






 BTC/HKD+1.58%
BTC/HKD+1.58% ETH/HKD+1.29%
ETH/HKD+1.29% LTC/HKD+2.7%
LTC/HKD+2.7% DOT/HKD+3.52%
DOT/HKD+3.52% ADA/HKD+6.66%
ADA/HKD+6.66% SOL/HKD+4.83%
SOL/HKD+4.83% XRP/HKD+6.83%
XRP/HKD+6.83% DOGE/US+7.3%
DOGE/US+7.3%一夜之間,海外投資機構對于AI的關注度重回幾年前的高點,甚至蓋過了今年以來的Web3投資熱點。
那么AI與Web3的結合會有什么新火花?這篇CoinFund近期的深度研究文章向我們介紹了,AI+Web3有哪些用武之地。一起探索,一手抓住兩個學習要點。
簡單介紹
技術創新永無止境,人工智能尤其如此。在過去的幾年里,我們看到深度學習模型作為人工智能的先行者再次流行起來。這些由密集互連的節點層組成的模型也稱為神經網絡,這些節點相互傳遞信息,大致上模仿了人類大腦的構造。在2010年代初期,最先進的模型擁有數百萬個參數,用于特定情緒分析和分類的高度監督模型。當今最先進的型號,例如DreamStudio、GPT-3、DALL-E2和Imagen已經接近一萬億個參數,并且正在完成與人類工作相媲美的復雜甚至創造性的任務。以這篇文章的標題圖片或摘要為例,都是由人工智能制造的。我們才剛剛開始看到這些模型的社會和文化影響,因為它們塑造了我們學習新事物、相互互動和創造性地表達自己的方式。
然而,今天許多技術訣竅、關鍵數據集和訓練大型神經網絡的計算能力都是封閉的,并由谷歌和Meta等"科技巨頭?"公司把關。雖然GPT-NeoX、DALLE-mega和BLOOM等開源模型的復制品由StabilityAI、EleutherAI和HuggingFace等組織率先推出,但Web3有望進一步為開源人工智能提供更多動力。
數據:Binance.US市場份額下降至4.35%,月交易量現為16.9億美元:金色財經報道,Binance.US的交易量所占市場份額下降至4.35%,4月該交易所市場份額為16.05%。同時,Binance.US目前的月交易量為16.9億美元,低于3月的176.3億美元。[2023/6/19 21:46:16]
“人工智能的Web3基礎設施層可以引入開源開發、社區所有權和治理以及普及的元素,從而在開發這些新技術時創造新的模型和效率。”
此外,Web3的許多關鍵用例將通過采用人工智能技術得到加強。從生成藝術NFT到元宇宙景觀,AI將在Web3中找到許多用例。開源AI符合Web3的開放、去中心化和民主化的精神,代表了科技巨頭提供的AI的替代方案,而科技巨頭不可能很快變得開放。
基礎模型
基礎模型是在大量數據集上訓練的神經網絡,用于執行通常需要智能人類行為的任務。這些模型已經創造了一些令人印象深刻的結果。
OpenAI的GPT-3、Google的LaMDA和Nvidia的Megatron-TuringNLG等語言模型具有理解和產生自然語言、總結和合成文本,甚至編寫計算機代碼的能力。
DALLE-2是OpenAI的文本到圖像擴散模型,可以從書面文本中生成獨特的圖像。谷歌的人工智能部門DeepMind已經產生了競爭模型,包括PaLM,一個540B參數的語言模型,以及Imagen,它自己的圖像生成模型,在DrawBench和COCOFID基準上優于DALLE-2。Imagen不僅產生的效果更逼真還具有拼寫能力。
