有預期還高1個百分點.
1900/1/1 0:00:00NFT金融即將達到一個新的里程碑......接近50000NFT貸款!-NFT借貸平臺的競爭正在升溫 -用戶群集中 -尾部資產未得到充分利用探索目前頂級借款人如何使用貸款協議:1)NFT借貸平臺.
1900/1/1 0:00:00