Sturdy Finance向其攻擊者提供10萬美元賞金以要求資金歸還:6月13日消息,借貸協議Sturdy Finance創始人Sam Forman在今天早些時候發布的一條推文中確認,他的團隊已經向未知攻擊者的地址發送了一條鏈上信息。這條消息向犯罪者提供了10萬美元的賞金,要求其將被盜資金歸還到Sturdy擁有的指定地址,并補充說,如果資金歸還,團隊將主張不提出刑事指控。
此前消息,Sturdy Finance攻擊者從Tornado Cash獲得初始資金進行合約攻擊,盜取了442枚ETH。[2023/6/13 21:34:06]
谷歌的AlphaGo?等強化學習模型已經擊敗了人類圍棋世界冠軍,同時發現了在該游戲三千年歷史中從未出現過的新策略和下棋技巧。
BigTech處于創新的最前沿,建立復雜基礎模型的競賽已經開始。盡管該領域的進步令人興奮,但有一個關鍵主題值得我們關注。在過去的十年中,隨著人工智能模型變得越來越復雜,它們也越來越不向公眾開放。
科技巨頭正在大力投資于生產此類模型并將數據和代碼作為專有技術保留下來,同時通過其模型訓練和計算的規模經濟優勢來保持其競爭護城河。對于任何第三方來說,生成基礎模型都是一個資源密集型過程,具有三個主要瓶頸:數據、計算和貨幣化。
在這個方向,我們看到了Web3在解決其中一些問題的早期進展。
此前向幣安轉入3500萬枚USDT的巨鯨再度轉入1200萬枚USDT:6月12日消息,據Lookonchain監測顯示,此前在Aave抵押2.5萬枚stETH借出3500萬枚USDT,并將借出的USDT轉入幣安的巨鯨地址,再次在Aave抵押1.2萬枚stETH借出1200萬枚USDT并轉入幣安。[2023/6/12 21:31:56]
數據集生產可以通過Web3所有權進行匯總
標記數據集對于構建有效模型至關重要。人工智能系統通過歸納數據集內的示例進行學習,并隨著時間的推移不斷改進訓練。然而,高質量的數據集匯編和標記需要專門的知識和處理,以及計算資源。專門的內部數據團隊來處理大型專有數據集和IP系統,以訓練他們的模型,并且幾乎沒有動力開放對其數據的生產或分發的訪問。已經有一些社區正在向全球研究者社區開放和訪問模型訓練。
1.CommonCrawl,一個十年互聯網數據的公共存儲庫,可用于一般培訓。
2.LAION是一個非營利組織,旨在向公眾提供大規模機器學習模型和數據集,并發布了LAION5B,這是一個58.5億經過CLIP過濾的圖像-文本對數據集,一經發布就成為世界上最大的公開訪問的圖像-文本數據集。
3.EleutherAI是一個分散的集體,發布了最大的開源文本數據集之一,稱為ThePile。ThePile是一個825.18GiB的英語語言數據集,用于使用22個不同數據源的語言建模。
鮑威爾:無法想象我們會在沒有國會批準的情況下推進央行數字貨幣:6月23日消息,美聯儲主席鮑威爾表示,無法想象我們會在沒有國會批準的情況下推進央行數字貨幣。[2022/6/24 1:27:57]
目前,這些社區是以非正式的方式組織起來的,并大量依靠廣大志愿者的貢獻。為了激勵社區貢獻,代幣激勵可以作為一種機制來創建開源的數據集。?代幣可以根據貢獻來發放,比如標記一個大型的文本-圖像數據集;并且DAO的存在可以驗證此類激勵聲明。最終,大型模型可以從一個公共池中發行代幣,并且基于所述模型構建的產品的下游收入可以累積到代幣價值中。這樣一來,數據集貢獻者可以通過他們的代幣持有大型模型的股份,而研究人員將能夠在開放中對構建的資源進行貨幣化。編譯構建良好的開源數據集對于擴大大型模型的研究可訪問性和提高模型性能至關重要。可以通過增加不同類型圖像的大小和過濾器來擴展文本-圖像數據集,以獲得更精細的結果。非英語數據集將需要用于訓練非英語人群可以使用的自然語言模型。逐漸地,我們可以使用Web3更快、更公開地實現這些結果。
隨著時間的推移,計算將轉移到去中心化網絡訓練大規模神經網絡所需的計算是基礎模型中最大的瓶頸之一。在過去十年中,訓練AI模型的計算需求每3、4個月翻一番。在此期間,人工智能模型已經從圖像識別到使用強化學習算法,再到在戰略游戲中擊敗人類冠軍,以及利用轉化器訓練語言模型。例如,OpenAI的GPT-3有1750億個參數,訓練時間為3640petaFLOPS-day包括一天里每秒執行1015個神經網絡操作,或者總共大約1020個操作?)。在世界上最快的超級計算機上,這需要兩周時間,而標準筆記本電腦需要一千年以上的時間來計算。隨著模型規模的不斷增長,計算仍然是該領域發展的瓶頸。
今日恐慌與貪婪指數為8,恐慌程度為極度恐慌:金色財經報道,今日恐慌與貪婪指數為8(昨日為11),恐慌程度較昨日上升,等級仍為極度恐慌。
注:恐慌指數閾值為0-100,包含指標:波動性(25%)+市場交易量(25%)+社交媒體熱度(15%)+市場調查(15%)+比特幣在整個市場中的比例(10%)+谷歌熱詞分析(10%)。[2022/6/14 4:24:45]
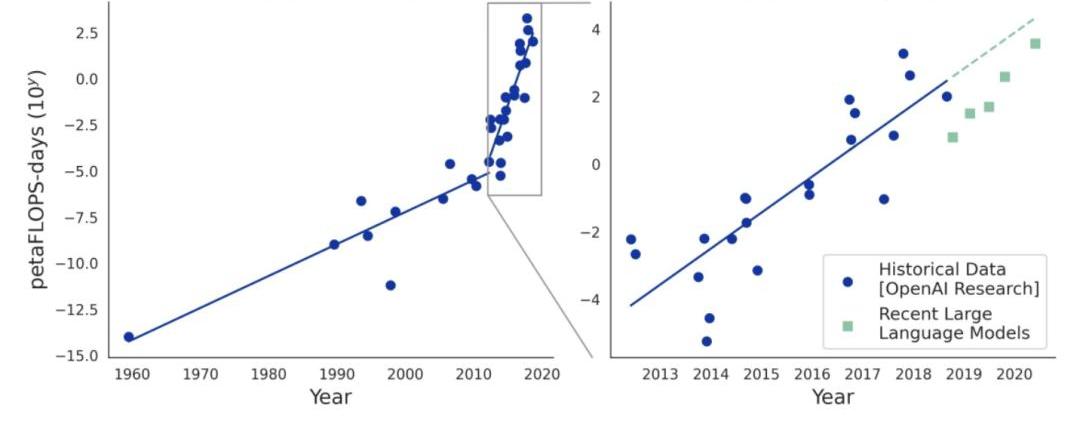
AI超級計算機需要經過優化的特定硬件,以執行訓練神經網絡所需的數學運算,例如圖形處理單元(GPU)或專用集成電路(ASIC)。如今,針對此類計算優化的大多數硬件都由少數寡頭云服務提供商控制,例如GoogleCloud、AmazonWebServices、MicrosoftAzure和IBMCloud。
這是我們看到通過公共的、開放的網絡進行去中心化的計算分配的下一個主要交叉點。去中心化治理可用于資助和分配資源以培訓社區驅動的項目。此外,去中心化的市場模型可以跨地域公開訪問,這樣任何研究人員都可以訪問計算資源。想象一個通過發行代幣來眾籌模型訓練的賞金系統。成功的眾籌將為其模型獲得優先計算權,并在需求量大的地方推動創新。例如,如果DAO有很大的需求,要制作一個西班牙語或印地語的GPT模型系列是由OpenAI提出的非常強大的預訓練語言模型,這一系列的模型可以在非常復雜的NLP任務中取得非常驚艷的效果,例如文章生成,代碼生成,機器翻譯,Q&A等,而完成這些任務并不需要有監督學習進行模型微調。)以服務于更大范圍的人口,那么研究就可以集中在這個領域。
像GenSyn這樣的公司已經在努力推出協議,以激勵和協調替代、經濟高效和基于云的硬件訪問,以進行深度學習計算。隨著時間的推移,在我們共同探索人工智能的前沿,使用Web3基礎設施構建的共享、分散的全球計算網絡將變得更具成本效益,以擴展和更好地為我們服務。
開放獲取和產品協調
數據集和計算將使這篇論文變得可能:開源人工智能模型。在過去的幾年里,大型模型變得越來越私人化,因為制作這些模型所需的資源投資已經推動項目成為閉源的了。
以OpenAI為例。OpenAI成立于2015年,是一家非營利性研究實驗室,其使命是為全人類的利益生產通用人工智能,這與當時的人工智能領導者谷歌和Facebook形成鮮明對比。隨著時間的推移,激烈的競爭和資金壓力逐漸侵蝕了透明度和開源代碼的理想,因為OpenAI轉向營利性模式并與微軟簽署了10億美元的大規模商業協議。此外,最近的爭議圍繞著他們的文本到圖像模型DALLE-2,因為它的普遍審查制度.訪問這些模型的私人測試版對西方用戶具有隱含的地理偏見,這導致切斷全球大部分人口與這些模型的交互和通知。
這不是人工智能應該傳播的方式:由幾家大型科技公司看守、監管和保護。與區塊鏈的情況一樣,新技術應該盡可能公平地應用,這樣它的好處就不會集中在少數可以使用的人身上。人工智能的復合進展應在不同行業、地域和社區之間公開利用,共同發現最具吸引力的使用案例,并就人工智能的公平使用達成共識。保持基礎模型的開源可以確保防止審查,并在公眾視野下仔細監測偏見。
借助通用基礎模型的代幣模型,將有可能聚集更多的貢獻者,他們可以在發布代碼開源的同時將其工作貨幣化。像OpenAI這樣以開源論文為基礎建立的項目不得不轉向一個獨立的資助公司,以競爭人才和資源。Web3允許開源項目在經濟上同樣有利可圖,并進一步與由BigTech私有投資領導的項目競爭。此外,在開源模型之上構建產品的創新者可以放心地構建,因為底層人工智能是透明的。其下游效應將是新型人工智能用例的快速采用和上市。在Web3領域,這包括對智能合約漏洞進行預測分析的安全應用程序,可用于鑄造NFT和創建元界景觀的圖像生成器,可存在于鏈上以保留個人所有權的數字AI個性等等。
結論
人工智能是當今發展最快的技術之一,將對我們整個社會產生巨大影響。今天,該領域由BigTech主導,因為對人才、數據和計算的金融投資為開源開發創造了重要的護城河。Web3整合到AI的基礎設施層將是關鍵步驟,確保人工智能系統以公平、開放和可訪問的方式構建。我們已經看到開放模型在Twitter和HuggingFace等開放空間中采取快速、公共創新的位置,而加密貨幣可以推動這些努力超前發展。
以下是CoinFund投資團隊在AI和crypto的交叉點上所尋找的項目:
1.以開放式人工智能為核心的團隊
2.管理公共資源以幫助構建AI模型的社區
3.利用人工智能將創造力、安全性和創新帶入主流應用的產品
責任編輯:MK
撰文:Vivian 不管是對于希望入門NFT世界的愛好者,還是對于NFT領域的分析專家,NFT聚合交易將為用戶打開了一扇通往NFT未來的大門.
1900/1/1 0:00:00NFT聚合平臺如何促進行業發展?早在2016-2018年,以?OpenSea,MakersPlace,SuperRare?為代表的第一批NFT交易市場橫空出世.
1900/1/1 0:00:00在越來越快的行業周期循環中,我們見證了一批又一批新老玩家的登場與退場。依托于上一波牛市的熱度和以太坊生態溢出的效應,那些埋伏了一輪熊市的公鏈新秀得以嶄露頭角,并且作為市場不斷膨脹預期的「落腳點」.
1900/1/1 0:00:00眾所周知,對于圈外人來說,DeFi協議很難使用。包括助記詞、公鑰、私鑰等這些概念,對于常人來說都很難理解,更別說我們的父母輩。 所以為了實現DeFi的大規模采用,我們需要做得更好.
1900/1/1 0:00:00今日早間,SushiSwap新任“主廚”JaredGrey在推特上遭到了yannickcrypto.eth等多位網友的集體聲討.
1900/1/1 0:00:00簡介 過去幾個月是NFT的熊市,采訪了身邊2個還持續在NFT賺錢的朋友,有關于藍籌、藝術品投資、新項目選擇和digi、Artgobbler投資的討論,回顧公眾號前3位的采訪者.
1900/1/1 0:00:00


